 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring WavLM Back-ends for Speech Spoofing and Deepfake Detection
Paper and Code
Sep 08, 2024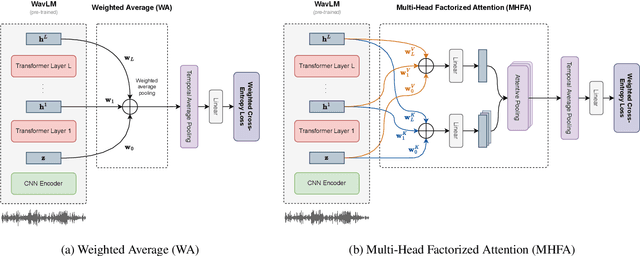


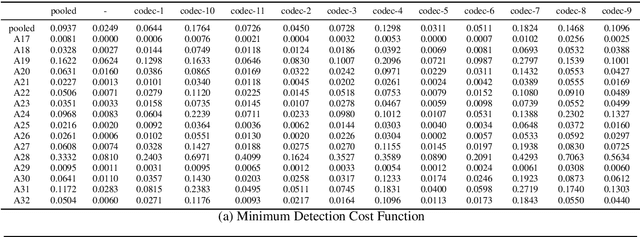
This paper describes our submitted systems to the ASVspoof 5 Challenge Track 1: Speech Deepfake Detection - Open Condition, which consists of a stand-alone speech deepfake (bonafide vs spoof) detection task. Recently, large-scale self-supervised models become a standard in Automatic Speech Recognition (ASR) and other speech processing tasks. Thus, we leverage a pre-trained WavLM as a front-end model and pool its representations with different back-end techniques. The complete framework is fine-tuned using only the trained dataset of the challenge, similar to the close condition. Besides, we adopt data-augmentation by adding noise and reverberation using MUSAN noise and RIR datasets. We also experiment with codec augmentations to increase the performance of our method. Ultimately, we use the Bosaris toolkit for score calibration and system fusion to get better Cllr scores. Our fused system achieves 0.0937 minDCF, 3.42% EER, 0.1927 Cllr, and 0.1375 actDCF.