 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrong bounds for large-scale Minimum Sum-of-Squares Clustering
Feb 12, 2025Clustering is a fundamental technique in data analysis and machine learning, used to group similar data points together. Among various clustering methods, the Minimum Sum-of-Squares Clustering (MSSC) is one of the most widely used. MSSC aims to minimize the total squared Euclidean distance between data points and their corresponding cluster centroids. Due to the unsupervised nature of clustering, achieving global optimality is crucial, yet computationally challenging. The complexity of finding the global solution increases exponentially with the number of data points, making exact methods impractical for large-scale datasets. Even obtaining strong lower bounds on the optimal MSSC objective value is computationally prohibitive, making it difficult to assess the quality of heuristic solutions. We address this challenge by introducing a novel method to validate heuristic MSSC solutions through optimality gaps. Our approach employs a divide-and-conquer strategy, decomposing the problem into smaller instances that can be handled by an exact solver. The decomposition is guided by an auxiliary optimization problem, the "anticlustering problem", for which we design an efficient heuristic. Computational experiments demonstrate the effectiveness of the method for large-scale instances, achieving optimality gaps below 3% in most cases while maintaining reasonable computational times. These results highlight the practicality of our approach in assessing feasible clustering solutions for large datasets, bridging a critical gap in MSSC evaluation.
Optimization meets Machine Learning: An Exact Algorithm for Semi-Supervised Support Vector Machines
Dec 15, 2023Support vector machines (SVMs) are well-studied supervised learning models for binary classification. In many applications, large amounts of samples can be cheaply and easily obtained. What is often a costly and error-prone process is to manually label these instances. Semi-supervised support vector machines (S3VMs) extend the well-known SVM classifiers to the semi-supervised approach, aiming at maximizing the margin between samples in the presence of unlabeled data. By leveraging both labeled and unlabeled data, S3VMs attempt to achieve better accuracy and robustness compared to traditional SVMs. Unfortunately, the resulting optimization problem is non-convex and hence difficult to solve exactly. In this paper, we present a new branch-and-cut approach for S3VMs using semidefinite programming (SDP) relaxations. We apply optimality-based bound tightening to bound the feasible set. Box constraints allow us to include valid inequalities, strengthening the lower bound. The resulting SDP relaxation provides bounds significantly stronger than the ones available in the literature. For the upper bound, instead, we define a local search exploiting the solution of the SDP relaxation. Computational results highlight the efficiency of the algorithm, showing its capability to solve instances with a number of data points 10 times larger than the ones solved in the literature.
Predicting municipalities in financial distress: a machine learning approach enhanced by domain expertise
Feb 11, 2023Financial distress of municipalities, although comparable to bankruptcy of private companies, has a far more serious impact on the well-being of communities. For this reason, it is essential to detect deficits as soon as possible. Predicting financial distress in municipalities can be a complex task, as it involves understanding a wide range of factors that can affect a municipality's financial health. In this paper, we evaluate machine learning models to predict financial distress in Italian municipalities. Accounting judiciary experts have specialized knowledge and experience in evaluating the financial performance of municipalities, and they use a range of financial and general indicators to make their assessments. By incorporating these indicators in the feature extraction process, we can ensure that the predictive model is taking into account a wide range of information that is relevant to the financial health of municipalities. The results of this study indicate that using machine learning models in combination with the knowledge of accounting judiciary experts can aid in the early detection of financial distress in municipalities, leading to better outcomes for the communities they serve.
Supervised Feature Compression based on Counterfactual Analysis
Nov 29, 2022Counterfactual Explanations are becoming a de-facto standard in post-hoc interpretable machine learning. For a given classifier and an instance classified in an undesired class, its counterfactual explanation corresponds to small perturbations of that instance that allows changing the classification outcome. This work aims to leverage Counterfactual Explanations to detect the important decision boundaries of a pre-trained black-box model. This information is used to build a supervised discretization of the features in the dataset with a tunable granularity. Using the discretized dataset, a smaller, therefore more interpretable Decision Tree can be trained, which, in addition, enhances the stability and robustness of the baseline Decision Tree. Numerical results on real-world datasets show the effectiveness of the approach in terms of accuracy and sparsity compared to the baseline Decision Tree.
Global Optimization for Cardinality-constrained Minimum Sum-of-Squares Clustering via Semidefinite Programming
Sep 25, 2022

