 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomarker Gene Identification for Breast Cancer Classification
Nov 29, 2021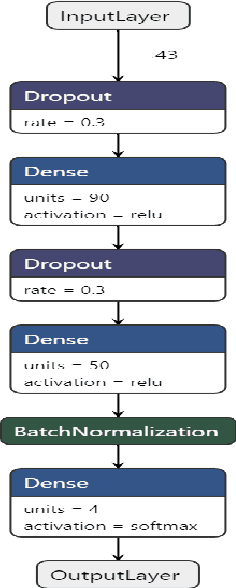

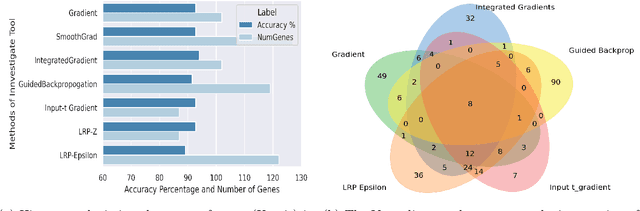
BACKGROUND: Breast cancer has emerged as one of the most prevalent cancers among women leading to a high mortality rate. Due to the heterogeneous nature of breast cancer, there is a need to identify differentially expressed genes associated with breast cancer subtypes for its timely diagnosis and treatment. OBJECTIVE: To identify a small gene set for each of the four breast cancer subtypes that could act as its signature, the paper proposes a novel algorithm for gene signature identification. METHODS: The present work uses interpretable AI methods to investigate the predictions made by the deep neural network employed for subtype classification to identify biomarkers using the TCGA breast cancer RNA Sequence data. RESULTS: The proposed algorithm led to the discovery of a set of 43 differentially expressed gene signatures. We achieved a competitive average 10-fold accuracy of 0.91, using neural network classifier. Further, gene set analysis revealed several relevant pathways, such as GRB7 events in ERBB2 and p53 signaling pathway. Using the Pearson correlation matrix, we noted that the subtype-specific genes are correlated within each subtype. CONCLUSIONS: The proposed technique enables us to find a concise and clinically relevant gene signature set.
Deep Learning Based Model for Breast Cancer Subtype Classification
Nov 09, 2021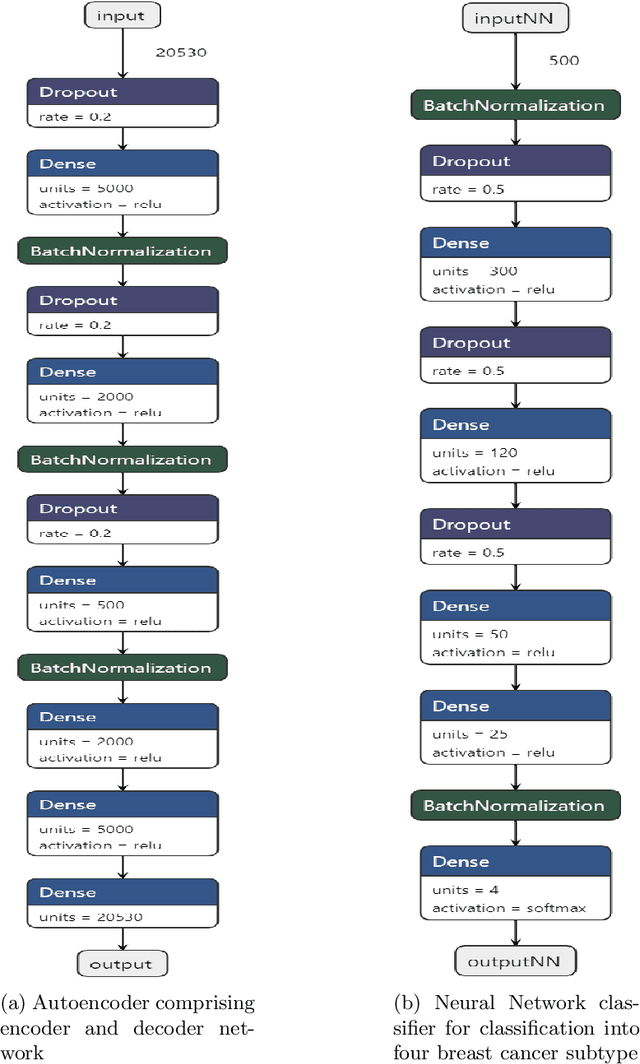
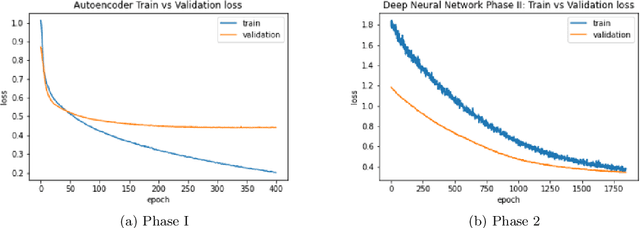
