 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccuracy of TextFooler black box adversarial attacks on 01 loss sign activation neural network ensemble
Feb 12, 2024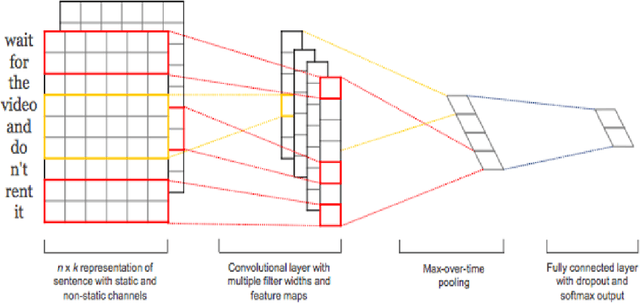
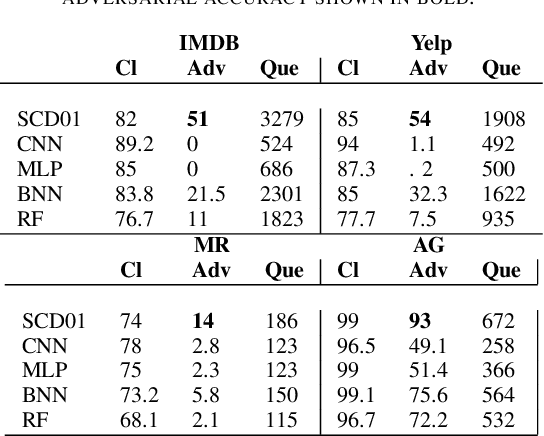
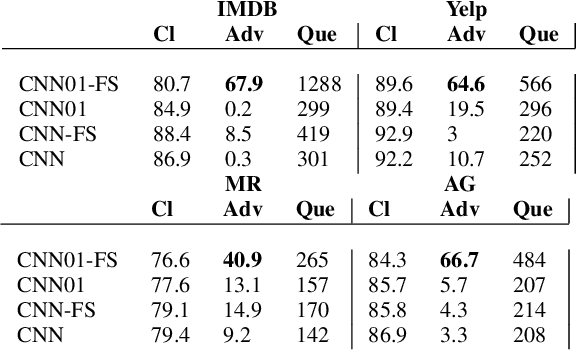
Recent work has shown the defense of 01 loss sign activation neural networks against image classification adversarial attacks. A public challenge to attack the models on CIFAR10 dataset remains undefeated. We ask the following question in this study: are 01 loss sign activation neural networks hard to deceive with a popular black box text adversarial attack program called TextFooler? We study this question on four popular text classification datasets: IMDB reviews, Yelp reviews, MR sentiment classification, and AG news classification. We find that our 01 loss sign activation network is much harder to attack with TextFooler compared to sigmoid activation cross entropy and binary neural networks. We also study a 01 loss sign activation convolutional neural network with a novel global pooling step specific to sign activation networks. With this new variation we see a significant gain in adversarial accuracy rendering TextFooler practically useless against it. We make our code freely available at \url{https://github.com/zero-one-loss/wordcnn01} and \url{https://github.com/xyzacademic/mlp01example}. Our work here suggests that 01 loss sign activation networks could be further developed to create fool proof models against text adversarial attacks.
