 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixRec: Heterogeneous Graph Collaborative Filtering
Dec 22, 2024



For modern recommender systems, the use of low-dimensional latent representations to embed users and items based on their observed interactions has become commonplace. However, many existing recommendation models are primarily designed for coarse-grained and homogeneous interactions, which limits their effectiveness in two critical dimensions. Firstly, these models fail to leverage the relational dependencies that exist across different types of user behaviors, such as page views, collects, comments, and purchases. Secondly, they struggle to capture the fine-grained latent factors that drive user interaction patterns. To address these limitations, we present a heterogeneous graph collaborative filtering model MixRec that excels at disentangling users' multi-behavior interaction patterns and uncovering the latent intent factors behind each behavior. Our model achieves this by incorporating intent disentanglement and multi-behavior modeling, facilitated by a parameterized heterogeneous hypergraph architecture. Furthermore, we introduce a novel contrastive learning paradigm that adaptively explores the advantages of self-supervised data augmentation, thereby enhancing the model's resilience against data sparsity and expressiveness with relation heterogeneity. To validate the efficacy of MixRec, we conducted extensive experiments on three public datasets. The results clearly demonstrate its superior performance, significantly outperforming various state-of-the-art baselines. Our model is open-sourced and available at: https://github.com/HKUDS/MixRec.
Defending against substitute model black box adversarial attacks with the 01 loss
Sep 01, 2020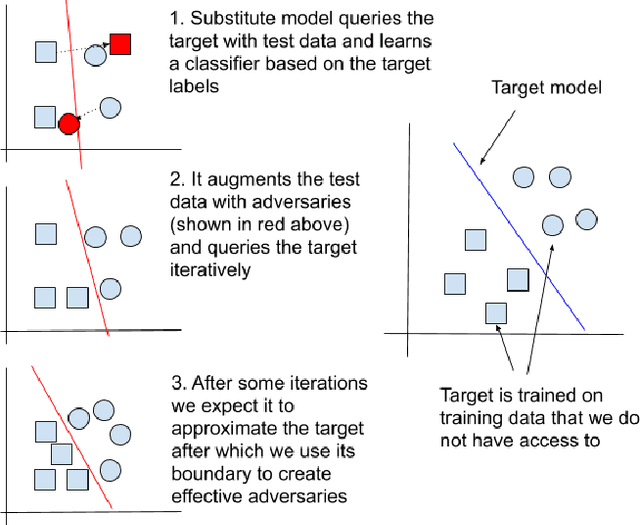

Substitute model black box attacks can create adversarial examples for a target model just by accessing its output labels. This poses a major challenge to machine learning models in practice, particularly in security sensitive applications. The 01 loss model is known to be more robust to outliers and noise than convex models that are typically used in practice. Motivated by these properties we present 01 loss linear and 01 loss dual layer neural network models as a defense against transfer based substitute model black box attacks. We compare the accuracy of adversarial examples from substitute model black box attacks targeting our 01 loss models and their convex counterparts for binary classification on popular image benchmarks. Our 01 loss dual layer neural network has an adversarial accuracy of 66.2%, 58%, 60.5%, and 57% on MNIST, CIFAR10, STL10, and ImageNet respectively whereas the sigmoid activated logistic loss counterpart has accuracies of 63.5%, 19.3%, 14.9%, and 27.6%. Except for MNIST the convex counterparts have substantially lower adversarial accuracies. We show practical applications of our models to deter traffic sign and facial recognition adversarial attacks. On GTSRB street sign and CelebA facial detection our 01 loss network has 34.6% and 37.1% adversarial accuracy respectively whereas the convex logistic counterpart has accuracy 24% and 1.9%. Finally we show that our 01 loss network can attain robustness on par with simple convolutional neural networks and much higher than its convex counterpart even when attacked with a convolutional network substitute model. Our work shows that 01 loss models offer a powerful defense against substitute model black box attacks.
