 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElicitation-Augmented Bayesian Optimization
May 12, 2026Human-in-the-loop Bayesian optimization (HITL BO) methods utilize human expertise to improve the sample-efficiency of BO. Most HITL BO methods assume that a domain expert can quantify their knowledge, for instance by pinpointing query locations or specifying their prior beliefs about the location of the maximum as a probability distribution. However, since human expertise is often tacit and cannot be explicitly quantified, we consider a setting where domain knowledge of an expert is elicited via pairwise comparisons of designs. We interpret the expert's pairwise judgements as noisy evidence about the values of the observable objective function and develop a principled method for combining the information obtained via direct observations and pairwise queries. Specifically, we derive a cost-aware value-of-information acquisition function that balances direct observations against pairwise queries. The proposed method approaches the convex hull of the trajectories of the individual information sources: when pairwise queries are cheap it substantially improves sample-efficiency over observation-only BO, and when pairwise queries are costly or noisy, it recovers the performance of standard BO by relying on direct observations alone.
LEMUR: Learned Multi-Vector Retrieval
Jan 29, 2026Multi-vector representations generated by late interaction models, such as ColBERT, enable superior retrieval quality compared to single-vector representations in information retrieval applications. In multi-vector retrieval systems, both queries and documents are encoded using one embedding for each token, and similarity between queries and documents is measured by the MaxSim similarity measure. However, the improved recall of multi-vector retrieval comes at the expense of significantly increased latency. This necessitates designing efficient approximate nearest neighbor search (ANNS) algorithms for multi-vector search. In this work, we introduce LEMUR, a simple-yet-efficient framework for multi-vector similarity search. LEMUR consists of two consecutive problem reductions: We first formulate multi-vector similarity search as a supervised learning problem that can be solved using a one-hidden-layer neural network. Second, we reduce inference under this model to single-vector similarity search in its latent space, which enables the use of existing single-vector ANNS methods for speeding up retrieval. In addition to performance evaluation on ColBERTv2 embeddings, we evaluate LEMUR on embeddings generated by modern multi-vector text models and multi-vector visual document retrieval models. LEMUR is an order of magnitude faster than earlier multi-vector similarity search methods.
VIBE: Vector Index Benchmark for Embeddings
May 23, 2025Approximate nearest neighbor (ANN) search is a performance-critical component of many machine learning pipelines. Rigorous benchmarking is essential for evaluating the performance of vector indexes for ANN search. However, the datasets of the existing benchmarks are no longer representative of the current applications of ANN search. Hence, there is an urgent need for an up-to-date set of benchmarks. To this end, we introduce Vector Index Benchmark for Embeddings (VIBE), an open source project for benchmarking ANN algorithms. VIBE contains a pipeline for creating benchmark datasets using dense embedding models characteristic of modern applications, such as retrieval-augmented generation (RAG). To replicate real-world workloads, we also include out-of-distribution (OOD) datasets where the queries and the corpus are drawn from different distributions. We use VIBE to conduct a comprehensive evaluation of SOTA vector indexes, benchmarking 21 implementations on 12 in-distribution and 6 out-of-distribution datasets.