A Cascaded Neural Network System For Rating Student Performance In Surgical Knot Tying Simulation
Dec 09, 2023


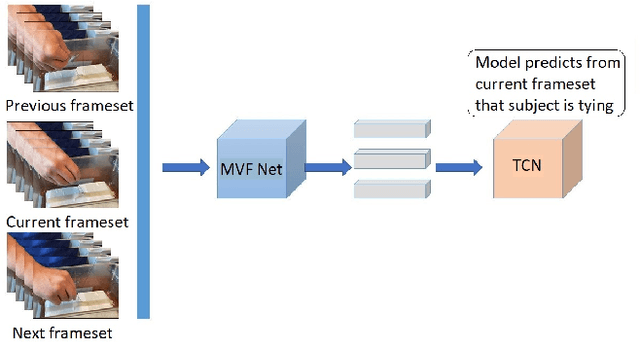
As part of their training all medical students and residents have to pass basic surgical tasks such as knot tying, needle-passing, and suturing. Their assessment is typically performed in the operating room by surgical faculty where mistakes and failure by the student increases the operation time and cost. This evaluation is quantitative and has a low margin of error. Simulation has emerged as a cost effective option but it lacks assessment or requires additional expensive hardware for evaluation. Apps that provide training videos on surgical knot trying are available to students but none have evaluation. We propose a cascaded neural network architecture that evaluates a student's performance just from a video of themselves simulating a surgical knot tying task. Our model converts video frame images into feature vectors with a pre-trained deep convolutional network and then models the sequence of frames with a temporal network. We obtained videos of medical students and residents from the Robert Wood Johnson Hospital performing knot tying on a standardized simulation kit. We manually annotated each video and proceeded to do a five-fold cross-validation study on them. Our model achieves a median precision, recall, and F1-score of 0.71, 0.66, and 0.65 respectively in determining the level of knot related tasks of tying and pushing the knot. Our mean precision score averaged across different probability thresholds is 0.8. Both our F1-score and mean precision score are 8% and 30% higher than that of a recently published study for the same problem. We expect the accuracy of our model to further increase as we add more training videos to the model thus making it a practical solution that students can use to evaluate themselves.
Defending against substitute model black box adversarial attacks with the 01 loss
Sep 01, 2020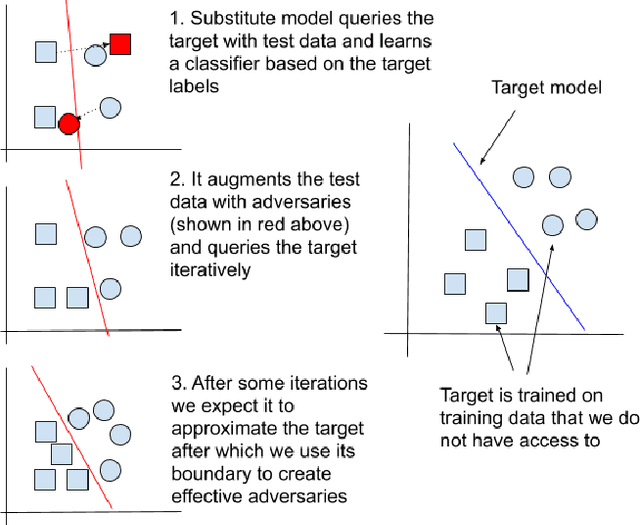

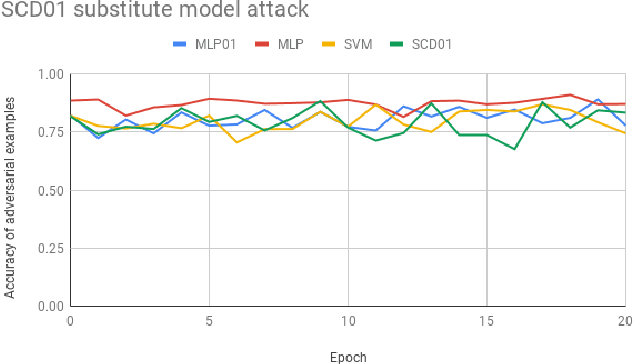
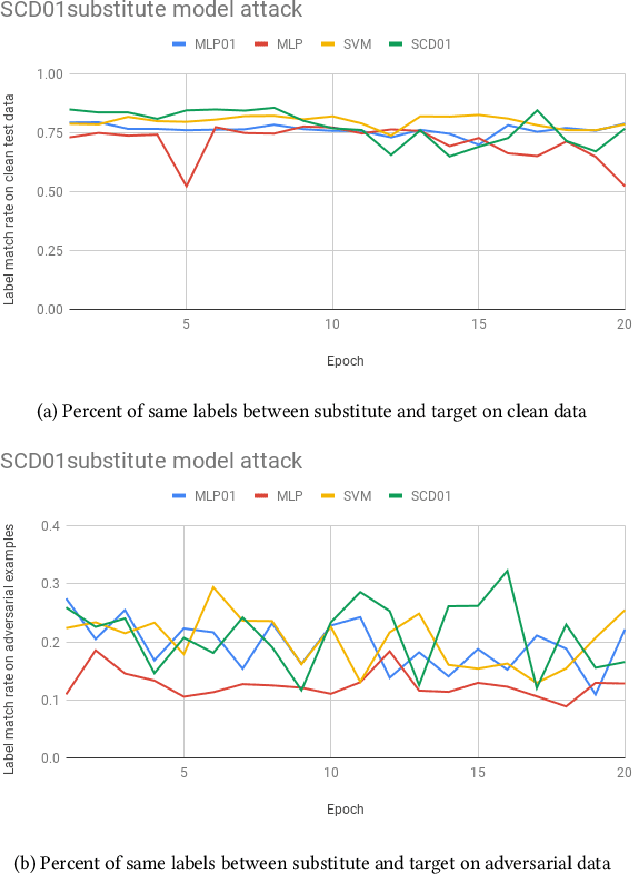
