 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Equivariant Networks with Probabilistic Symmetry Breaking
Mar 27, 2025Equivariance encodes known symmetries into neural networks, often enhancing generalization. However, equivariant networks cannot break symmetries: the output of an equivariant network must, by definition, have at least the same self-symmetries as the input. This poses an important problem, both (1) for prediction tasks on domains where self-symmetries are common, and (2) for generative models, which must break symmetries in order to reconstruct from highly symmetric latent spaces. This fundamental limitation can be addressed by considering equivariant conditional distributions, instead of equivariant functions. We present novel theoretical results that establish necessary and sufficient conditions for representing such distributions. Concretely, this representation provides a practical framework for breaking symmetries in any equivariant network via randomized canonicalization. Our method, SymPE (Symmetry-breaking Positional Encodings), admits a simple interpretation in terms of positional encodings. This approach expands the representational power of equivariant networks while retaining the inductive bias of symmetry, which we justify through generalization bounds. Experimental results demonstrate that SymPE significantly improves performance of group-equivariant and graph neural networks across diffusion models for graphs, graph autoencoders, and lattice spin system modeling.
A tradeoff between universality of equivariant models and learnability of symmetries
Oct 17, 2022We prove an impossibility result, which in the context of function learning says the following: under certain conditions, it is impossible to simultaneously learn symmetries and functions equivariant under them using an ansatz consisting of equivariant functions. To formalize this statement, we carefully study notions of approximation for groups and semigroups. We analyze certain families of neural networks for whether they satisfy the conditions of the impossibility result: what we call ``linearly equivariant'' networks, and group-convolutional networks. A lot can be said precisely about linearly equivariant networks, making them theoretically useful. On the practical side, our analysis of group-convolutional neural networks allows us generalize the well-known ``convolution is all you need'' theorem to non-homogeneous spaces. We additionally find an important difference between group convolution and semigroup convolution.
Representation Learning with Multisets
Nov 19, 2019
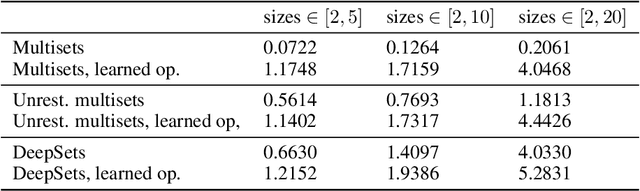


We study the problem of learning permutation invariant representations that can capture "flexible" notions of containment. We formalize this problem via a measure theoretic definition of multisets, and obtain a theoretically-motivated learning model. We propose training this model on a novel task: predicting the size of the symmetric difference (or intersection) between pairs of multisets. We demonstrate that our model not only performs very well on predicting containment relations (and more effectively predicts the sizes of symmetric differences and intersections than DeepSets-based approaches with unconstrained object representations), but that it also learns meaningful representations.