Towards adversarial robustness with 01 loss neural networks
Aug 20, 2020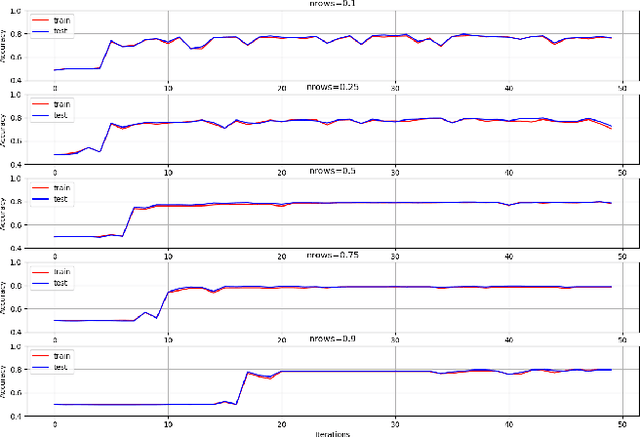


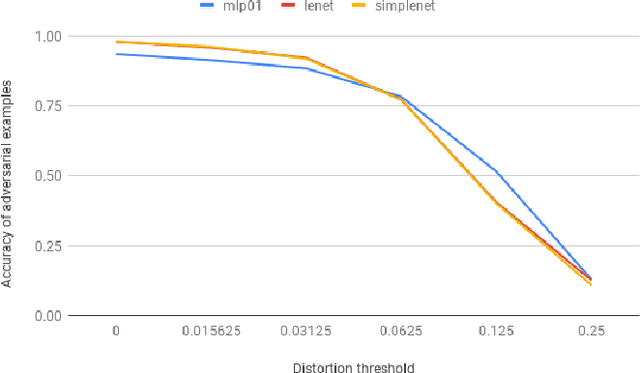
Motivated by the general robustness properties of the 01 loss we propose a single hidden layer 01 loss neural network trained with stochastic coordinate descent as a defense against adversarial attacks in machine learning. One measure of a model's robustness is the minimum distortion required to make the input adversarial. This can be approximated with the Boundary Attack (Brendel et. al. 2018) and HopSkipJump (Chen et. al. 2019) methods. We compare the minimum distortion of the 01 loss network to the binarized neural network and the standard sigmoid activation network with cross-entropy loss all trained with and without Gaussian noise on the CIFAR10 benchmark binary classification between classes 0 and 1. Both with and without noise training we find our 01 loss network to have the largest adversarial distortion of the three models by non-trivial margins. To further validate these results we subject all models to substitute model black box attacks under different distortion thresholds and find that the 01 loss network is the hardest to attack across all distortions. At a distortion of 0.125 both sigmoid activated cross-entropy loss and binarized networks have almost 0% accuracy on adversarial examples whereas the 01 loss network is at 40%. Even though both 01 loss and the binarized network use sign activations their training algorithms are different which in turn give different solutions for robustness. Finally we compare our network to simple convolutional models under substitute model black box attacks and find their accuracies to be comparable. Our work shows that the 01 loss network has the potential to defend against black box adversarial attacks better than convex loss and binarized networks.