Substitute model black box attacks can create adversarial examples for a target model just by accessing its output labels. This poses a major challenge to machine learning models in practice, particularly in security sensitive applications. The 01 loss model is known to be more robust to outliers and noise than convex models that are typically used in practice. Motivated by these properties we present 01 loss linear and 01 loss dual layer neural network models as a defense against transfer based substitute model black box attacks. We compare the accuracy of adversarial examples from substitute model black box attacks targeting our 01 loss models and their convex counterparts for binary classification on popular image benchmarks. Our 01 loss dual layer neural network has an adversarial accuracy of 66.2%, 58%, 60.5%, and 57% on MNIST, CIFAR10, STL10, and ImageNet respectively whereas the sigmoid activated logistic loss counterpart has accuracies of 63.5%, 19.3%, 14.9%, and 27.6%. Except for MNIST the convex counterparts have substantially lower adversarial accuracies. We show practical applications of our models to deter traffic sign and facial recognition adversarial attacks. On GTSRB street sign and CelebA facial detection our 01 loss network has 34.6% and 37.1% adversarial accuracy respectively whereas the convex logistic counterpart has accuracy 24% and 1.9%. Finally we show that our 01 loss network can attain robustness on par with simple convolutional neural networks and much higher than its convex counterpart even when attacked with a convolutional network substitute model. Our work shows that 01 loss models offer a powerful defense against substitute model black box attacks.
Towards adversarial robustness with 01 loss neural networks
Aug 20, 2020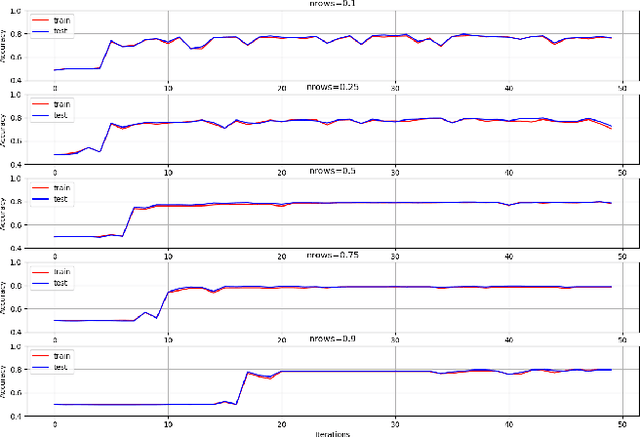


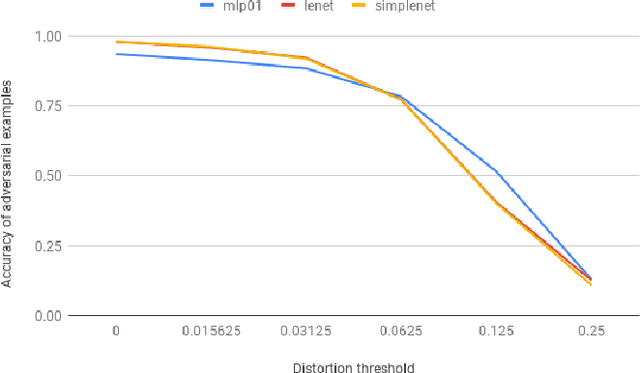
Motivated by the general robustness properties of the 01 loss we propose a single hidden layer 01 loss neural network trained with stochastic coordinate descent as a defense against adversarial attacks in machine learning. One measure of a model's robustness is the minimum distortion required to make the input adversarial. This can be approximated with the Boundary Attack (Brendel et. al. 2018) and HopSkipJump (Chen et. al. 2019) methods. We compare the minimum distortion of the 01 loss network to the