 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJAF: Judge Agent Forest
Jan 29, 2026Judge agents are fundamental to agentic AI frameworks: they provide automated evaluation, and enable iterative self-refinement of reasoning processes. We introduce JAF: Judge Agent Forest, a framework in which the judge agent conducts joint inference across a cohort of query--response pairs generated by a primary agent, rather than evaluating each in isolation. This paradigm elevates the judge from a local evaluator to a holistic learner: by simultaneously assessing related responses, the judge discerns cross-instance patterns and inconsistencies, whose aggregate feedback enables the primary agent to improve by viewing its own outputs through the judge's collective perspective. Conceptually, JAF bridges belief propagation and ensemble-learning principles: overlapping in-context neighborhoods induce a knowledge-graph structure that facilitates propagation of critique, and repeated, randomized evaluations yield a robust ensemble of context-sensitive judgments. JAF can be instantiated entirely via ICL, with the judge prompted for each query using its associated primary-agent response plus a small, possibly noisy set of peer exemplars. While kNN in embedding space is a natural starting point for exemplars, this approach overlooks categorical structure, domain metadata, or nuanced distinctions accessible to modern LLMs. To overcome these limitations, we develop a flexible locality-sensitive hashing (LSH) algorithm that learns informative binary codes by integrating semantic embeddings, LLM-driven hash predicates, supervision from categorical labels, and relevant side information. These hash codes support efficient, interpretable, and relation-aware selection of diverse exemplars, and further optimize exploration of CoT reasoning paths. We validate JAF with an empirical study on the demanding task of cloud misconfigs triage in large-scale cloud environments.
Broken News: Making Newspapers Accessible to Print-Impaired
Jun 23, 2022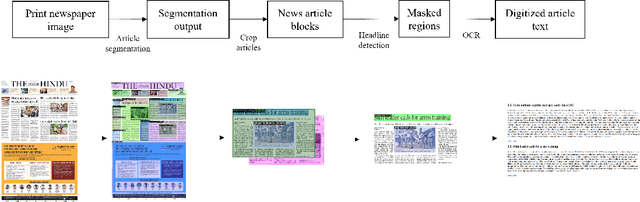
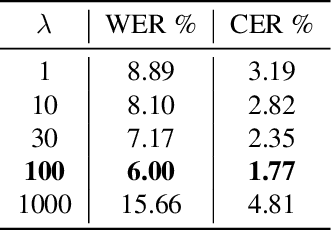

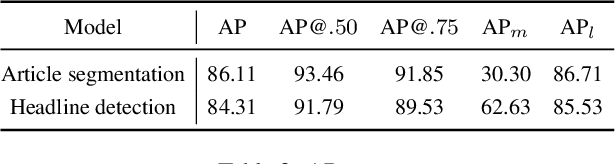
Accessing daily news content still remains a big challenge for people with print-impairment including blind and low-vision due to opacity of printed content and hindrance from online sources. In this paper, we present our approach for digitization of print newspaper into an accessible file format such as HTML. We use an ensemble of instance segmentation and detection framework for newspaper layout analysis and then OCR to recognize text elements such as headline and article text. Additionally, we propose EdgeMask loss function for Mask-RCNN framework to improve segmentation mask boundary and hence accuracy of downstream OCR task. Empirically, we show that our proposed loss function reduces the Word Error Rate (WER) of news article text by 32.5 %.
Unsupervised Representation Learning of DNA Sequences
Jun 07, 2019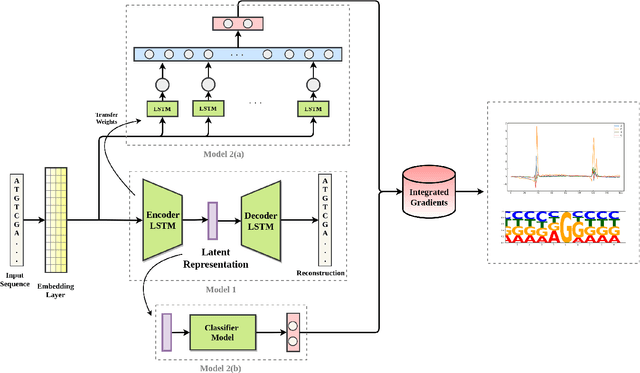


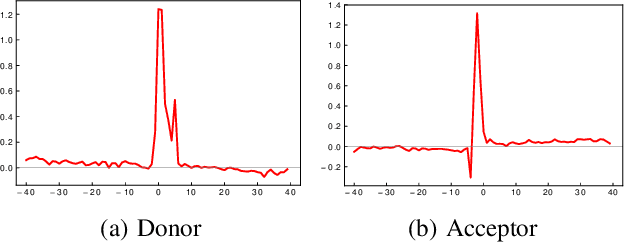
Recently several deep learning models have been used for DNA sequence based classification tasks. Often such tasks require long and variable length DNA sequences in the input. In this work, we use a sequence-to-sequence autoencoder model to learn a latent representation of a fixed dimension for long and variable length DNA sequences in an unsupervised manner. We evaluate both quantitatively and qualitatively the learned latent representation for a supervised task of splice site classification. The quantitative evaluation is done under two different settings. Our experiments show that these representations can be used as features or priors in closely related tasks such as splice site classification. Further, in our qualitative analysis, we use a model attribution technique Integrated Gradients to infer significant sequence signatures influencing the classification accuracy. We show the identified splice signatures resemble well with the existing knowledge.
Deep Face Quality Assessment
Nov 11, 2018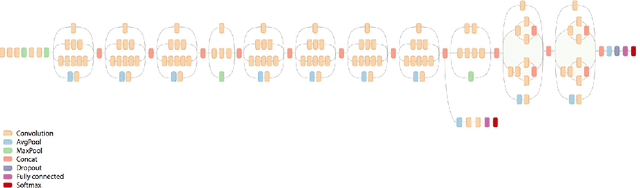


