 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison analysis between standard polysomnographic data and in-ear-EEG signals: A preliminary study
Jan 30, 2024
Study Objectives: Polysomnography (PSG) currently serves as the benchmark for evaluating sleep disorders. Its discomfort, impracticality for home-use, and introduction of bias in sleep quality assessment necessitate the exploration of less invasive, cost-effective, and portable alternatives. One promising contender is the in-ear-EEG sensor, which offers advantages in terms of comfort, fixed electrode positions, resistance to electromagnetic interference, and user-friendliness. This study aims to establish a methodology to assess the similarity between the in-ear-EEG signal and standard PSG. Methods: We assess the agreement between the PSG and in-ear-EEG derived hypnograms. We extract features in the time- and frequency- domain from PSG and in-ear-EEG 30-second epochs. We only consider the epochs where the PSG-scorers and the in-ear-EEG-scorers were in agreement. We introduce a methodology to quantify the similarity between PSG derivations and the single-channel in-ear-EEG. The approach relies on a comparison of distributions of selected features -- extracted for each sleep stage and subject on both PSG and the in-ear-EEG signals -- via a Jensen-Shannon Divergence Feature-based Similarity Index (JSD-FSI). Results: We found a high intra-scorer variability, mainly due to the uncertainty the scorers had in evaluating the in-ear-EEG signals. We show that the similarity between PSG and in-ear-EEG signals is high (JSD-FSI: 0.61 +/- 0.06 in awake, 0.60 +/- 0.07 in NREM and 0.51 +/- 0.08 in REM), and in line with the similarity values computed independently on standard PSG-channel-combinations. Conclusions: In-ear-EEG is a valuable solution for home-based sleep monitoring, however further studies with a larger and more heterogeneous dataset are needed.
Deep Learning for real-time neural decoding of grasp
Nov 02, 2023Neural decoding involves correlating signals acquired from the brain to variables in the physical world like limb movement or robot control in Brain Machine Interfaces. In this context, this work starts from a specific pre-existing dataset of neural recordings from monkey motor cortex and presents a Deep Learning-based approach to the decoding of neural signals for grasp type classification. Specifically, we propose here an approach that exploits LSTM networks to classify time series containing neural