 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Boosted Ensembling in Multi-Modal Settings
Apr 21, 2021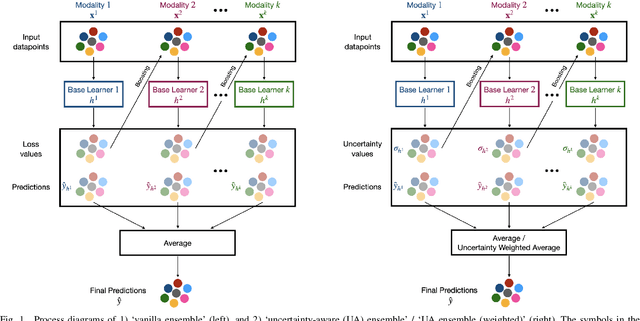
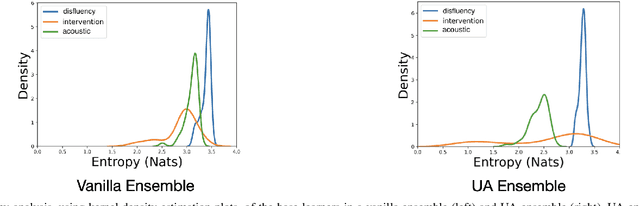
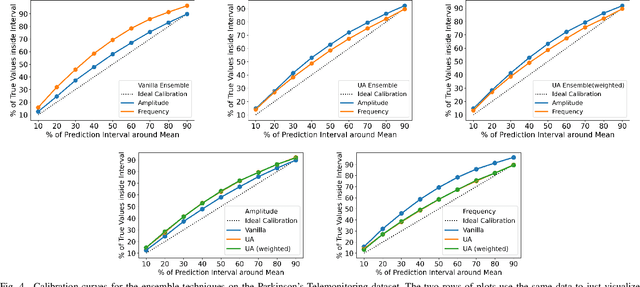

Reliability of machine learning (ML) systems is crucial in safety-critical applications such as healthcare, and uncertainty estimation is a widely researched method to highlight the confidence of ML systems in deployment. Sequential and parallel ensemble techniques have shown improved performance of ML systems in multi-modal settings by leveraging the feature sets together. We propose an uncertainty-aware boosting technique for multi-modal ensembling in order to focus on the data points with higher associated uncertainty estimates, rather than the ones with higher loss values. We evaluate this method on healthcare tasks related to Dementia and Parkinson's disease which involve real-world multi-modal speech and text data, wherein our method shows an improved performance. Additional analysis suggests that introducing uncertainty-awareness into the boosted ensembles decreases the overall entropy of the system, making it more robust to heteroscedasticity in the data, as well as better calibrating each of the modalities along with high quality prediction intervals. We open-source our entire codebase at https://github.com/usarawgi911/Uncertainty-aware-boosting
Robustness to Missing Features using Hierarchical Clustering with Split Neural Networks
Nov 19, 2020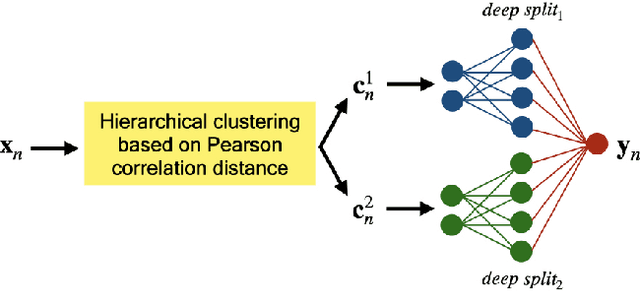
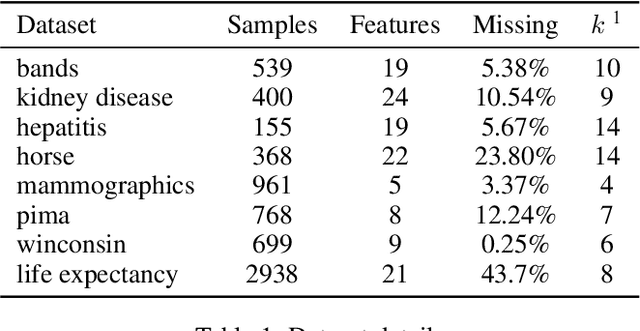
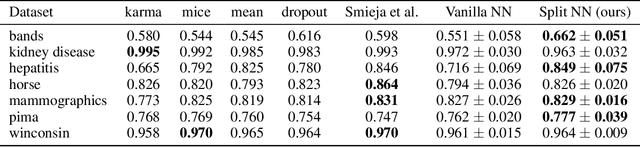
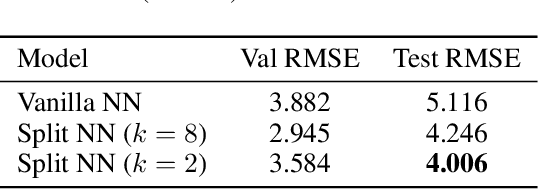
