 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning for Speaker Recognition: A study and review
Feb 11, 2026Deep learning models trained in a supervised setting have revolutionized audio and speech processing. However, their performance inherently depends on the quantity of human-annotated data, making them costly to scale and prone to poor generalization under unseen conditions. To address these challenges, Self-Supervised Learning (SSL) has emerged as a promising paradigm, leveraging vast amounts of unlabeled data to learn relevant representations. The application of SSL for Automatic Speech Recognition (ASR) has been extensively studied, but research on other downstream tasks, notably Speaker Recognition (SR), remains in its early stages. This work describes major SSL instance-invariance frameworks (e.g., SimCLR, MoCo, and DINO), initially developed for computer vision, along with their adaptation to SR. Various SSL methods for SR, proposed in the literature and built upon these frameworks, are also presented. An extensive review of these approaches is then conducted: (1) the effect of the main hyperparameters of SSL frameworks is investigated; (2) the role of SSL components is studied (e.g., data-augmentation, projector, positive sampling); and (3) SSL frameworks are evaluated on SR with in-domain and out-of-domain data, using a consistent experimental setup, and a comprehensive comparison of SSL methods from the literature is provided. Specifically, DINO achieves the best downstream performance and effectively models intra-speaker variability, although it is highly sensitive to hyperparameters and training conditions, while SimCLR and MoCo provide robust alternatives that effectively capture inter-speaker variability and are less prone to collapse. This work aims to highlight recent trends and advancements, identifying current challenges in the field.
* accepted for publication in Speech Communication
SSPS: Self-Supervised Positive Sampling for Robust Self-Supervised Speaker Verification
May 20, 2025Self-Supervised Learning (SSL) has led to considerable progress in Speaker Verification (SV). The standard framework uses same-utterance positive sampling and data-augmentation to generate anchor-positive pairs of the same speaker. This is a major limitation, as this strategy primarily encodes channel information from the recording condition, shared by the anchor and positive. We propose a new positive sampling technique to address this bottleneck: Self-Supervised Positive Sampling (SSPS). For a given anchor, SSPS aims to find an appropriate positive, i.e., of the same speaker identity but a different recording condition, in the latent space using clustering assignments and a memory queue of positive embeddings. SSPS improves SV performance for both SimCLR and DINO, reaching 2.57% and 2.53% EER, outperforming SOTA SSL methods on VoxCeleb1-O. In particular, SimCLR-SSPS achieves a 58% EER reduction by lowering intra-speaker variance, providing comparable performance to DINO-SSPS.
Self-Supervised Frameworks for Speaker Verification via Bootstrapped Positive Sampling
Jan 29, 2025



Recent developments in Self-Supervised Learning (SSL) have demonstrated significant potential for Speaker Verification (SV), but closing the performance gap with supervised systems remains an ongoing challenge. Standard SSL frameworks rely on anchor-positive pairs extracted from the same audio utterances. Hence, positives have channel characteristics similar to those of their corresponding anchors, even with extensive data-augmentation. Therefore, this positive sampling strategy is a fundamental limitation as it encodes too much information regarding the recording source in the learned representations. This article introduces Self-Supervised Positive Sampling (SSPS), a bootstrapped technique for sampling appropriate and diverse positives in SSL frameworks for SV. SSPS samples positives close to their anchor in the representation space, as we assume that these pseudo-positives belong to the same speaker identity but correspond to different recording conditions. This method demonstrates consistent improvements in SV performance on VoxCeleb benchmarks when implemented in major SSL frameworks, such as SimCLR, SwAV, VICReg, and DINO. Using SSPS, SimCLR, and DINO achieve 2.57% and 2.53% EER on VoxCeleb1-O. SimCLR yields a 58% relative reduction in EER, getting comparable performance to DINO with a simpler training framework. Furthermore, SSPS lowers intra-class variance and reduces channel information in speaker representations while exhibiting greater robustness without data-augmentation.