LoRANN: Low-Rank Matrix Factorization for Approximate Nearest Neighbor Search
Oct 24, 2024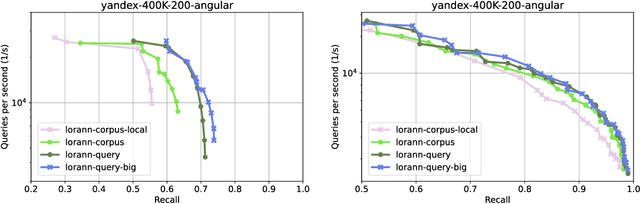
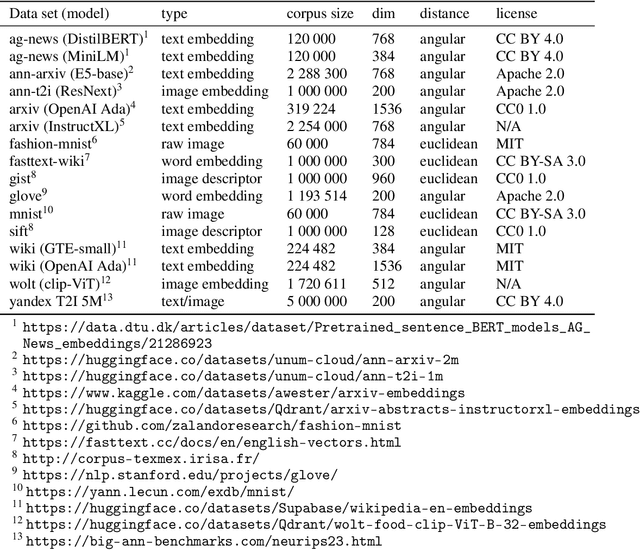
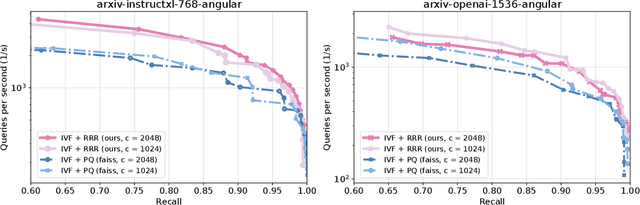
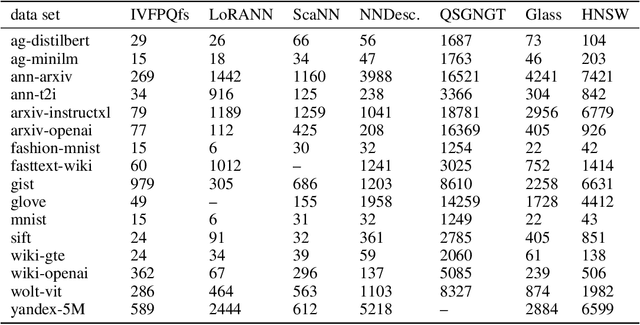
Approximate nearest neighbor (ANN) search is a key component in many modern machine learning pipelines; recent use cases include retrieval-augmented generation (RAG) and vector databases. Clustering-based ANN algorithms, that use score computation methods based on product quantization (PQ), are often used in industrial-scale applications due to their scalability and suitability for distributed and disk-based implementations. However, they have slower query times than the leading graph-based ANN algorithms. In this work, we propose a new supervised score computation method based on the observation that inner product approximation is a multivariate (multi-output) regression problem that can be solved efficiently by reduced-rank regression. Our experiments show that on modern high-dimensional data sets, the proposed reduced-rank regression (RRR) method is superior to PQ in both query latency and memory usage. We also introduce LoRANN, a clustering-based ANN library that leverages the proposed score computation method. LoRANN is competitive with the leading graph-based algorithms and outperforms the state-of-the-art GPU ANN methods on high-dimensional data sets.