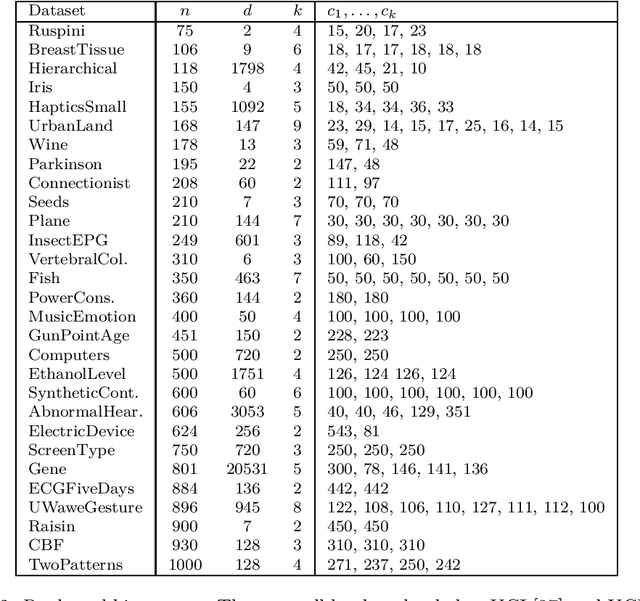
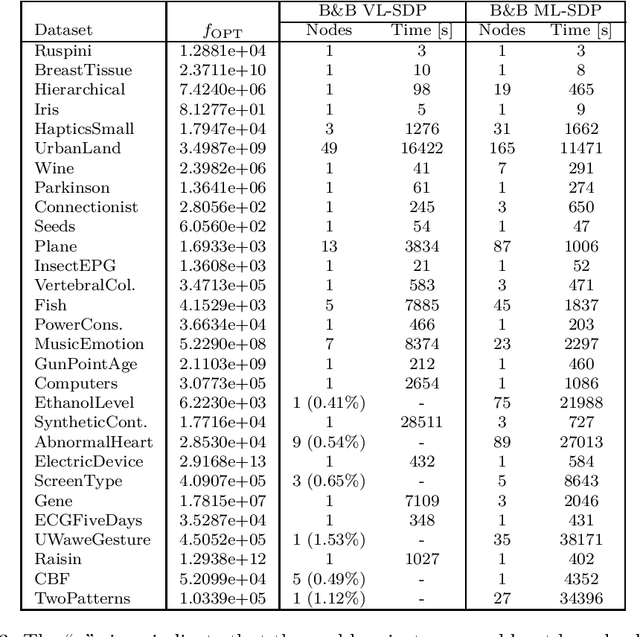
The minimum sum-of-squares clustering (MSSC), or k-means type clustering, has been recently extended to exploit prior knowledge on the cardinality of each cluster. Such knowledge is used to increase performance as well as solution quality. In this paper, we propose an exact approach based on the branch-and-cut technique to solve the cardinality-constrained MSSC. For the lower bound routine, we use the semidefinite programming (SDP) relaxation recently proposed by Rujeerapaiboon et al. [SIAM J. Optim. 29(2), 1211-1239, (2019)]. However, this relaxation can be used in a branch-and-cut method only for small-size instances. Therefore, we derive a new SDP relaxation that scales better with the instance size and the number of clusters. In both cases, we strengthen the bound by adding polyhedral cuts. Benefiting from a tailored branching strategy which enforces pairwise constraints, we reduce the complexity of the problems arising in the children nodes. For the upper bound, instead, we present a local search procedure that exploits the solution of the SDP relaxation solved at each node. Computational results show that the proposed algorithm globally solves, for the first time, real-world instances of size 10 times larger than those solved by state-of-the-art exact methods.
An Exact Algorithm for Semi-supervised Minimum Sum-of-Squares Clustering
Nov 30, 2021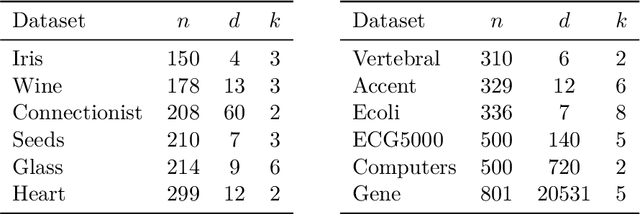
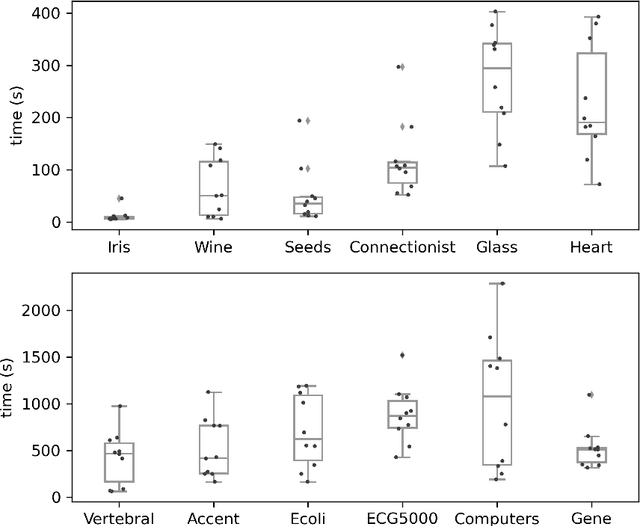

