 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResampling methods for parameter-free and robust feature selection with mutual information
Sep 23, 2007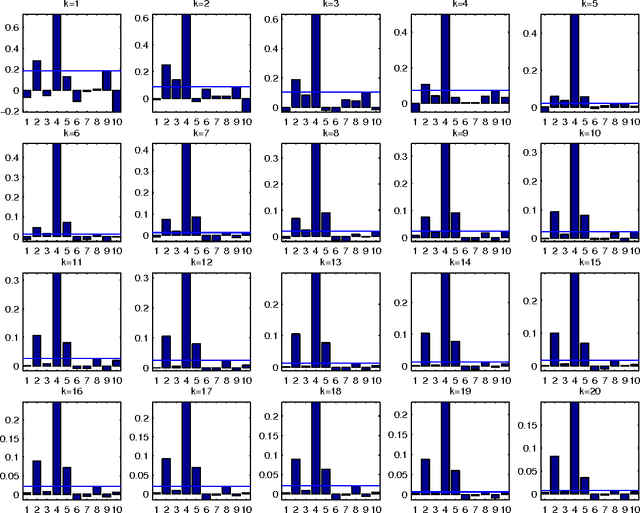
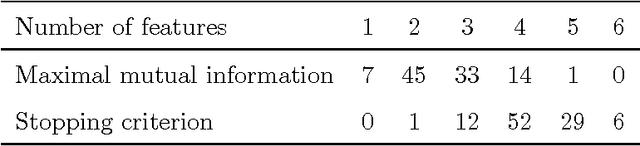
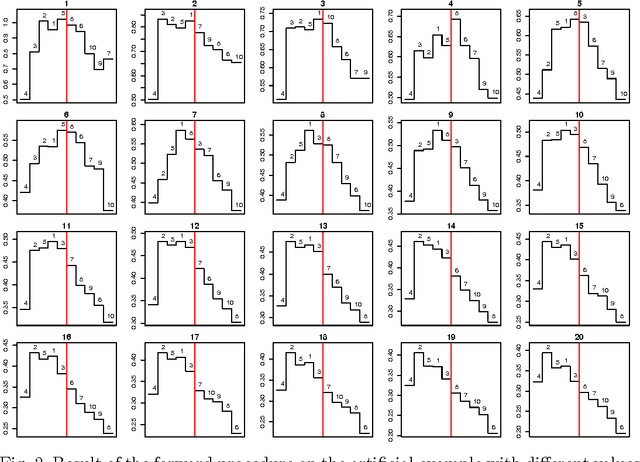

Combining the mutual information criterion with a forward feature selection strategy offers a good trade-off between optimality of the selected feature subset and computation time. However, it requires to set the parameter(s) of the mutual information estimator and to determine when to halt the forward procedure. These two choices are difficult to make because, as the dimensionality of the subset increases, the estimation of the mutual information becomes less and less reliable. This paper proposes to use resampling methods, a K-fold cross-validation and the permutation test, to address both issues. The resampling methods bring information about the variance of the estimator, information which can then be used to automatically set the parameter and to calculate a threshold to stop the forward procedure. The procedure is illustrated on a synthetic dataset as well as on real-world examples.
