 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeeding up Policy Simulation in Supply Chain RL
Jun 04, 2024Simulating a single trajectory of a dynamical system under some state-dependent policy is a core bottleneck in policy optimization algorithms. The many inherently serial policy evaluations that must be performed in a single simulation constitute the bulk of this bottleneck. To wit, in applying policy optimization to supply chain optimization (SCO) problems, simulating a single month of a supply chain can take several hours. We present an iterative algorithm for policy simulation, which we dub Picard Iteration. This scheme carefully assigns policy evaluation tasks to independent processes. Within an iteration, a single process evaluates the policy only on its assigned tasks while assuming a certain 'cached' evaluation for other tasks; the cache is updated at the end of the iteration. Implemented on GPUs, this scheme admits batched evaluation of the policy on a single trajectory. We prove that the structure afforded by many SCO problems allows convergence in a small number of iterations, independent of the horizon. We demonstrate practical speedups of 400x on large-scale SCO problems even with a single GPU, and also demonstrate practical efficacy in other RL environments.
Synthetically Controlled Bandits
Feb 14, 2022
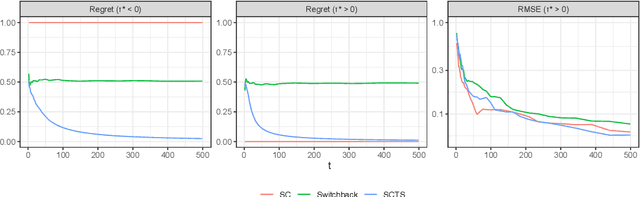
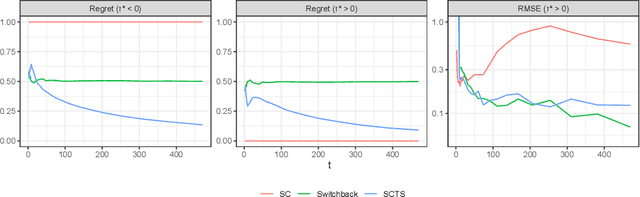
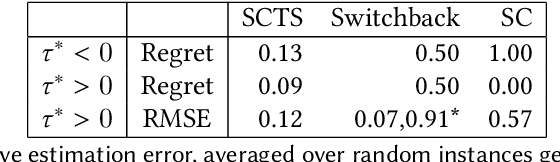
This paper presents a new dynamic approach to experiment design in settings where, due to interference or other concerns, experimental units are coarse. `Region-split' experiments on online platforms are one example of such a setting. The cost, or regret, of experimentation is a natural concern here. Our new design, dubbed Synthetically Controlled Thompson Sampling (SCTS), minimizes the regret associated with experimentation at no practically meaningful loss to inferential ability. We provide theoretical guarantees characterizing the near-optimal regret of our approach, and the error rates achieved by the corresponding treatment effect estimator. Experiments on synthetic and real world data highlight the merits of our approach relative to both fixed and `switchback' designs common to such experimental settings.