Exploring WavLM Back-ends for Speech Spoofing and Deepfake Detection
Sep 08, 2024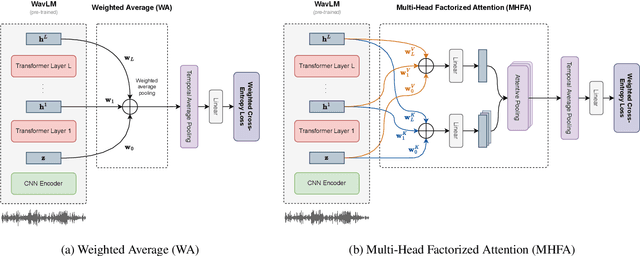


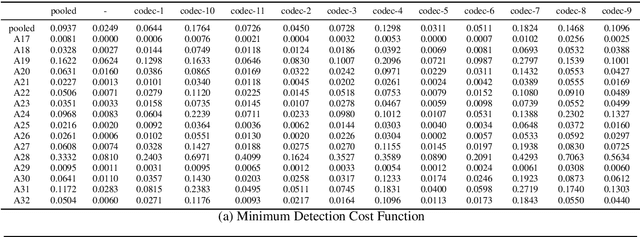
This paper describes our submitted systems to the ASVspoof 5 Challenge Track 1: Speech Deepfake Detection - Open Condition, which consists of a stand-alone speech deepfake (bonafide vs spoof) detection task. Recently, large-scale self-supervised models become a standard in Automatic Speech Recognition (ASR) and other speech processing tasks. Thus, we leverage a pre-trained WavLM as a front-end model and pool its representations with different back-end techniques. The complete framework is fine-tuned using only the trained dataset of the challenge, similar to the close condition. Besides, we adopt data-augmentation by adding noise and reverberation using MUSAN noise and RIR datasets. We also experiment with codec augmentations to increase the performance of our method. Ultimately, we use the Bosaris toolkit for score calibration and system fusion to get better Cllr scores. Our fused system achieves 0.0937 minDCF, 3.42% EER, 0.1927 Cllr, and 0.1375 actDCF.
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Jun 04, 2024Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
Additive Margin in Contrastive Self-Supervised Frameworks to Learn Discriminative Speaker Representations
Apr 23, 2024Self-Supervised Learning (SSL) frameworks became the standard for learning robust class representations by benefiting from large unlabeled datasets. For Speaker Verification (SV), most SSL systems rely on contrastive-based loss functions. We explore different ways to improve the performance of these techniques by revisiting the NT-Xent contrastive loss. Our main contribution is the definition of the NT-Xent-AM loss and the study of the importance of Additive Margin (AM) in SimCLR and MoCo SSL methods to further separate positive from negative pairs. Despite class collisions, we show that AM enhances the compactness of same-speaker embeddings and reduces the number of false negatives and false positives on SV. Additionally, we demonstrate the effectiveness of the symmetric contrastive loss, which provides more supervision for the SSL task. Implementing these two modifications to SimCLR improves performance and results in 7.85% EER on VoxCeleb1-O, outperforming other equivalent methods.
Experimenting with Additive Margins for Contrastive Self-Supervised Speaker Verification
Jun 06, 2023Most state-of-the-art self-supervised speaker verification systems rely on a contrastive-based objective function to learn speaker representations from unlabeled speech data. We explore different ways to improve the performance of these methods by: (1) revisiting how positive and negative pairs are sampled through a "symmetric" formulation of the contrastive loss; (2) introducing margins similar to AM-Softmax and AAM-Softmax that have been widely adopted in the supervised setting. We demonstrate the effectiveness of the symmetric contrastive loss which provides more supervision for the self-supervised task. Moreover, we show that Additive Margin and Additive Angular Margin allow reducing the overall number of false negatives and false positives by improving speaker separability. Finally, by combining both techniques and training a larger model we achieve 7.50% EER and 0.5804 minDCF on the VoxCeleb1 test set, which outperforms other contrastive self supervised methods on speaker verification.