Fast Selection of Spectral Variables with B-Spline Compression
Sep 23, 2007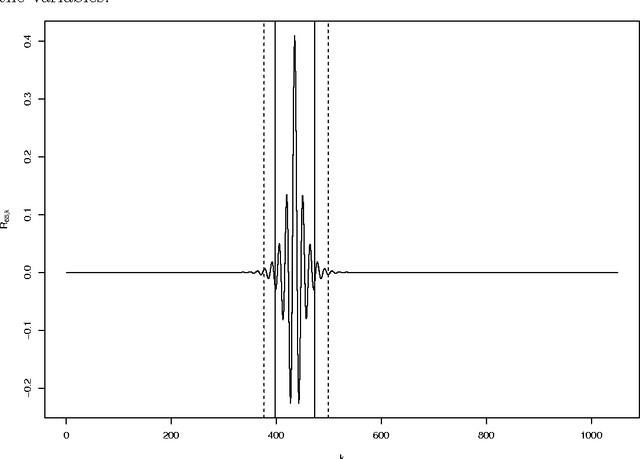
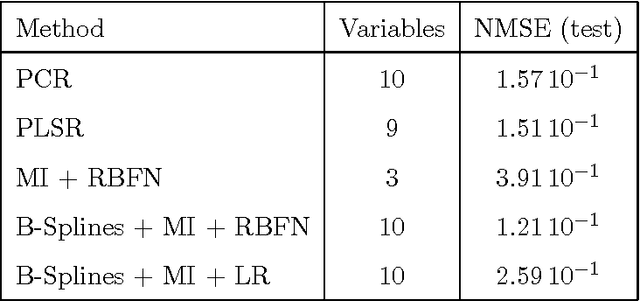
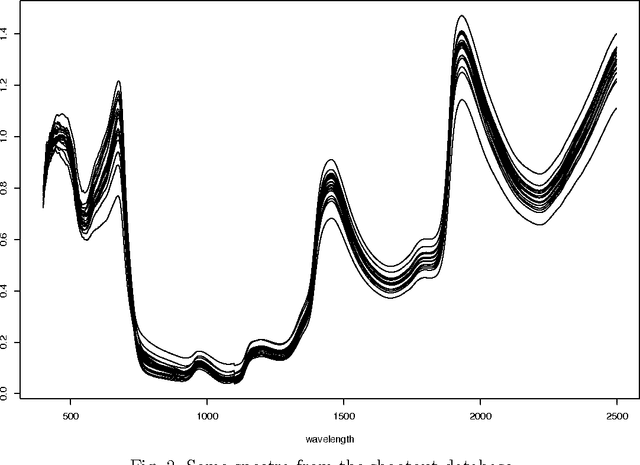
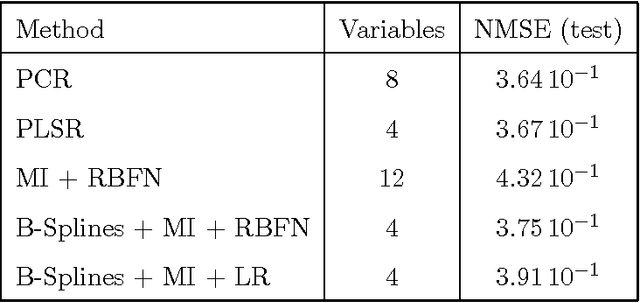
The large number of spectral variables in most data sets encountered in spectral chemometrics often renders the prediction of a dependent variable uneasy. The number of variables hopefully can be reduced, by using either projection techniques or selection methods; the latter allow for the interpretation of the selected variables. Since the optimal approach of testing all possible subsets of variables with the prediction model is intractable, an incremental selection approach using a nonparametric statistics is a good option, as it avoids the computationally intensive use of the model itself. It has two drawbacks however: the number of groups of variables to test is still huge, and colinearities can make the results unstable. To overcome these limitations, this paper presents a method to select groups of spectral variables. It consists in a forward-backward procedure applied to the coefficients of a B-Spline representation of the spectra. The criterion used in the forward-backward procedure is the mutual information, allowing to find nonlinear dependencies between variables, on the contrary of the generally used correlation. The spline representation is used to get interpretability of the results, as groups of consecutive spectral variables will be selected. The experiments conducted on NIR spectra from fescue grass and diesel fuels show that the method provides clearly identified groups of selected variables, making interpretation easy, while keeping a low computational load. The prediction performances obtained using the selected coefficients are higher than those obtained by the same method applied directly to the original variables and similar to those obtained using traditional models, although using significantly less spectral variables.