Supervised Learning Approach to Approximate Nearest Neighbor Search
Oct 18, 2019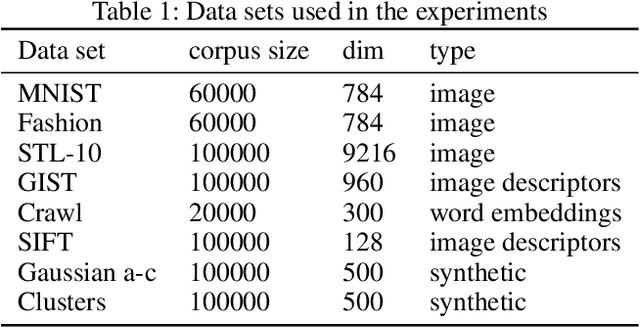
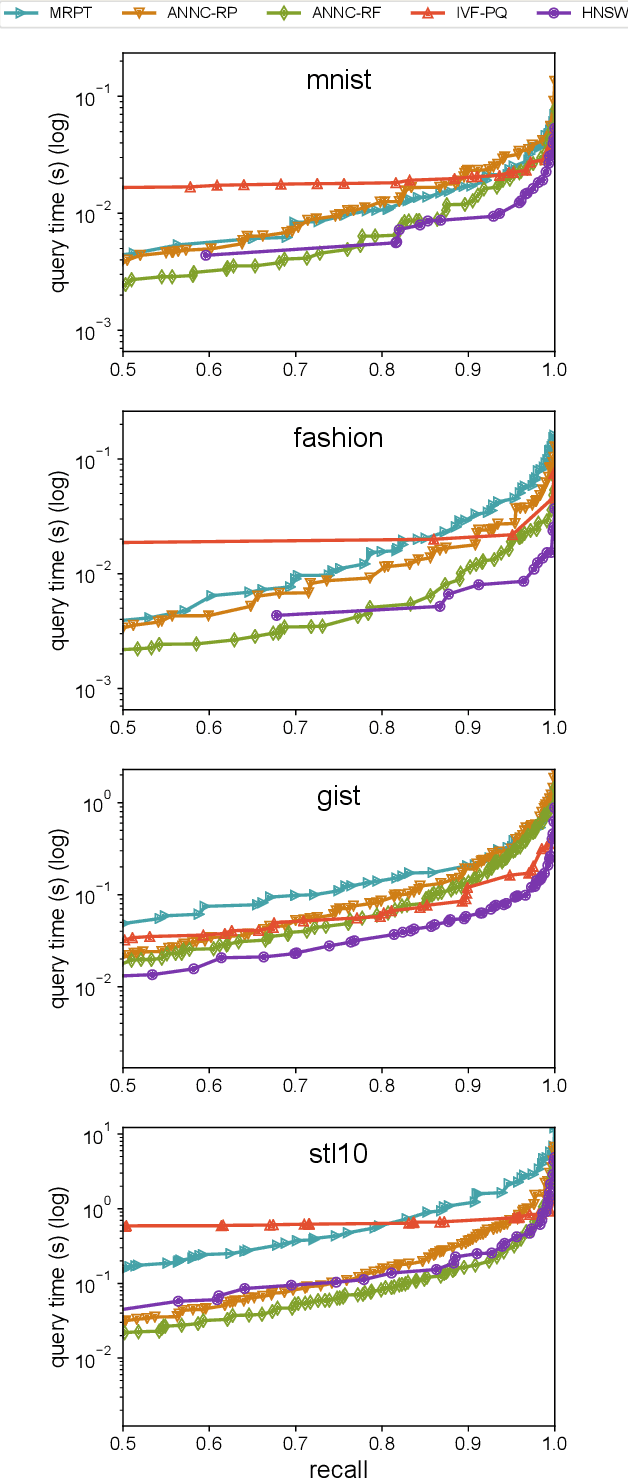
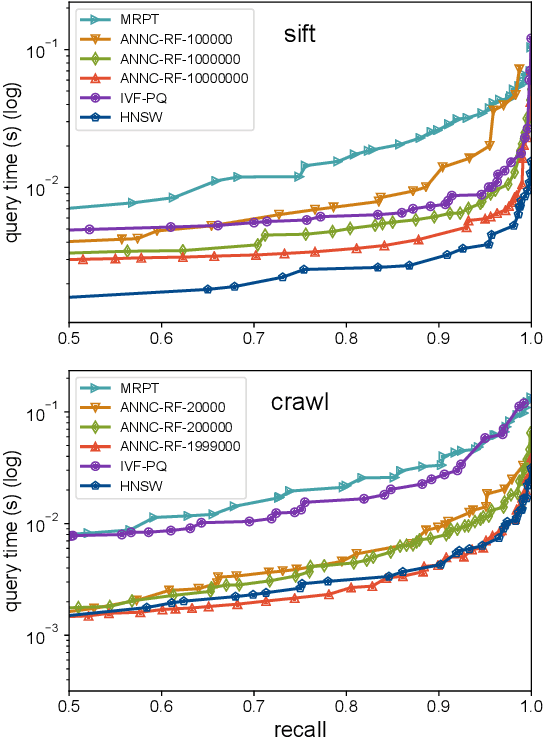
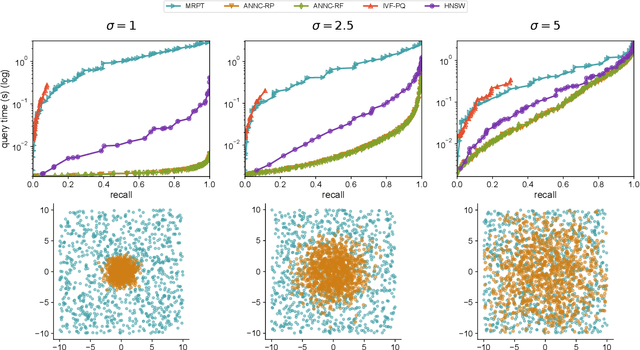
Approximate nearest neighbor search is a classic algorithmic problem where the goal is to design an efficient index structure for fast approximate nearest neighbor queries. We show that it can be framed as a classification problem and solved by training a suitable multi-label classifier and using it as an index. Compared to the existing algorithms, this supervised learning approach has several advantages: it enables adapting an index to the query distribution when the query distribution and the corpus distribution differ; it allows using training sets larger than the corpus; and in principle it enables using any multi-label classifier for approximate nearest neighbor search. We demonstrate these advantages on multiple synthetic and real-world data sets by using a random forest and an ensemble of random projection trees as the base classifiers.