binarized neural network and the standard sigmoid activation network with cross-entropy loss all trained with and without Gaussian noise on the CIFAR10 benchmark binary classification between classes 0 and 1. Both with and without noise training we find our 01 loss network to have the largest adversarial distortion of the three models by non-trivial margins. To further validate these results we subject all models to substitute model black box attacks under different distortion thresholds and find that the 01 loss network is the hardest to attack across all distortions. At a distortion of 0.125 both sigmoid activated cross-entropy loss and binarized networks have almost 0% accuracy on adversarial examples whereas the 01 loss network is at 40%. Even though both 01 loss and the binarized network use sign activations their training algorithms are different which in turn give different solutions for robustness. Finally we compare our network to simple convolutional models under substitute model black box attacks and find their accuracies to be comparable. Our work shows that the 01 loss network has the potential to defend against black box adversarial attacks better than convex loss and binarized networks.
On the transferability of adversarial examples between convex and 01 loss models
Jun 14, 2020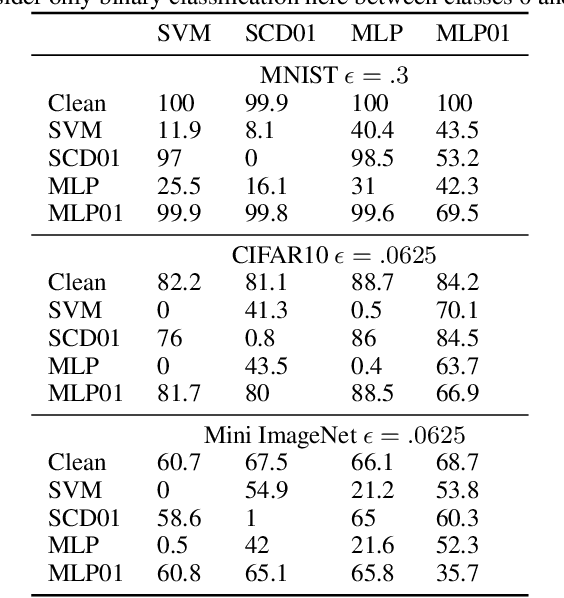
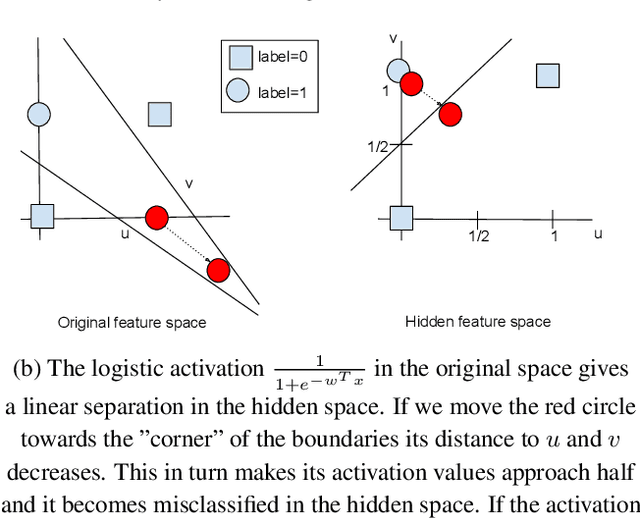


We show that white box adversarial examples do not transfer effectively between convex and 01 loss and between 01 loss models compared to between convex models. We also show that convex substitute model black box attacks are less effective on 01 loss than convex models, and that 01 loss substitute model attacks are ineffective on both convex and 01 loss models. We show intuitively by example how the presence of outliers can cause different decision boundaries between 01 and convex loss models which in turn produces adversaries that are non-transferable. Indeed we see on MNIST that adversaries transfer between 01 loss and convex models more easily than on CIFAR10 and ImageNet which are likely to contain outliers. We also show intuitively by example how the non-continuity of 01 loss makes adversaries non-transferable in a two layer neural network.