The problem of missing data has been persistent for a long time and poses a major obstacle in machine learning and statistical data analysis. Past works in this field have tried using various data imputation techniques to fill in the missing data, or training neural networks (NNs) with the missing data. In this work, we propose a simple yet effective approach that clusters similar input features together using hierarchical clustering and then trains proportionately split neural networks with a joint loss. We evaluate this approach on a series of benchmark datasets and show promising improvements even with simple imputation techniques. We attribute this to learning through clusters of similar features in our model architecture. The source code is available at https://github.com/usarawgi911/Robustness-to-Missing-Features
Uncertainty-Aware Multi-Modal Ensembling for Severity Prediction of Alzheimer's Dementia
Oct 03, 2020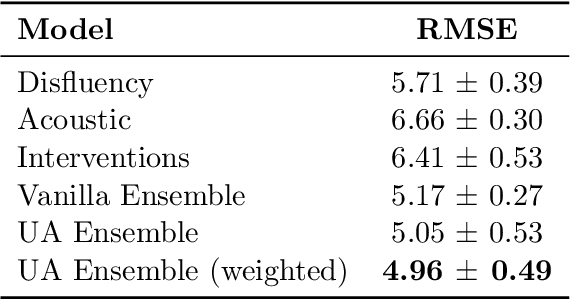
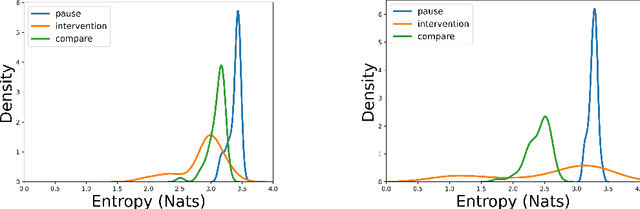

Reliability in Neural Networks (NNs) is crucial in safety-critical applications like healthcare, and uncertainty estimation is a widely researched method to highlight the confidence of NNs in deployment. In this work, we propose an uncertainty-aware boosting technique for multi-modal ensembling to predict Alzheimer's Dementia Severity. The propagation of uncertainty across acoustic, cognitive, and linguistic features produces an ensemble system robust to heteroscedasticity in the data. Weighing the different modalities based on the uncertainty estimates, we experiment on the benchmark ADReSS dataset, a subject-independent and balanced dataset, to show that our method outperforms the state-of-the-art methods while also reducing the overall entropy of the system. This work aims to encourage fair and aware models. The source code is available at https://github.com/wazeerzulfikar/alzheimers-dementia