Efficient Autotuning of Hyperparameters in Approximate Nearest Neighbor Search
Dec 18, 2018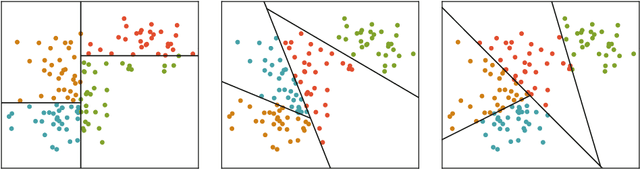
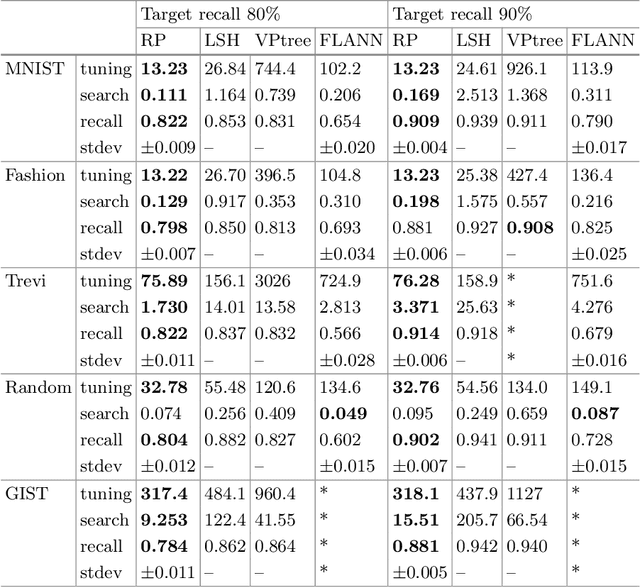
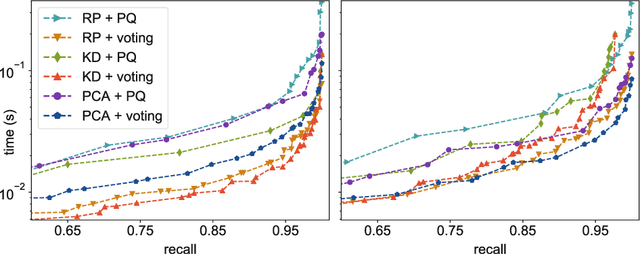
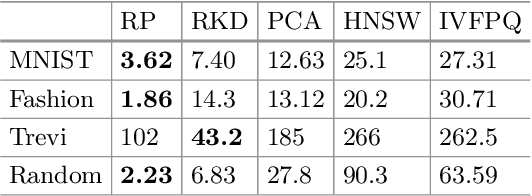
Approximate nearest neighbor algorithms are used to speed up nearest neighbor search in a wide array of applications. However, current indexing methods feature several hyperparameters that need to be tuned to reach an acceptable accuracy--speed trade-off. A grid search in the parameter space is often impractically slow due to a time-consuming index-building procedure. Therefore, we propose an algorithm for automatically tuning the hyperparameters of indexing methods based on randomized space-partitioning trees. In particular, we present results using randomized k-d trees, random projection trees and randomized PCA trees. The tuning algorithm adds minimal overhead to the index-building process but is able to find the optimal hyperparameters accurately. We demonstrate that the algorithm is significantly faster than existing approaches, and that the indexing methods used are competitive with the state-of-the-art methods in query time while being faster to build.
