 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenetic algorithms for multi-omic feature selection: a comparative study in cancer survival analysis
Mar 31, 2026Multi-omic datasets offer opportunities for improved biomarker discovery in cancer research, but their high dimensionality and limited sample sizes make identifying compact and effective biomarker panels challenging. Feature selection in large-scale omics can be efficiently addressed by combining machine learning with genetic algorithms, which naturally support multi-objective optimization of predictive accuracy and biomarker set size. However, genetic algorithms remain relatively underexplored for multi-omic feature selection, where most approaches concatenate all layers into a single feature space. To address this limitation, we introduce Sweeping*, a multi-view, multi-objective algorithm alternating between single- and multi-view optimization. It employs a nested single-view multi-objective optimizer, and for this study we use the genetic algorithm NSGA3-CHS. It first identifies informative biomarkers within each layer, then jointly evaluates cross-layer interactions; these multi-omic solutions guide the next single-view search. Through repeated sweeps, the algorithm progressively identifies compact biomarker panels capturing cross-modal complementary signals. We benchmark five Sweeping* strategies, including hierarchical and concatenation-based variants, using survival prediction on three TCGA cohorts. Each strategy jointly optimizes predictive accuracy and set size, measured via the concordance index and root-leanness. Overall performance and estimation error are assessed through cross hypervolume and Pareto delta under 5-fold cross-validation. Our results show that Sweeping* can improve the accuracy-complexity trade-off when sufficient survival signal is present and that integrating omic layers can enhance survival prediction beyond clinical-only models, although benefits remain cohort-dependent.
Optimizing Feature Selection for Binary Classification with Noisy Labels: A Genetic Algorithm Approach
Jan 12, 2024
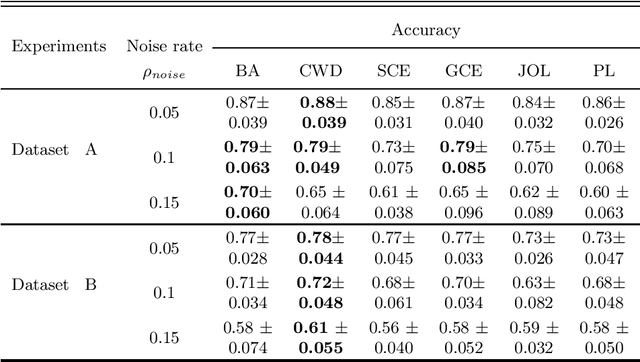
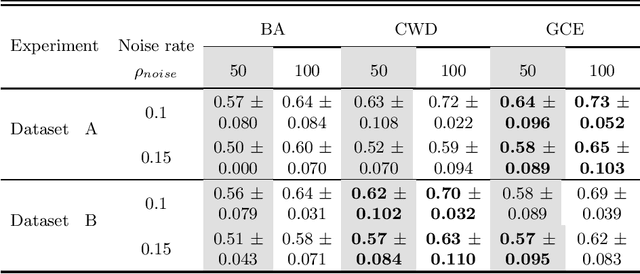
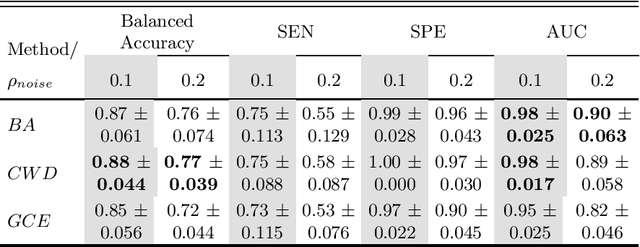
Feature selection in noisy label scenarios remains an understudied topic. We propose a novel genetic algorithm-based approach, the Noise-Aware Multi-Objective Feature Selection Genetic Algorithm (NMFS-GA), for selecting optimal feature subsets in binary classification with noisy labels. NMFS-GA offers a unified framework for selecting feature subsets that are both accurate and interpretable. We evaluate NMFS-GA on synthetic datasets with label noise, a Breast Cancer dataset enriched with noisy features, and a real-world ADNI dataset for dementia conversion prediction. Our results indicate that NMFS-GA can effectively select feature subsets that improve the accuracy and interpretability of binary classifiers in scenarios with noisy labels.
DOSA-MO: Dual-stage Optimizer for Systematic overestimation Adjustment in Multi-Objective problems improves biomarker discovery
Dec 27, 2023The challenge in biomarker discovery and validation using machine learning from omics data lies in the abundance of molecular features but scarcity of samples. Most machine learning-based feature selection methods necessitate of hyperparameter tuning, typically performed by evaluating numerous alternatives on a validation set. Every evaluation has a performance estimation error and when the selection takes place between many models the best ones are almost certainly overestimated. Biomarker identification is a typical multi-objective problem with trade-offs between the predictive ability and the parsimony in the number of molecular features. Genetic algorithms are a popular tool for multi-objective optimization but they evolve numerous solutions and are prone to overestimation. Methods have been proposed to reduce the overestimation after a model has already been selected in single-objective problems, but to the best of our knowledge no algorithm existed that was capable of reducing the overestimation during the optimization, leading to a better model selection, or that had been applied in the more general domain of multi-objective problems. We propose DOSA-MO, a novel multi-objective optimization wrapper algorithm that learns how the original estimation, its variance, and the feature set size of the solutions predict the overestimation, and adjusts the expectation of the performance during the optimization, improving the composition of the solution set. We verify that DOSA-MO improves the performance of a state-of-the-art genetic algorithm on left-out or external sample sets, when predicting cancer subtypes and/or patient overall survival, using three transcriptomics datasets for kidney and breast cancer.
Multi-Objective Genetic Algorithm for Multi-View Feature Selection
May 26, 2023Multi-view datasets offer diverse forms of data that can enhance prediction models by providing complementary information. However, the use of multi-view data leads to an increase in high-dimensional data, which poses significant challenges for the prediction models that can lead to poor generalization. Therefore, relevant feature selection from multi-view datasets is important as it not only addresses the poor generalization but also enhances the interpretability of the models. Despite the success of traditional feature selection methods, they have limitations in leveraging intrinsic information across modalities, lacking generalizability, and being tailored to specific classification tasks. We propose a novel genetic algorithm strategy to overcome these limitations of traditional feature selection methods for multi-view data. Our proposed approach, called the multi-view multi-objective feature selection genetic algorithm (MMFS-GA), simultaneously selects the optimal subset of features within a view and between views under a unified framework. The MMFS-GA framework demonstrates superior performance and interpretability for feature selection on multi-view datasets in both binary and multiclass classification tasks. The results of our evaluations on three benchmark datasets, including synthetic and real data, show improvement over the best baseline methods. This work provides a promising solution for multi-view feature selection and opens up new possibilities for further research in multi-view datasets.