 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Based Model for Breast Cancer Subtype Classification
Nov 09, 2021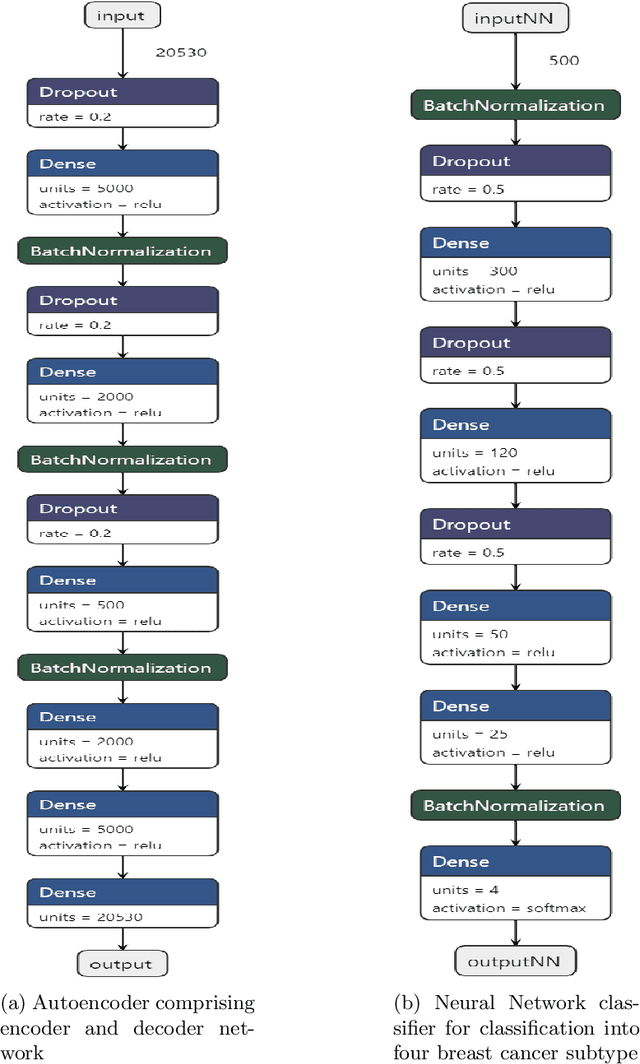
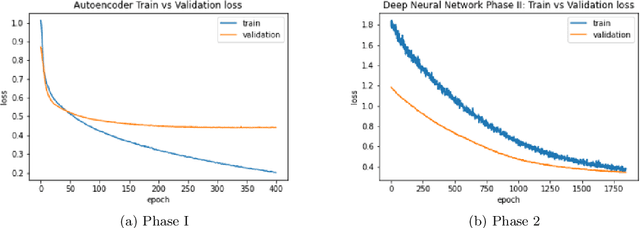
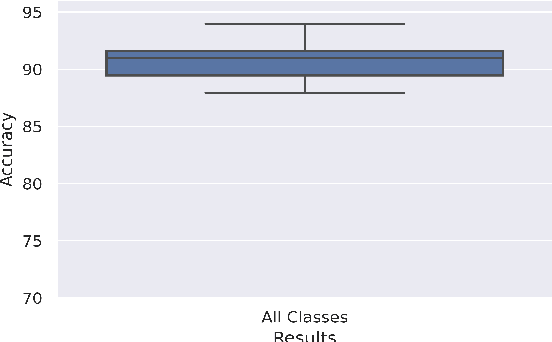
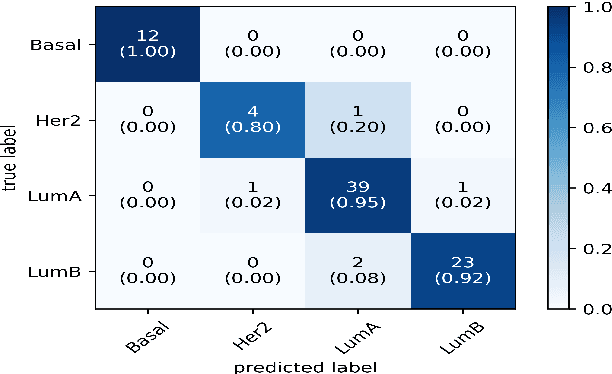
Breast cancer has long been a prominent cause of mortality among women. Diagnosis, therapy, and prognosis are now possible, thanks to the availability of RNA sequencing tools capable of recording gene expression data. Molecular subtyping being closely related to devising clinical strategy and prognosis, this paper focuses on the use of gene expression data for the classification of breast cancer into four subtypes, namely, Basal, Her2, LumA, and LumB. In stage 1, we suggested a deep learning-based model that uses an autoencoder to reduce dimensionality. The size of the feature set is reduced from 20,530 gene expression values to 500 by using an autoencoder. This encoded representation is passed to the deep neural network of the second stage for the classification of patients into four molecular subtypes of breast cancer. By deploying the combined network of stages 1 and 2, we have been able to attain a mean 10-fold test accuracy of 0.907 on the TCGA breast cancer dataset. The proposed framework is fairly robust throughout 10 different runs, as shown by the boxplot for classification accuracy. Compared to related work reported in the literature, we have achieved a competitive outcome. In conclusion, the proposed two-stage deep learning-based model is able to accurately classify four breast cancer subtypes, highlighting the autoencoder's capacity to deduce the compact representation and the neural network classifier's ability to correctly label breast cancer patients.