 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Online Crowdsourcing with Complex Annotations
Jan 25, 2024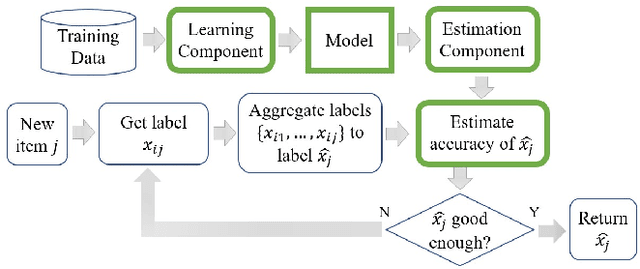

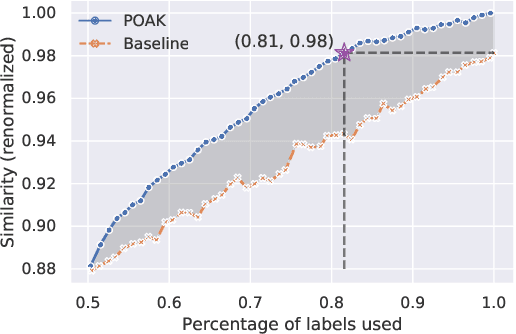
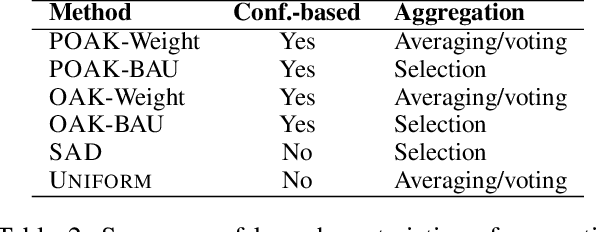
Crowdsourcing platforms use various truth discovery algorithms to aggregate annotations from multiple labelers. In an online setting, however, the main challenge is to decide whether to ask for more annotations for each item to efficiently trade off cost (i.e., the number of annotations) for quality of the aggregated annotations. In this paper, we propose a novel approach for general complex annotation (such as bounding boxes and taxonomy paths), that works in an online crowdsourcing setting. We prove that the expected average similarity of a labeler is linear in their accuracy \emph{conditional on the reported label}. This enables us to infer reported label accuracy in a broad range of scenarios. We conduct extensive evaluations on real-world crowdsourcing data from Meta and show the effectiveness of our proposed online algorithms in improving the cost-quality trade-off.