On the transferability of adversarial examples between convex and 01 loss models
Jun 14, 2020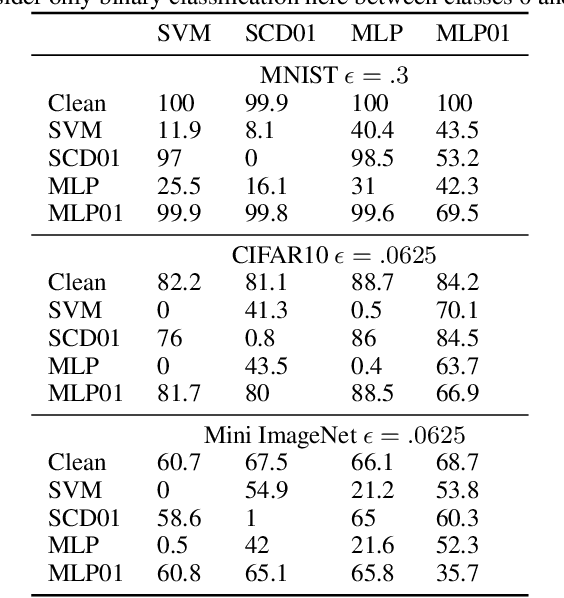
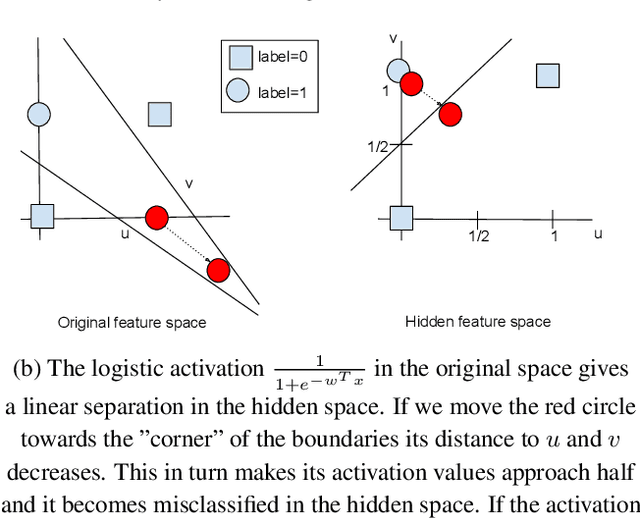


We show that white box adversarial examples do not transfer effectively between convex and 01 loss and between 01 loss models compared to between convex models. We also show that convex substitute model black box attacks are less effective on 01 loss than convex models, and that 01 loss substitute model attacks are ineffective on both convex and 01 loss models. We show intuitively by example how the presence of outliers can cause different decision boundaries between 01 and convex loss models which in turn produces adversaries that are non-transferable. Indeed we see on MNIST that adversaries transfer between 01 loss and convex models more easily than on CIFAR10 and ImageNet which are likely to contain outliers. We also show intuitively by example how the non-continuity of 01 loss makes adversaries non-transferable in a two layer neural network.
Robust binary classification with the 01 loss
Feb 09, 2020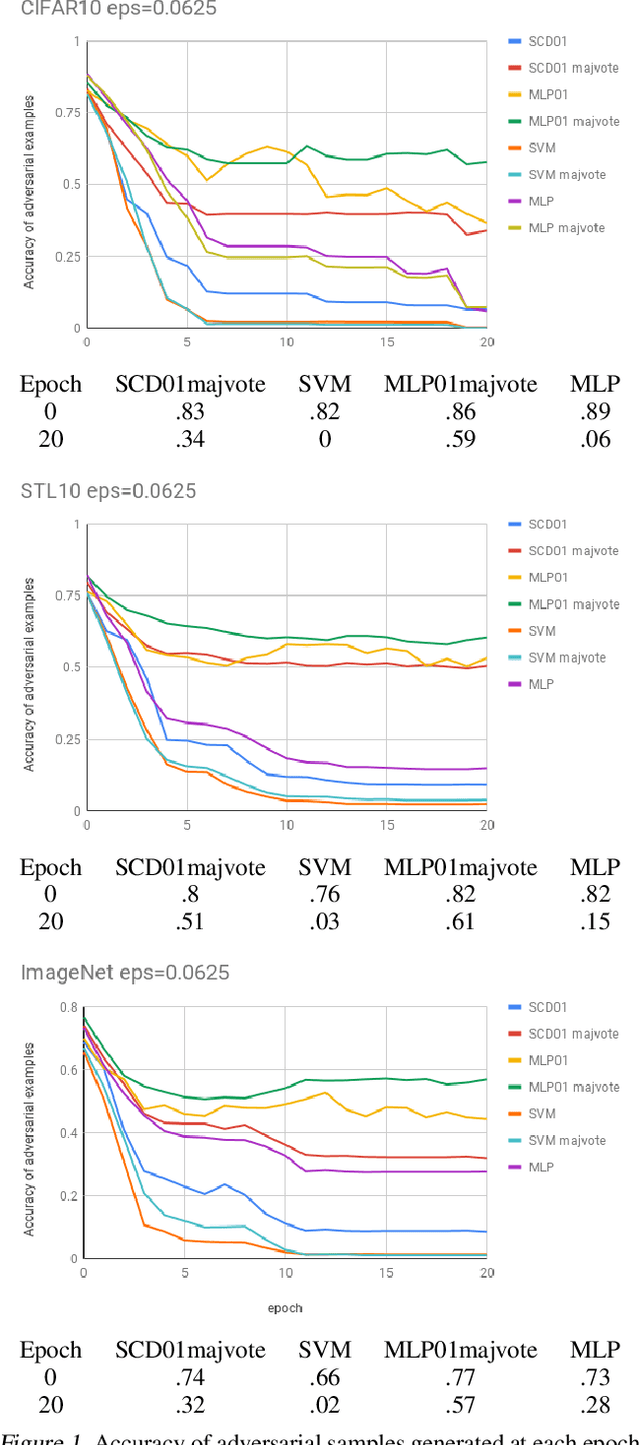
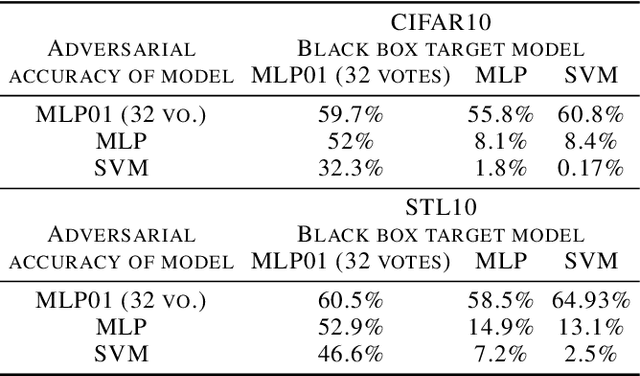

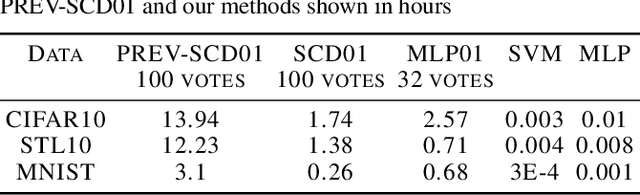
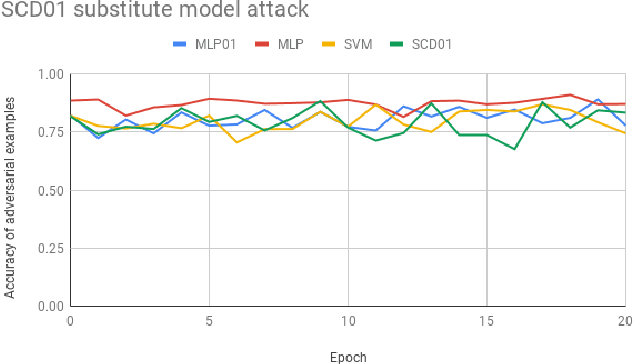
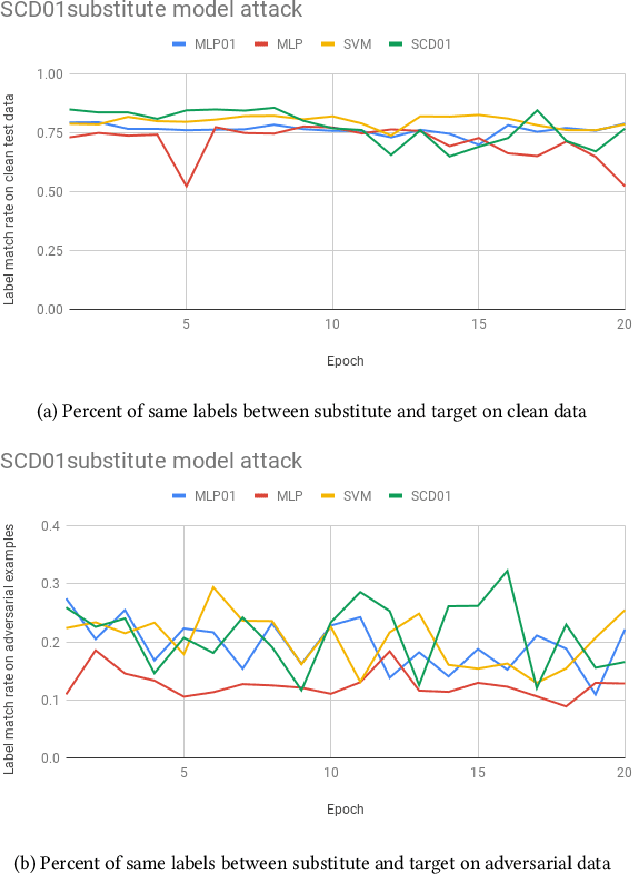
The 01 loss is robust to outliers and tolerant to noisy data compared to convex loss functions. We conjecture that the 01 loss may also be more robust to adversarial attacks. To study this empirically we have developed a stochastic coordinate descent algorithm for a linear 01 loss classifier and a