Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Pairwise Disjoint Simple Languages from Positive Examples
Jun 06, 2017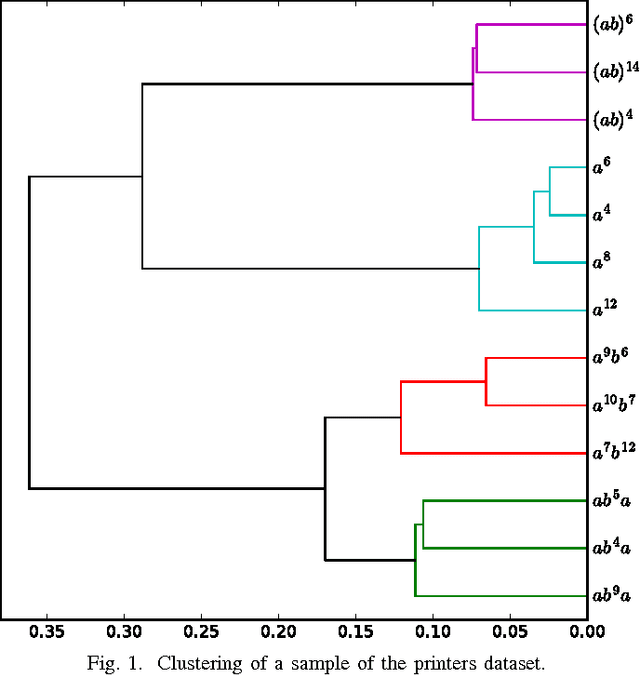


A classical problem in grammatical inference is to identify a deterministic finite automaton (DFA) from a set of positive and negative examples. In this paper, we address the related - yet seemingly novel - problem of identifying a set of DFAs from examples that belong to different unknown simple regular languages. We propose two methods based on compression for clustering the observed positive examples. We apply our methods to a set of print jobs submitted to large industrial printers.
* This paper has been accepted at the Learning and Automata (LearnAut)
Workshop, LICS 2017 (Reykjavik, Iceland)
Via