 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViMQ: A Vietnamese Medical Question Dataset for Healthcare Dialogue System Development
Apr 27, 2023Existing medical text datasets usually take the form of ques- tion and answer pairs that support the task of natural language gener- ation, but lacking the composite annotations of the medical terms. In this study, we publish a Vietnamese dataset of medical questions from patients with sentence-level and entity-level annotations for the Intent Classification and Named Entity Recognition tasks. The tag sets for two tasks are in medical domain and can facilitate the development of task- oriented healthcare chatbots with better comprehension of queries from patients. We train baseline models for the two tasks and propose a simple self-supervised training strategy with span-noise modelling that substan- tially improves the performance. Dataset and code will be published at https://github.com/tadeephuy/ViMQ
* accepted at ICONIP 2021
Robust Dialog State Tracking for Large Ontologies
May 07, 2016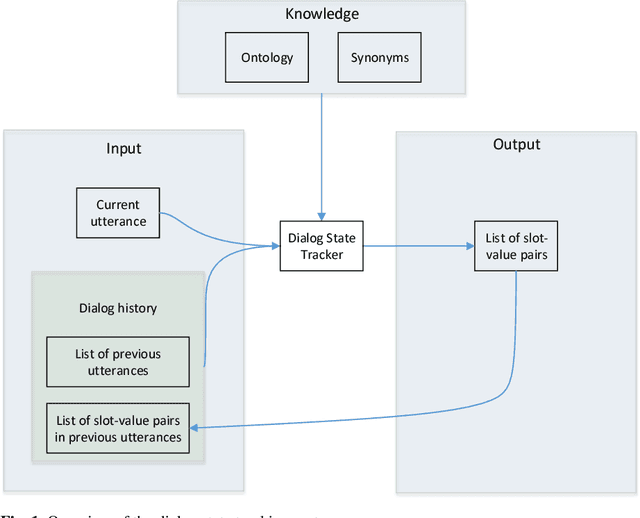
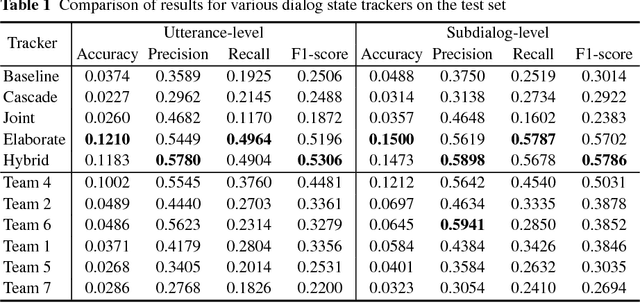
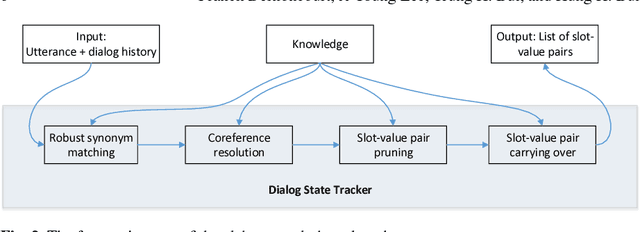
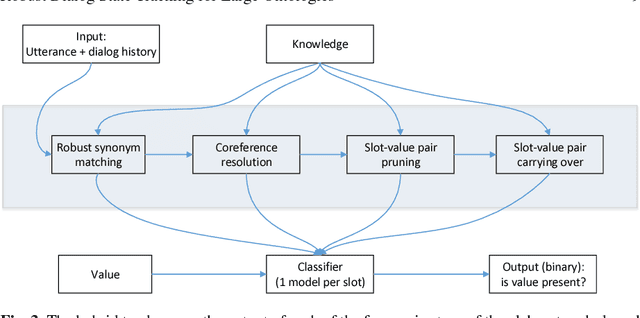
The Dialog State Tracking Challenge 4 (DSTC 4) differentiates itself from the previous three editions as follows: the number of slot-value pairs present in the ontology is much larger, no spoken language understanding output is given, and utterances are labeled at the subdialog level. This paper describes a novel dialog state tracking method designed to work robustly under these conditions, using elaborate string matching, coreference resolution tailored for dialogs and a few other improvements. The method can correctly identify many values that are not explicitly present in the utterance. On the final evaluation, our method came in first among 7 competing teams and 24 entries. The F1-score achieved by our method was 9 and 7 percentage points higher than that of the runner-up for the utterance-level evaluation and for the subdialog-level evaluation, respectively.
Adobe-MIT submission to the DSTC 4 Spoken Language Understanding pilot task
May 07, 2016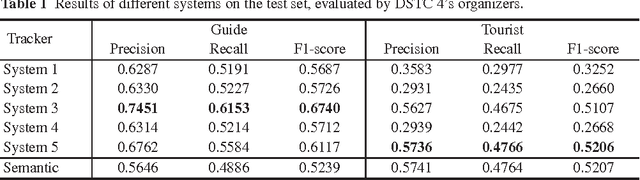
The Dialog State Tracking Challenge 4 (DSTC 4) proposes several pilot tasks. In this paper, we focus on the spoken language understanding pilot task, which consists of tagging a given utterance with speech acts and semantic slots. We compare different classifiers: the best system obtains 0.52 and 0.67 F1-scores on the test set for speech act recognition for the tourist and the guide respectively, and 0.52 F1-score for semantic tagging for both the guide and the tourist.