Mutual information for the selection of relevant variables in spectrometric nonlinear modelling
Sep 21, 2007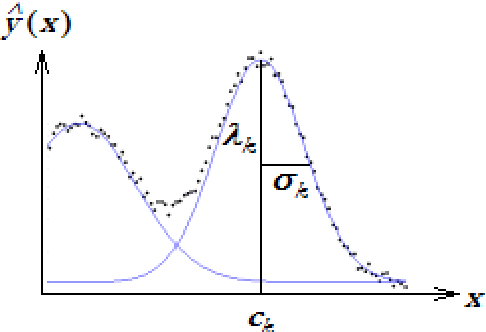
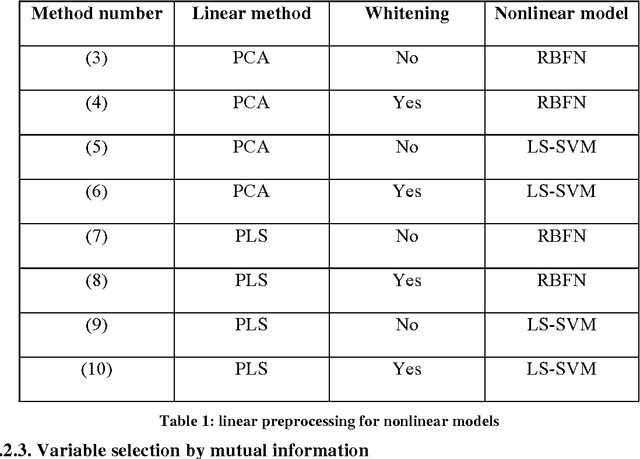
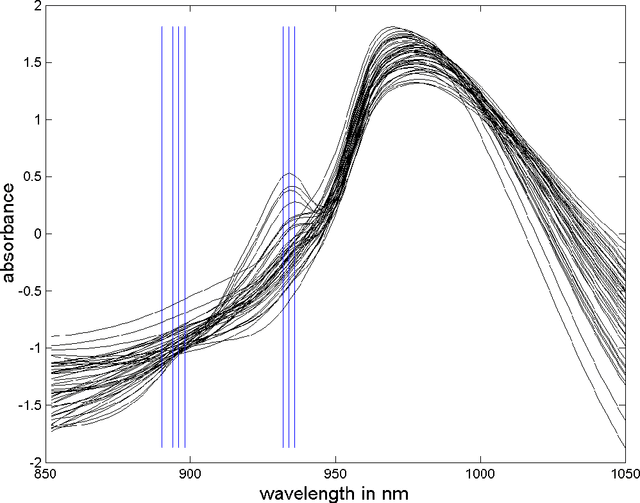
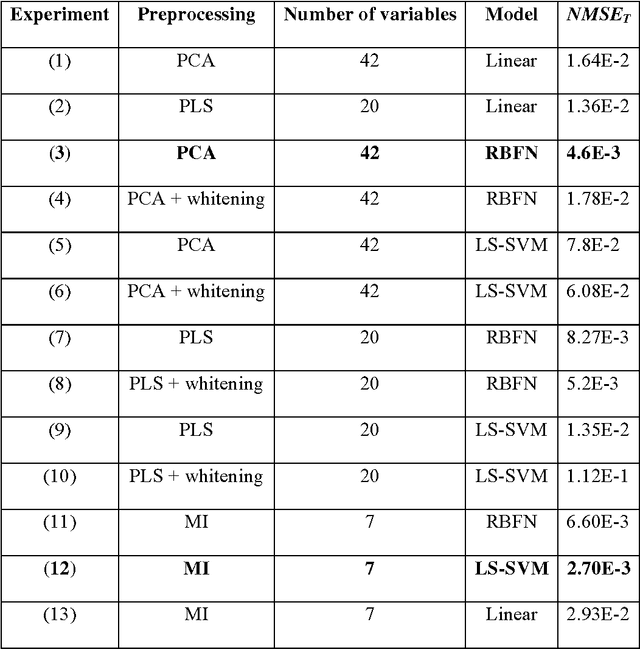
Data from spectrophotometers form vectors of a large number of exploitable variables. Building quantitative models using these variables most often requires using a smaller set of variables than the initial one. Indeed, a too large number of input variables to a model results in a too large number of parameters, leading to overfitting and poor generalization abilities. In this paper, we suggest the use of the mutual information measure to select variables from the initial set. The mutual information measures the information content in input variables with respect to the model output, without making any assumption on the model that will be used; it is thus suitable for nonlinear modelling. In addition, it leads to the selection of variables among the initial set, and not to linear or nonlinear combinations of them. Without decreasing the model performances compared to other variable projection methods, it allows therefore a greater interpretability of the results.