Fast k-NN search
Aug 19, 2016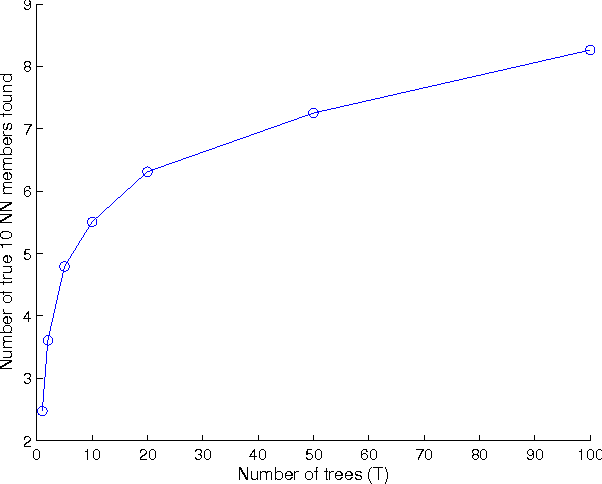
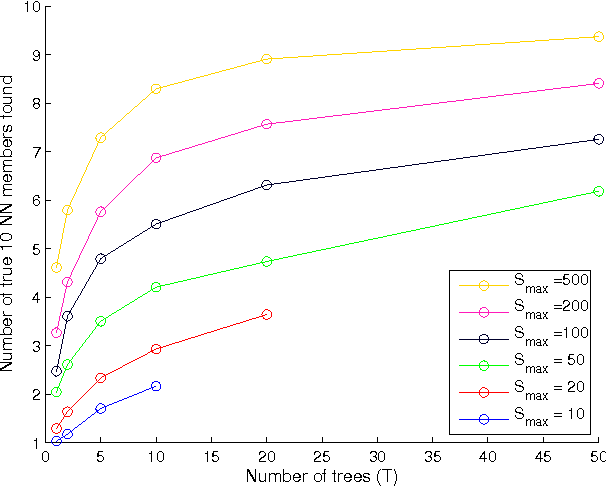
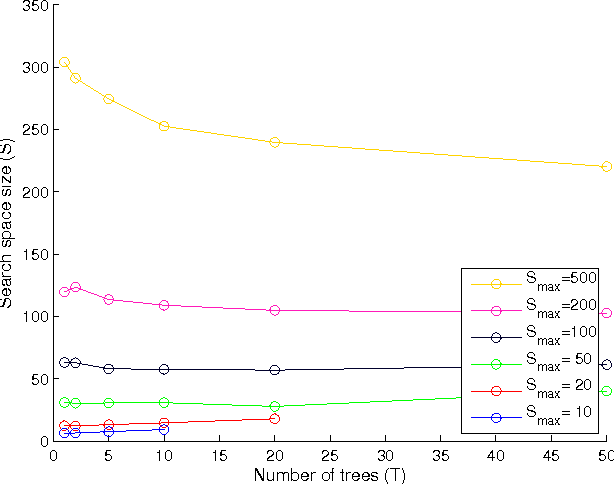
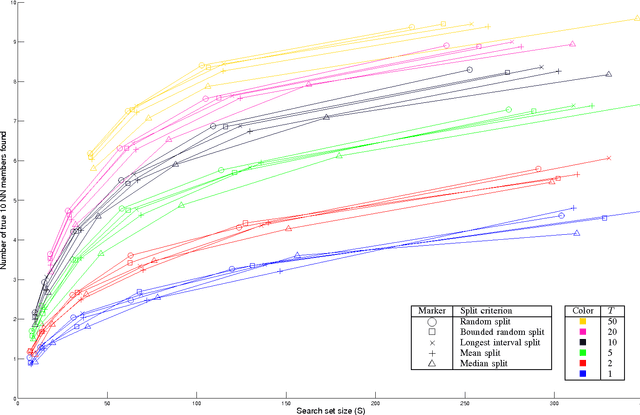
Efficient index structures for fast approximate nearest neighbor queries are required in many applications such as recommendation systems. In high-dimensional spaces, many conventional methods suffer from excessive usage of memory and slow response times. We propose a method where multiple random projection trees are combined by a novel voting scheme. The key idea is to exploit the redundancy in a large number of candidate sets obtained by independently generated random projections in order to reduce the number of expensive exact distance evaluations. The method is straightforward to implement using sparse projections which leads to a reduced memory footprint and fast index construction. Furthermore, it enables grouping of the required computations into big matrix multiplications, which leads to additional savings due to cache effects and low-level parallelization. We demonstrate by extensive experiments on a wide variety of data sets that the method is faster than existing partitioning tree or hashing based approaches, making it the fastest available technique on high accuracy levels.