 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring WavLM Back-ends for Speech Spoofing and Deepfake Detection
Sep 08, 2024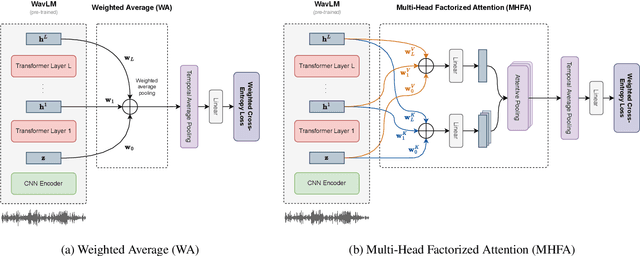


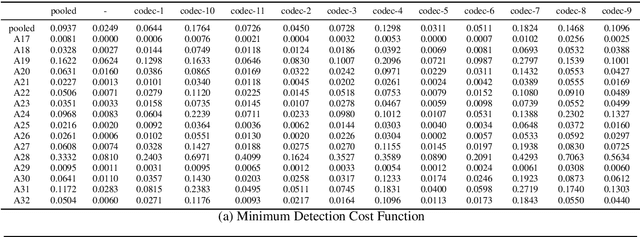
This paper describes our submitted systems to the ASVspoof 5 Challenge Track 1: Speech Deepfake Detection - Open Condition, which consists of a stand-alone speech deepfake (bonafide vs spoof) detection task. Recently, large-scale self-supervised models become a standard in Automatic Speech Recognition (ASR) and other speech processing tasks. Thus, we leverage a pre-trained WavLM as a front-end model and pool its representations with different back-end techniques. The complete framework is fine-tuned using only the trained dataset of the challenge, similar to the close condition. Besides, we adopt data-augmentation by adding noise and reverberation using MUSAN noise and RIR datasets. We also experiment with codec augmentations to increase the performance of our method. Ultimately, we use the Bosaris toolkit for score calibration and system fusion to get better Cllr scores. Our fused system achieves 0.0937 minDCF, 3.42% EER, 0.1927 Cllr, and 0.1375 actDCF.
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Jun 04, 2024Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.