Why have a Unified Predictive Uncertainty? Disentangling it using Deep Split Ensembles
Sep 25, 2020
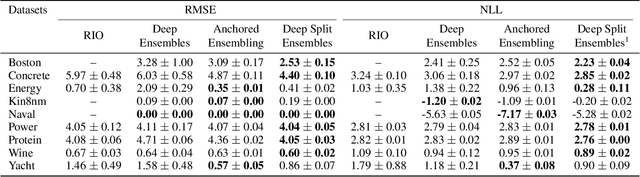
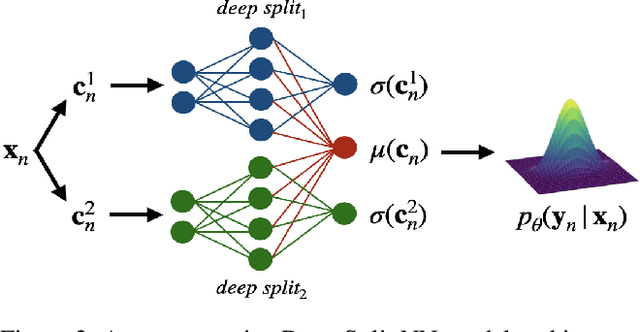
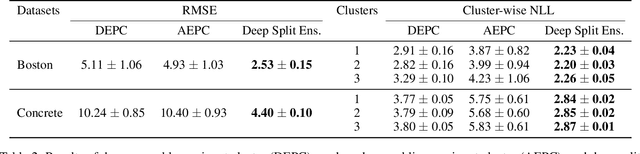
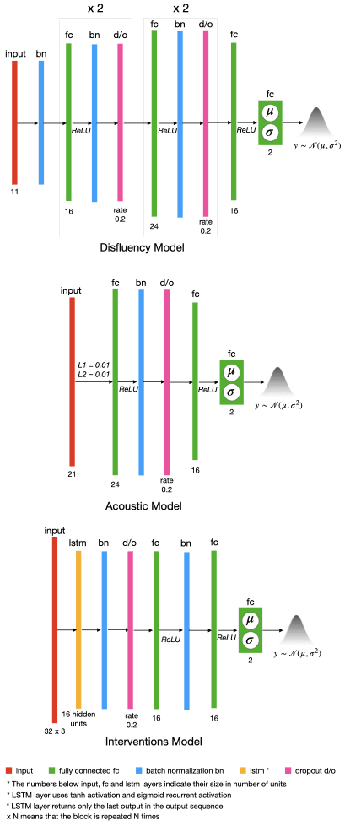
Understanding and quantifying uncertainty in black box Neural Networks (NNs) is critical when deployed in real-world settings such as healthcare. Recent works using Bayesian and non-Bayesian methods have shown how a unified predictive uncertainty can be modelled for NNs. Decomposing this uncertainty to disentangle the granular sources of heteroscedasticity in data provides rich information about its underlying causes. We propose a conceptually simple non-Bayesian approach, deep split ensemble, to disentangle the predictive uncertainties using a multivariate Gaussian mixture model. The NNs are trained with clusters of input features, for uncertainty estimates per cluster. We evaluate our approach on a series of benchmark regression datasets, while also comparing with unified uncertainty methods. Extensive analyses using dataset shits and empirical rule highlight our inherently well-calibrated models. Our work further demonstrates its applicability in a multi-modal setting using a benchmark Alzheimer's dataset and also shows how deep split ensembles can highlight hidden modality-specific biases. The minimal changes required to NNs and the training procedure, and the high flexibility to group features into clusters makes it readily deployable and useful. The source code is available at https://github.com/wazeerzulfikar/deep-split-ensembles