single hidden layer 01 loss neural network. Due to the absence of the gradient we iteratively update coordinates on random subsets of the data for fixed epochs. We show our algorithms to be fast and comparable in accuracy to the linear support vector machine and logistic loss single hidden layer network for binary classification on several image benchmarks, thus establishing that our method is on-par in test accuracy with convex losses. We then subject them to accurately trained substitute model black box attacks on the same image benchmarks and find them to be more robust than convex counterparts. On CIFAR10 binary classification task between classes 0 and 1 with adversarial perturbation of 0.0625 we see that the MLP01 network loses 27\% in accuracy whereas the MLP-logistic counterpart loses 83\%. Similarly on STL10 and ImageNet binary classification between classes 0 and 1 the MLP01 network loses 21\% and 20\% while MLP-logistic loses 67\% and 45\% respectively. On MNIST that is a well-separable dataset we find MLP01 comparable to MLP-logistic and show under simulation how and why our 01 loss solver is less robust there. We then propose adversarial training for our linear 01 loss solver that significantly improves its robustness on MNIST and all other datasets and retains clean test accuracy. Finally we show practical applications of our method to deter traffic sign and facial recognition adversarial attacks. We discuss attacks with 01 loss, substitute model accuracy, and several future avenues like multiclass, 01 loss convolutions, and further adversarial training.
A fully 3D multi-path convolutional neural network with feature fusion and feature weighting for automatic lesion identification in brain MRI images