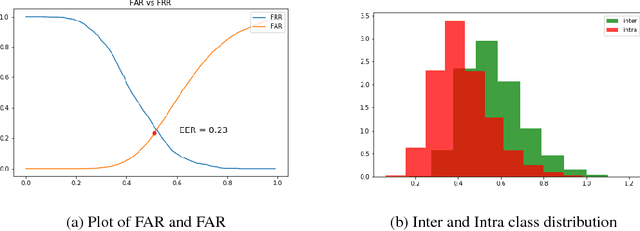
Face image quality is an important factor in facial recognition systems as its verification and recognition accuracy is highly dependent on the quality of image presented. Rejecting low quality images can significantly increase the accuracy of any facial recognition system. In this project, a simple approach is presented to train a deep convolutional neural network to perform end-to-end face image quality assessment. The work is done in 2 stages : First, generation of quality score label and secondly, training a deep convolutional neural network in a supervised manner to predict quality score between 0 and 1. The generation of quality labels is done by comparing the face image with a template of best quality images and then evaluating the normalized score based on the similarity.
An Interval Type-2 Fuzzy Approach to Automatic Generation for Histogram Specification
May 06, 2018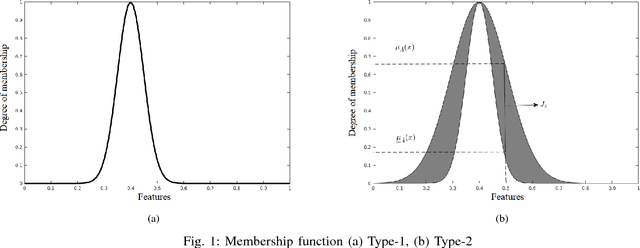
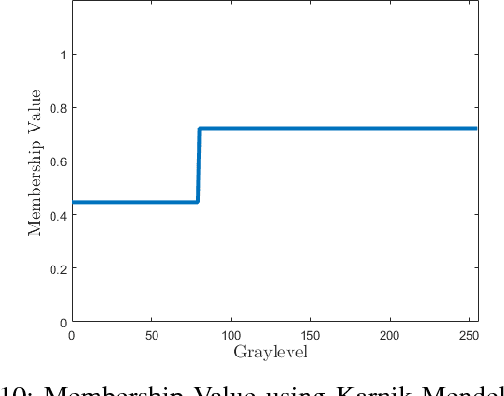
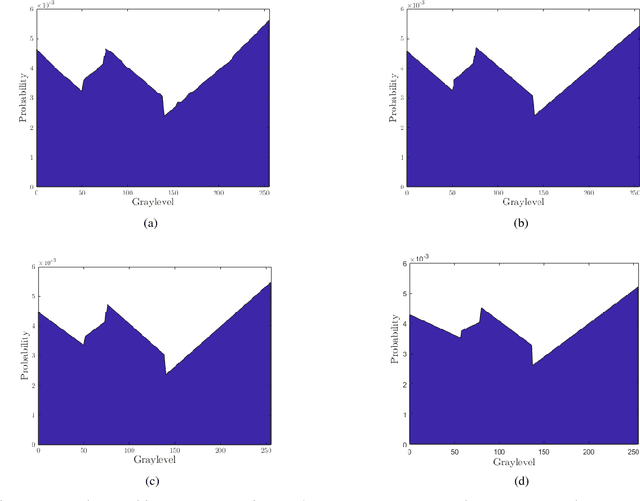

Image enhancement plays an important role in several application in the field of computer vision and image processing. Histogram specification (HS) is one of the most widely used techniques for contrast enhancement of an image, which requires an appropriate probability density function for the transformation. In this paper, we propose a fuzzy method to find a suitable PDF automatically for histogram specification using interval type - 2 (IT2) fuzzy approach, based on the fuzzy membership values obtained from the histogram of input image. The proposed algorithm works in 5 stages which includes - symmetric Gaussian fitting on the histogram, extraction of IT2 fuzzy membership functions (MFs) and therefore, footprint of uncertainty (FOU), obtaining membership value (MV), generating PDF and application of HS. We have proposed 4 different methods to find membership values - point-wise method, center of weight method, area method, and karnik-mendel (KM) method. The framework is sensitive to local variations in the histogram and chooses the best PDF so as to improve contrast enhancement. Experimental validity of the methods used is illustrated by qualitative and quantitative analysis on several images using the image quality index - Average Information Content (AIC) or Entropy, and by comparison with the commonly used algorithms such as Histogram Equalization (HE), Recursive Mean-Separate Histogram Equalization (RMSHE) and Brightness Preserving Fuzzy Histogram Equalization (BPFHE). It has been found out that on an average, our algorithm improves the AIC index by 11.5% as compared to the index obtained by histogram equalisation.