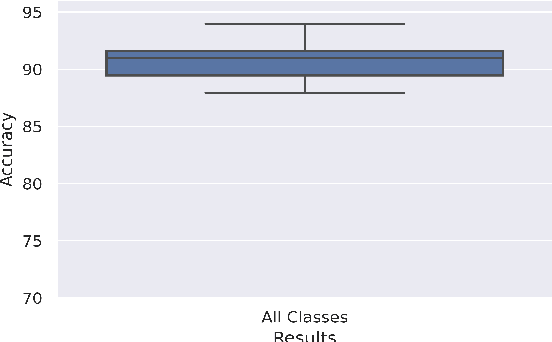
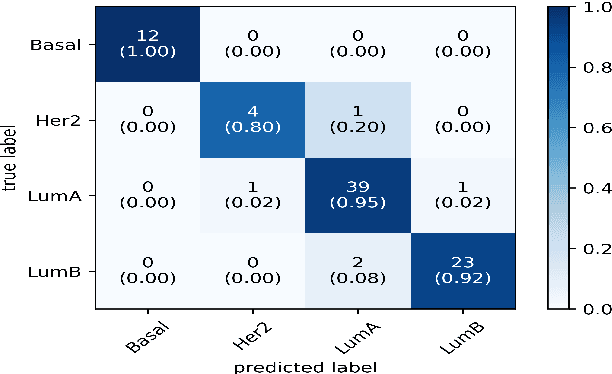
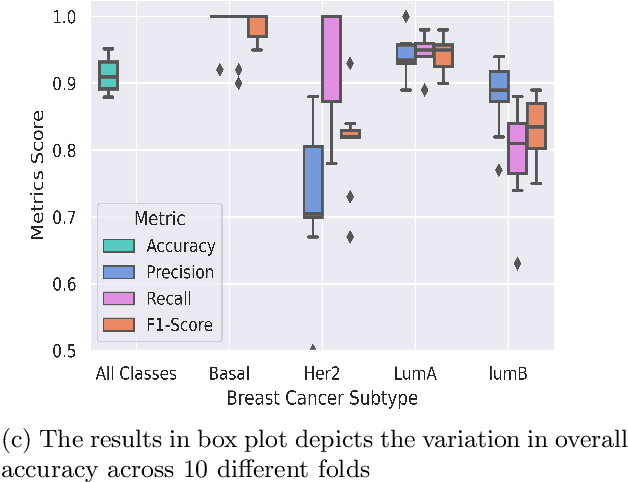
Breast cancer has long been a prominent cause of mortality among women. Diagnosis, therapy, and prognosis are now possible, thanks to the availability of RNA sequencing tools capable of recording gene expression data. Molecular subtyping being closely related to devising clinical strategy and prognosis, this paper focuses on the use of gene expression data for the classification of breast cancer into four subtypes, namely, Basal, Her2, LumA, and LumB. In stage 1, we suggested a deep learning-based model that uses an autoencoder to reduce dimensionality. The size of the feature set is reduced from 20,530 gene expression values to 500 by using an autoencoder. This encoded representation is passed to the deep neural network of the second stage for the classification of patients into four molecular subtypes of breast cancer. By deploying the combined network of stages 1 and 2, we have been able to attain a mean 10-fold test accuracy of 0.907 on the TCGA breast cancer dataset. The proposed framework is fairly robust throughout 10 different runs, as shown by the boxplot for classification accuracy. Compared to related work reported in the literature, we have achieved a competitive outcome. In conclusion, the proposed two-stage deep learning-based model is able to accurately classify four breast cancer subtypes, highlighting the autoencoder's capacity to deduce the compact representation and the neural network classifier's ability to correctly label breast cancer patients.