Jul 17, 2019


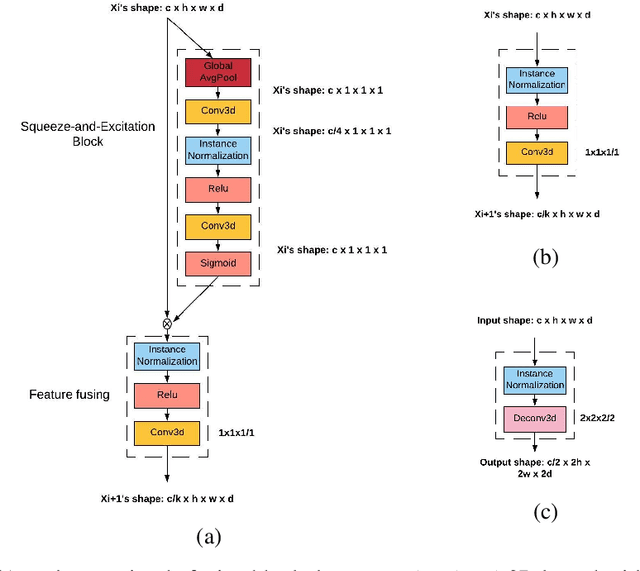
Brain MRI images consist of multiple 2D images stacked at consecutive spatial intervals to form a 3D structure. Thus it seems natural to use a convolutional neural network with 3D convolutional kernels that would automatically also account for spatial dependence between the slices. However, 3D models remain a challenge in practice due to overfitting caused by insufficient training data. For example in a 2D model we typically have 150-300 slices per patient per plane of orientation whereas in a 3D setting this gets reduced to just one point. Here we propose a fully 3D multi-path convolutional network with custom designed components to better utilize features from multiple modalities. In particular our multi-path model has independent encoders for different modalities containing residual convolutional blocks, weighted multi-path feature fusion from different modalities, and weighted fusion modules to combine encoder and decoder features. We provide intuitive reasoning for different components along with empirical evidence to show that they work. Compared to existing 3D CNNs like DeepMedic, 3D U-Net, and AnatomyNet, our networks achieves the highest statistically significant cross-validation accuracy of 60.5% on the large ATLAS benchmark of 220 patients. We also test our model on multi-modal images from the Kessler Foundation and Medical College Wisconsin and achieve a statistically significant cross-validation accuracy of 65%, significantly outperforming the multi-modal 3D U-Net and DeepMedic. Overall our model offers a principled, extensible multi-path approach that outperforms multi-channel alternatives and achieves high Dice accuracies on existing benchmarks.