Robust binary classification with the 01 loss
Feb 09, 2020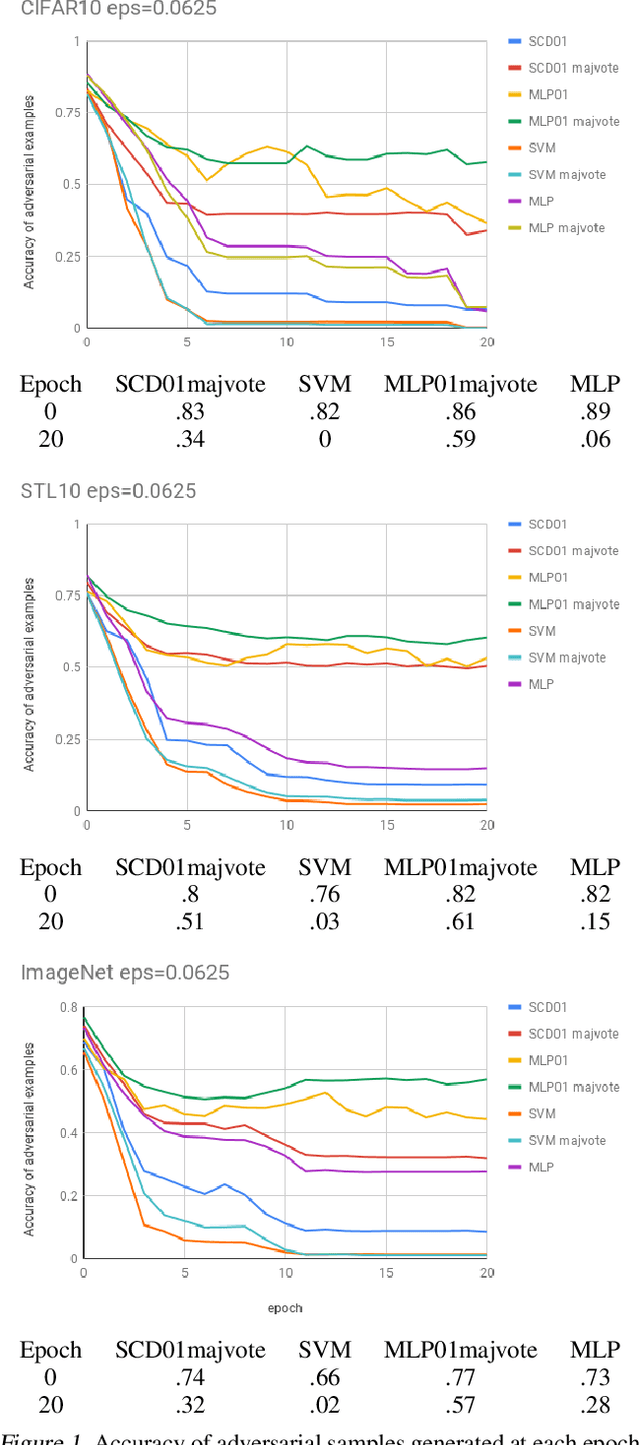
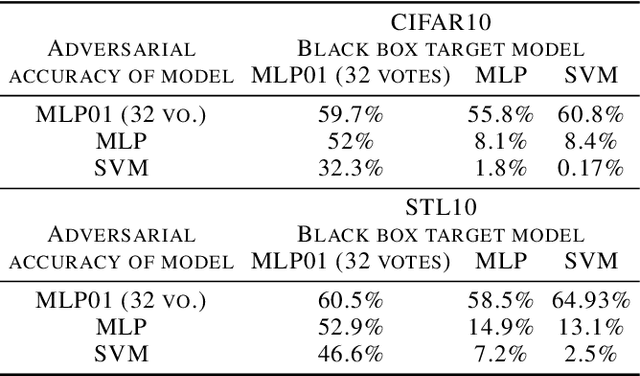

The 01 loss is robust to outliers and tolerant to noisy data compared to convex loss functions. We conjecture that the 01 loss may also be more robust to adversarial attacks. To study this empirically we have developed a stochastic coordinate descent algorithm for a linear 01 loss classifier and a single hidden layer 01 loss neural network. Due to the absence of the gradient we iteratively update coordinates on random subsets of the data for fixed epochs. We show our algorithms to be fast and comparable in accuracy to the linear support vector machine and logistic loss single hidden layer network for binary classification on several image benchmarks, thus establishing that our method is on-par in test accuracy with convex losses. We then subject them to accurately trained substitute model black box attacks on the same image benchmarks and find them to be more robust than convex counterparts. On CIFAR10 binary classification task between classes 0 and 1 with adversarial perturbation of 0.0625 we see that the MLP01 network loses 27\% in accuracy whereas the MLP-logistic counterpart loses 83\%. Similarly on STL10 and ImageNet binary classification between classes 0 and 1 the MLP01 network loses 21\% and 20\% while MLP-logistic loses 67\% and 45\% respectively. On MNIST that is a well-separable dataset we find MLP01 comparable to MLP-logistic and show under simulation how and why our 01 loss solver is less robust there. We then propose adversarial training for our linear 01 loss solver that significantly improves its robustness on MNIST and all other datasets and retains clean test accuracy. Finally we show practical applications of our method to deter traffic sign and facial recognition adversarial attacks. We discuss attacks with 01 loss, substitute model accuracy, and several future avenues like multiclass, 01 loss convolutions, and further adversarial training.