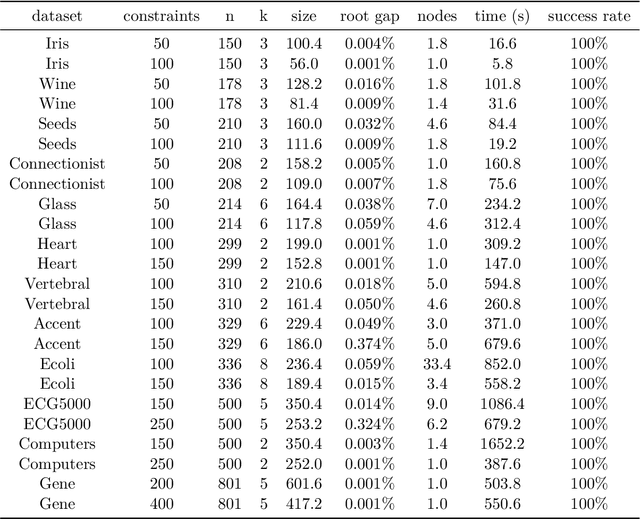
The minimum sum-of-squares clustering (MSSC), or k-means type clustering, is traditionally considered an unsupervised learning task. In recent years, the use of background knowledge to improve the cluster quality and promote interpretability of the clustering process has become a hot research topic at the intersection of mathematical optimization and machine learning research. The problem of taking advantage of background information in data clustering is called semi-supervised or constrained clustering. In this paper, we present a new branch-and-bound algorithm for semi-supervised MSSC, where background knowledge is incorporated as pairwise must-link and cannot-link constraints. For the lower bound procedure, we solve the semidefinite programming relaxation of the MSSC discrete optimization model, and we use a cutting-plane procedure for strengthening the bound. For the upper bound, instead, by using integer programming tools, we propose an adaptation of the k-means algorithm to the constrained case. For the first time, the proposed global optimization algorithm efficiently manages to solve real-world instances up to 800 data points with different combinations of must-link and cannot-link constraints and with a generic number of features. This problem size is about four times larger than the one of the instances solved by state-of-the-art exact algorithms.
A machine learning approach for forecasting hierarchical time series
May 31, 2020


In this paper, we propose a machine learning approach for forecasting hierarchical time series. Rather than using historical or forecasted proportions, as in standard top-down approaches, we formulate the disaggregation problem as a non-linear regression problem. We propose a deep neural network that automatically learns how to distribute the top-level forecasts to the bottom level-series of the hierarchy, keeping into account the characteristics of the aggregate series and the information of the individual series. In order to evaluate the performance of the proposed method, we analyze hierarchical sales data and electricity demand data. Besides comparison with the top-down approaches, the model is compared with the bottom-up method and the optimal reconciliation method. Results demonstrate that our method does not only increase the average forecasting accuracy of the hierarchy but also addresses the need of building an automated procedure generating coherent forecasts for many time series at the same time.
Non-Intrusive Load Monitoring with an Attention-based Deep Neural Network
Nov 15, 2019

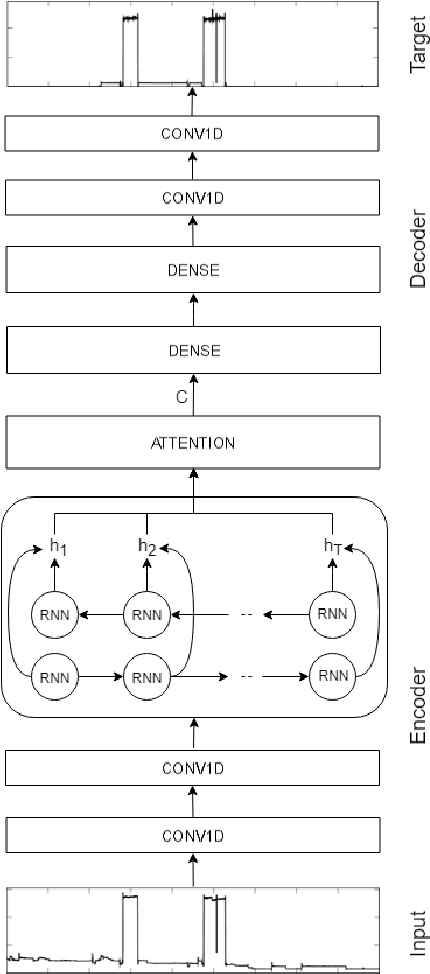

Energy disaggregation, also referred to as a Non-Intrusive Load Monitoring (NILM), is the task of using an aggregate energy signal, for example coming from a whole-home power monitor, to make inferences about the different individual loads of the system. In this paper, we present a novel approach based on the encoder-decoder deep learning framework with an attention mechanism for solving NILM. The attention mechanism is inspired by the temporal attention mechanism that has been recently applied to get state-of-the-art results in neural machine translation, text summarization and speech recognition. The experiments have been conducted on two publicly available datasets AMPds and UK-DALE in seen and unseen conditions. The results show that our proposed deep neural network outperforms the state-of-the-art Denoising Auto-Encoder (DAE) proposed initially by Kelly and Knottenbely (2015) and its extended and improved architecture by Bonfigli et al. (2018), in all the addressed experimental conditions. We also show that modeling attention translates into the ability to correctly detect the state change of each appliance, that is of extreme interest in the field of energy disaggregation.