 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning-based optimization workflow of the homogeneity of spunbond nonwovens with human validation
Apr 15, 2024In the last ten years, the average annual growth rate of nonwoven production was 4%. In 2020 and 2021, nonwoven production has increased even further due to the huge demand for nonwoven products needed for protective clothing such as FFP2 masks to combat the COVID19 pandemic. Optimizing the production process is still a challenge due to its high nonlinearity. In this paper, we present a machine learning-based optimization workflow aimed at improving the homogeneity of spunbond nonwovens. The optimization workflow is based on a mathematical model that simulates the microstructures of nonwovens. Based on trainingy data coming from this simulator, different machine learning algorithms are trained in order to find a surrogate model for the time-consuming simulator. Human validation is employed to verify the outputs of machine learning algorithms by assessing the aesthetics of the nonwovens. We include scientific and expert knowledge into the training data to reduce the computational costs involved in the optimization process. We demonstrate the necessity and effectiveness of our workflow in optimizing the homogeneity of nonwovens.
Survey on Semantic Stereo Matching / Semantic Depth Estimation
Sep 21, 2021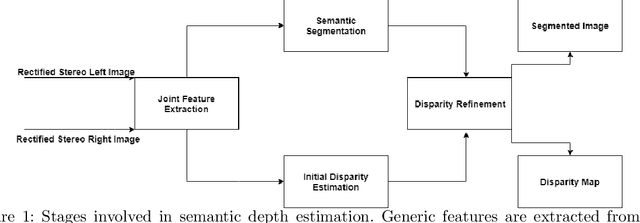
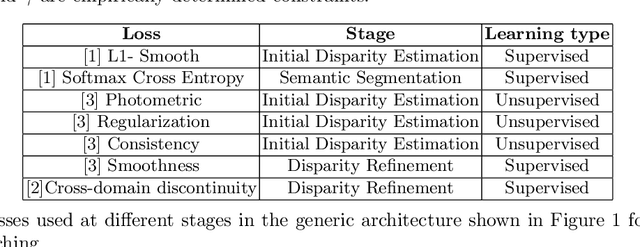
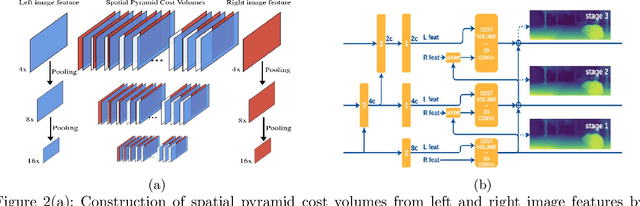

Stereo matching is one of the widely used techniques for inferring depth from stereo images owing to its robustness and speed. It has become one of the major topics of research since it finds its applications in autonomous driving, robotic navigation, 3D reconstruction, and many other fields. Finding pixel correspondences in non-textured, occluded and reflective areas is the major challenge in stereo matching. Recent developments have shown that semantic cues from image segmentation can be used to improve the results of stereo matching. Many deep neural network architectures have been proposed to leverage the advantages of semantic segmentation in stereo matching. This paper aims to give a comparison among the state of art networks both in terms of accuracy and in terms of speed which are of higher importance in real-time applications.
Visual Probing and Correction of Object Recognition Models with Interactive user feedback
Dec 29, 2020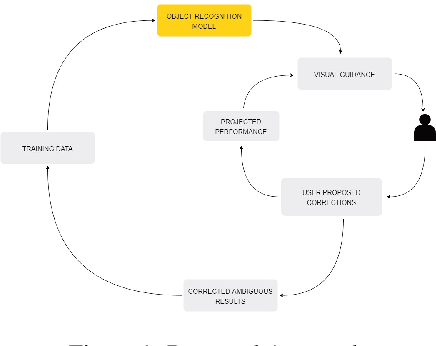
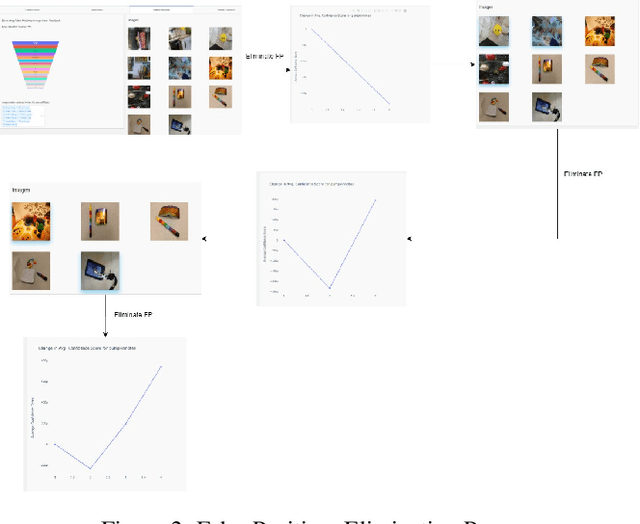
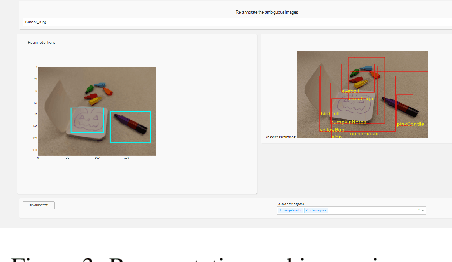
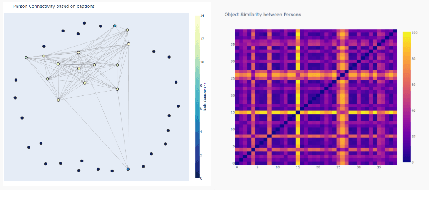
With the advent of state-of-the-art machine learning and deep learning technologies, several industries are moving towards the field. Applications of such technologies are highly diverse ranging from natural language processing to computer vision. Object recognition is one such area in the computer vision domain. Although proven to perform with high accuracy, there are still areas where such models can be improved. This is in-fact highly important in real-world use cases like autonomous driving or cancer detection, that are highly sensitive and expect such technologies to have almost no uncertainties. In this paper, we attempt to visualise the uncertainties in object recognition models and propose a correction process via user feedback. We further demonstrate our approach on the data provided by the VAST 2020 Mini-Challenge 2.