 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Input Strategies for Medulloblastoma Tumor Classification using Deep Transfer Learning
Sep 14, 2021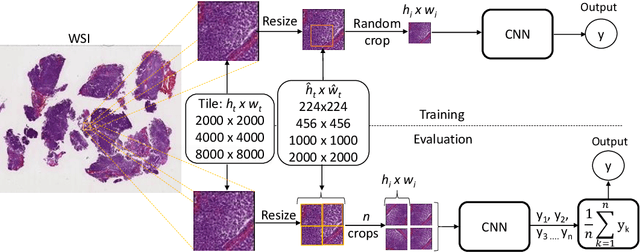
Medulloblastoma (MB) is a primary central nervous system tumor and the most common malignant brain cancer among children. Neuropathologists perform microscopic inspection of histopathological tissue slides under a microscope to assess the severity of the tumor. This is a time-consuming task and often infused with observer variability. Recently, pre-trained convolutional neural networks (CNN) have shown promising results for MB subtype classification. Typically, high-resolution images are divided into smaller tiles for classification, while the size of the tiles has not been systematically evaluated. We study the impact of tile size and input strategy and classify the two major histopathological subtypes-Classic and Demoplastic/Nodular. To this end, we use recently proposed EfficientNets and evaluate tiles with increasing size combined with various downsampling scales. Our results demonstrate using large input tiles pixels followed by intermediate downsampling and patch cropping significantly improves MB classification performance. Our top-performing method achieves the AUC-ROC value of 90.90\% compared to 84.53\% using the previous approach with smaller input tiles.
Medulloblastoma Tumor Classification using Deep Transfer Learning with Multi-Scale EfficientNets
Sep 10, 2021Medulloblastoma (MB) is the most common malignant brain tumor in childhood. The diagnosis is generally based on the microscopic evaluation of histopathological tissue slides. However, visual-only assessment of histopathological patterns is a tedious and time-consuming task and is also affected by observer variability. Hence, automated MB tumor classification could assist pathologists by promoting consistency and robust quantification. Recently, convolutional neural networks (CNNs) have been proposed for this task, while transfer learning has shown promising results. In this work, we propose an end-to-end MB tumor classification and explore transfer learning with various input sizes and matching network dimensions. We focus on differentiating between the histological subtypes classic and desmoplastic/nodular. For this purpose, we systematically evaluate recently proposed EfficientNets, which uniformly scale all dimensions of a CNN. Using a data set with 161 cases, we demonstrate that pre-trained EfficientNets with larger input resolutions lead to significant performance improvements compared to commonly used pre-trained CNN architectures. Also, we highlight the importance of transfer learning, when using such large architectures. Overall, our best performing method achieves an F1-Score of 80.1%.