data (i.e., spike trains) into classes representing the object being grasped. The main goal of the presented approach is to improve over state-of-the-art decoding accuracy without relying on any prior neuroscience knowledge, and leveraging only the capability of deep learning models to extract correlations from data. The paper presents the results achieved for the considered dataset and compares them with previous works on the same dataset, showing a significant improvement in classification accuracy, even if considering simulated real-time decoding.
Multi-Scored Sleep Databases: How to Exploit the Multiple-Labels in Automated Sleep Scoring
Jul 06, 2022
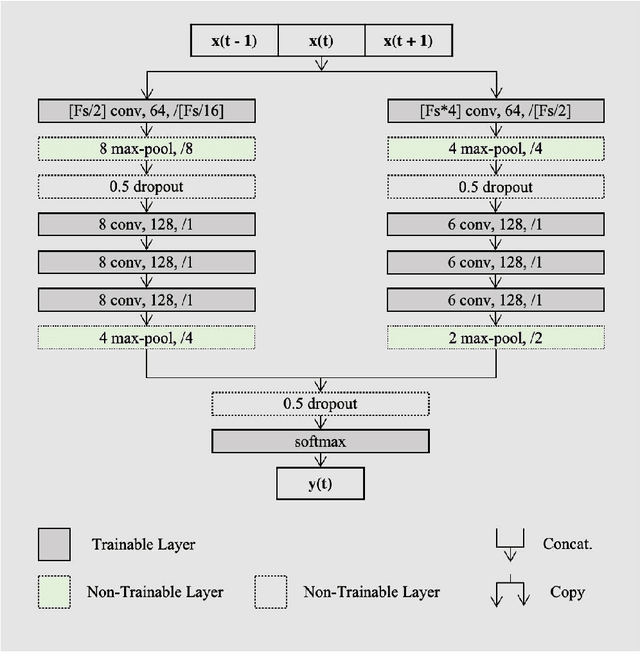
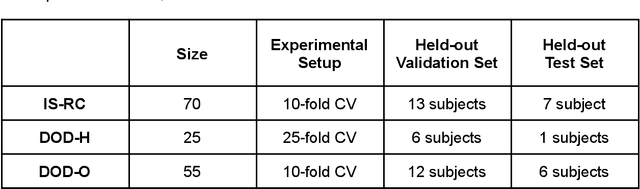
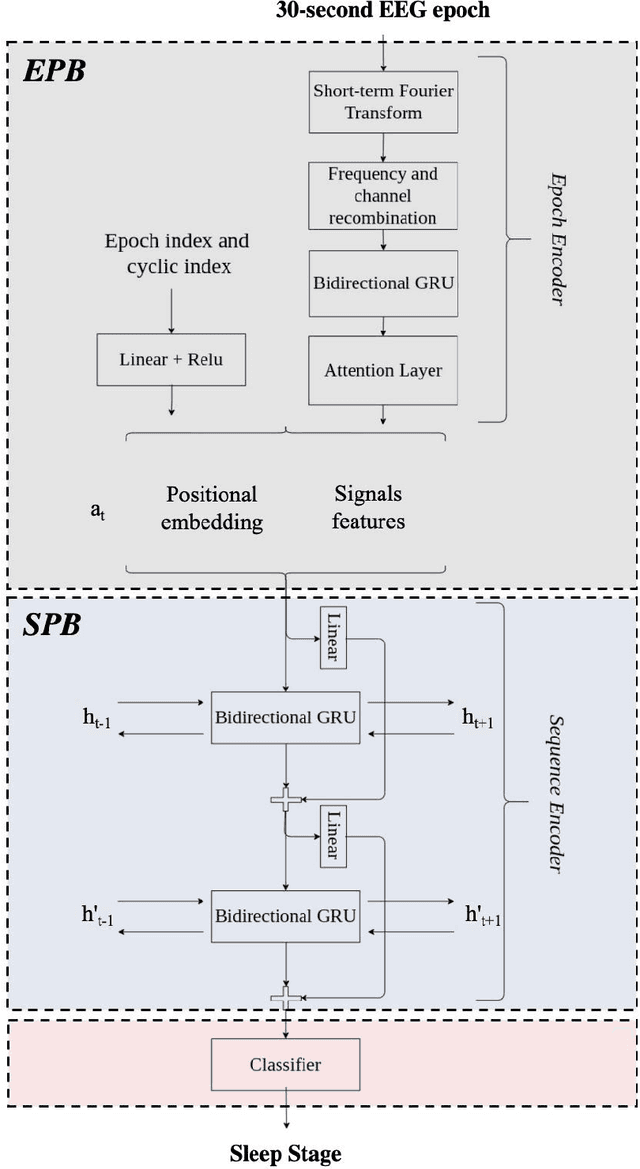
Study Objectives: Inter-scorer variability in scoring polysomnograms is a well-known problem. Most of the existing automated sleep scoring systems are trained using labels annotated by a single scorer, whose subjective evaluation is transferred to the model. When annotations from two or more scorers are available, the scoring models are usually trained on the scorer consensus. The averaged scorer's subjectivity is transferred into the model, losing information about the internal variability among different scorers. In this study, we aim to insert the multiple-knowledge of the different physicians into the training procedure.The goal is to optimize a model training, exploiting the full information that can be extracted from the consensus of a group of scorers. Methods: We train two lightweight deep learning based models on three different multi-scored databases. We exploit the label smoothing technique together with a soft-consensus (LSSC) distribution to insert the multiple-knowledge in the training procedure of the model. We introduce the averaged cosine similarity metric (ACS) to quantify the similarity between the hypnodensity-graph generated by the models with-LSSC and the hypnodensity-graph generated by the scorer consensus. Results: The performance of the models improves on all the databases when we train the models with our LSSC. We found an increase in ACS (up to 6.4%) between the hypnodensity-graph generated by the models trained with-LSSC and the hypnodensity-graph generated by the consensus. Conclusions: Our approach definitely enables a model to better adapt to the consensus of the group of scorers. Future work will focus on further investigations on different scoring architectures.