Multimodal Inductive Transfer Learning for Detection of Alzheimer's Dementia and its Severity
Aug 30, 2020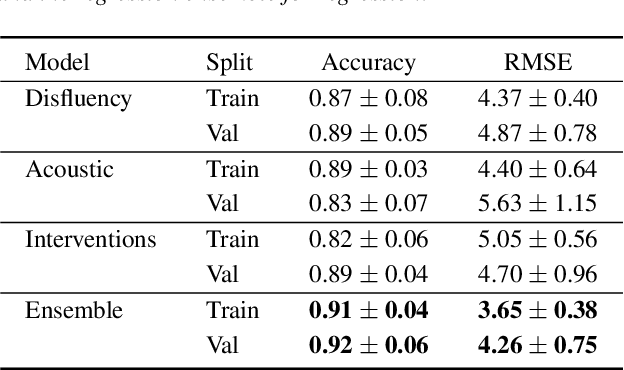
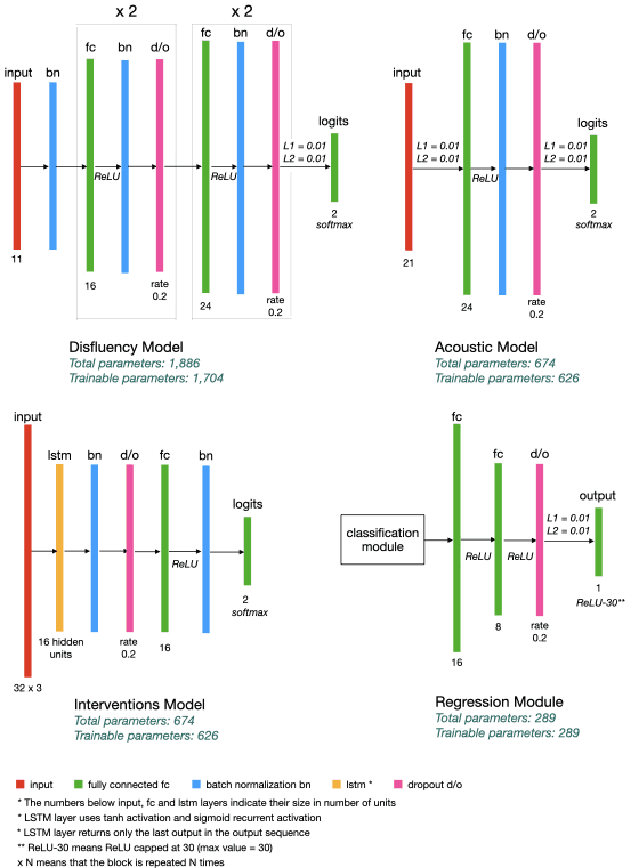
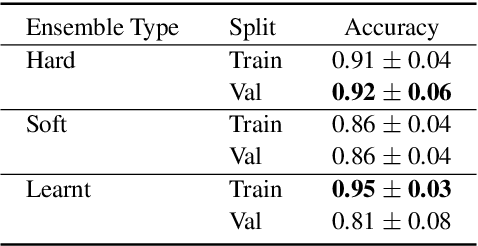
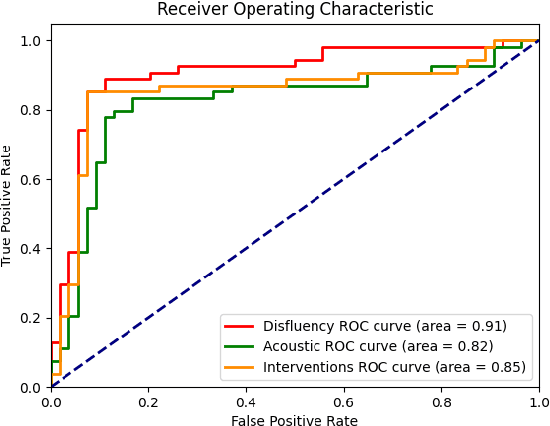
Alzheimer's disease is estimated to affect around 50 million people worldwide and is rising rapidly, with a global economic burden of nearly a trillion dollars. This calls for scalable, cost-effective, and robust methods for detection of Alzheimer's dementia (AD). We present a novel architecture that leverages acoustic, cognitive, and linguistic features to form a multimodal ensemble system. It uses specialized artificial neural networks with temporal characteristics to detect AD and its severity, which is reflected through Mini-Mental State Exam (MMSE) scores. We first evaluate it on the ADReSS challenge dataset, which is a subject-independent and balanced dataset matched for age and gender to mitigate biases, and is available through DementiaBank. Our system achieves state-of-the-art test accuracy, precision, recall, and F1-score of 83.3% each for AD classification, and state-of-the-art test root mean squared error (RMSE) of 4.60 for MMSE score regression. To the best of our knowledge, the system further achieves state-of-the-art AD classification accuracy of 88.0% when evaluated on the full benchmark DementiaBank Pitt database. Our work highlights the applicability and transferability of spontaneous speech to produce a robust inductive transfer learning model, and demonstrates generalizability through a task-agnostic feature-space. The source code is available at https://github.com/wazeerzulfikar/alzheimers-dementia