 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistortion-Aware Adversarial Attacks on Bounding Boxes of Object Detectors
Dec 25, 2024Deep learning-based object detection has become ubiquitous in the last decade due to its high accuracy in many real-world applications. With this growing trend, these models are interested in being attacked by adversaries, with most of the results being on classifiers, which do not match the context of practical object detection. In this work, we propose a novel method to fool object detectors, expose the vulnerability of state-of-the-art detectors, and promote later works to build more robust detectors to adversarial examples. Our method aims to generate adversarial images by perturbing object confidence scores during training, which is crucial in predicting confidence for each class in the testing phase. Herein, we provide a more intuitive technique to embed additive noises based on detected objects' masks and the training loss with distortion control over the original image by leveraging the gradient of iterative images. To verify the proposed method, we perform adversarial attacks against different object detectors, including the most recent state-of-the-art models like YOLOv8, Faster R-CNN, RetinaNet, and Swin Transformer. We also evaluate our technique on MS COCO 2017 and PASCAL VOC 2012 datasets and analyze the trade-off between success attack rate and image distortion. Our experiments show that the achievable success attack rate is up to $100$\% and up to $98$\% when performing white-box and black-box attacks, respectively. The source code and relevant documentation for this work are available at the following link: https://github.com/anonymous20210106/attack_detector
Volumetric Mapping with Panoptic Refinement via Kernel Density Estimation for Mobile Robots
Dec 15, 2024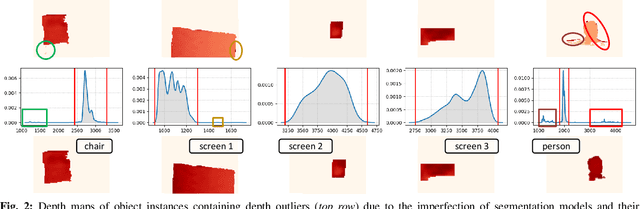
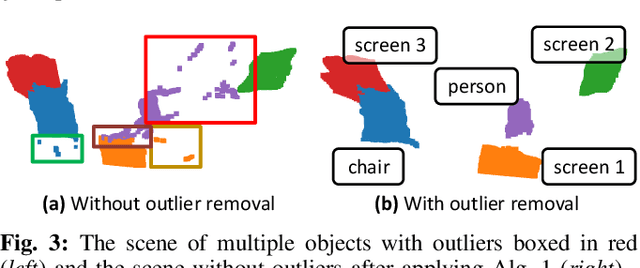


Reconstructing three-dimensional (3D) scenes with semantic understanding is vital in many robotic applications. Robots need to identify which objects, along with their positions and shapes, to manipulate them precisely with given tasks. Mobile robots, especially, usually use lightweight networks to segment objects on RGB images and then localize them via depth maps; however, they often encounter out-of-distribution scenarios where masks over-cover the objects. In this paper, we address the problem of panoptic segmentation quality in 3D scene reconstruction by refining segmentation errors using non-parametric statistical methods. To enhance mask precision, we map the predicted masks into a depth frame to estimate their distribution via kernel densities. The outliers in depth perception are then rejected without the need for additional parameters in an adaptive manner to out-of-distribution scenarios, followed by 3D reconstruction using projective signed distance functions (SDFs). We validate our method on a synthetic dataset, which shows improvements in both quantitative and qualitative results for panoptic mapping. Through real-world testing, the results furthermore show our method's capability to be deployed on a real-robot system. Our source code is available at: https://github.com/mkhangg/refined panoptic mapping.
V3D-SLAM: Robust RGB-D SLAM in Dynamic Environments with 3D Semantic Geometry Voting
Oct 15, 2024



Simultaneous localization and mapping (SLAM) in highly dynamic environments is challenging due to the correlation complexity between moving objects and the camera pose. Many methods have been proposed to deal with this problem; however, the moving properties of dynamic objects with a moving camera remain unclear. Therefore, to improve SLAM's performance, minimizing disruptive events of moving objects with a physical understanding of 3D shapes and dynamics of objects is needed. In this paper, we propose a robust method, V3D-SLAM, to remove moving objects via two lightweight re-evaluation stages, including identifying potentially moving and static objects using a spatial-reasoned Hough voting mechanism and refining static objects by detecting dynamic noise caused by intra-object motions using Chamfer distances as similarity measurements. Our experiment on the TUM RGB-D benchmark on dynamic sequences with ground-truth camera trajectories showed that our methods outperform the most recent state-of-the-art SLAM methods. Our source code is available at https://github.com/tuantdang/v3d-slam.
ExtPerFC: An Efficient 2D and 3D Perception Hardware-Software Framework for Mobile Cobot
Jun 08, 2023As the reliability of the robot's perception correlates with the number of integrated sensing modalities to tackle uncertainty, a practical solution to manage these sensors from different computers, operate them simultaneously, and maintain their real-time performance on the existing robotic system with minimal effort is needed. In this work, we present an end-to-end software-hardware framework, namely ExtPerFC, that supports both conventional hardware and software components and integrates machine learning object detectors without requiring an additional dedicated graphic processor unit (GPU). We first design our framework to achieve real-time performance on the existing robotic system, guarantee configuration optimization, and concentrate on code reusability. We then mathematically model and utilize our transfer learning strategies for 2D object detection and fuse them into depth images for 3D depth estimation. Lastly, we systematically test the proposed framework on the Baxter robot with two 7-DOF arms, a four-wheel mobility base, and an Intel RealSense D435i RGB-D camera. The results show that the robot achieves real-time performance while executing other tasks (e.g., map building, localization, navigation, object detection, arm moving, and grasping) simultaneously with available hardware like Intel onboard CPUS/GPUs on distributed computers. Also, to comprehensively control, program, and monitor the robot system, we design and introduce an end-user application. The source code is available at https://github.com/tuantdang/perception_framework.