Image classification and retrieval with random depthwise signed convolutional neural networks
Oct 09, 2018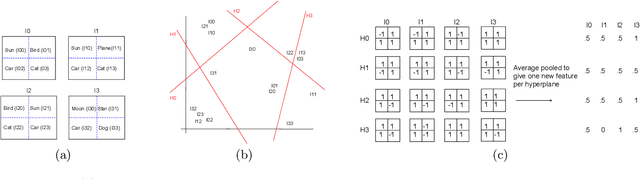
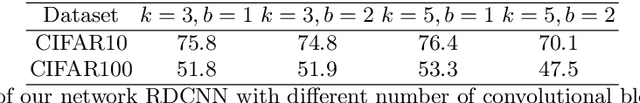
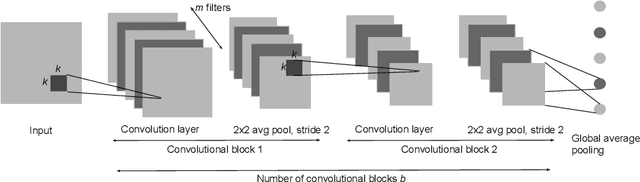
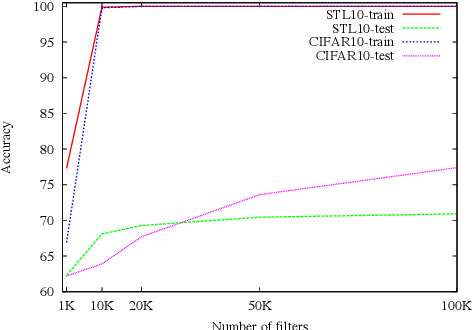
We study image classification and retrieval performance in a feature space given by random depthwise convolutional neural networks. Intuitively our network can be interpreted as applying random hyperplanes to the space of all patches of input images followed by average pooling to obtain final features. We show that the ratio of image pixel distribution similarity across classes to within classes and the average margin of the linear support vector machine on test data are both higher in our network's final layer compared to the input space. We then apply the linear support vector machine for image classification and $k$-nearest neighbor for image similarity detection on our network's final layer. We show that for classification our network attains higher accuracies than previous random networks and is not far behind in accuracy to trained state of the art networks, especially in the top-k setting. For example the top-2 accuracy of our network is near 90\% on both CIFAR10 and a 10-class mini ImageNet, and 85\% on STL10. In the problem of image similarity we find that $k$-nearest neighbor gives a comparable precision on the Corel Princeton Image Similarity Benchmark than if we were to use the last hidden layer of trained networks. We highlight sensitivity of our network to background color as a potential pitfall. Overall our work pushes the boundary of what can be achieved with random weights.