COV-ELM classifier: An Extreme Learning Machine based identification of COVID-19 using Chest X-Ray Images
Aug 15, 2020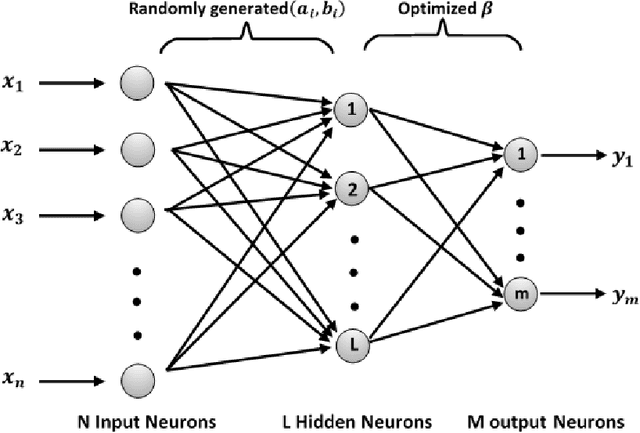
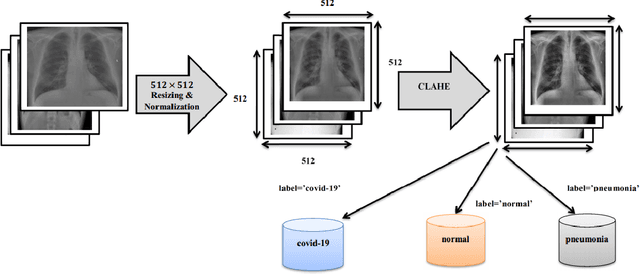
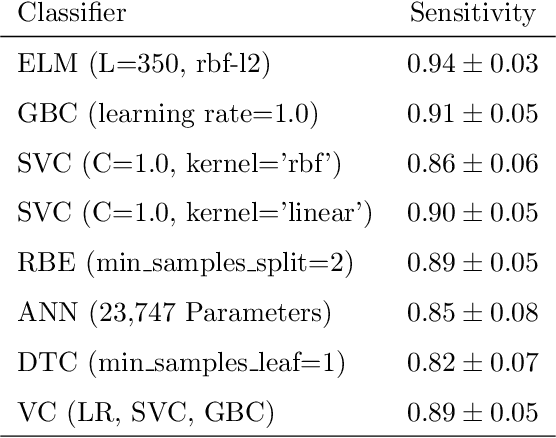
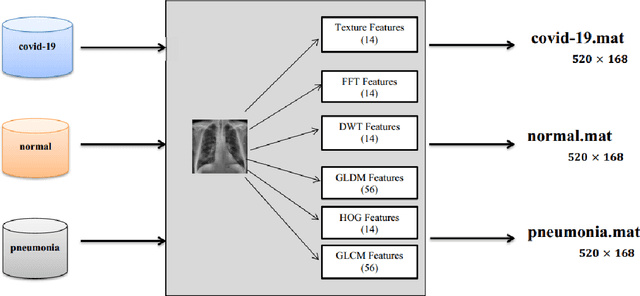
Coronaviruses constitute a family of virus that gives rise to respiratory diseases. Coronavirus disease 2019 (COVID-19) is an infectious disease caused by a newly discovered coronavirus also termed as Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). Due to its rapid spread, WHO has declared COVID-19 outbreak a pandemic on 11th March 2020. Reverse transcription-polymerase chain reaction (RT-PCR) test is popularly used worldwide for the detection of COVID-19. However, due to the high false-negative rate of RT-PCR test, chest X-ray (CXR) imaging is emerging as a feasible alternative for the detection of COVID-19. In this work, we propose a multiclass classification model COV-ELM, based on the extreme learning machine which classifies the CXR images into one of the three classes, namely COVID-19, normal, and pneumonia. The choice of ELM in this work has been motivated by its significantly short training time as compared to conventional gradient-based learning algorithms. After some preprocessing, we extract a pool of features based on texture and frequency. This pool of features serves as an input to the ELM and a 10-fold cross-validation method is employed to evaluate the proposed model. For experimentation, we use chest X-ray (CXR) images from three publicly available sources. The results of applying COV-ELM on test data are quite promising. The COV-ELM achieved a macro average F1-score of 0.95 and the overall sensitivity of ${0.94 \pm 0.02}$ at 95% confidence interval. When compared to state-of-the-art machine learning algorithms, the COV-ELM is found to outperform in a three-class classification scenario. The main advantage of COV-ELM is that its training time being quite low, as bigger and diverse datasets become available, it can be quickly retrained as compared to its gradient-based competitor models.