 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability-by-Design: A Methodology to Support Explanations in Decision-Making Systems
Jun 13, 2022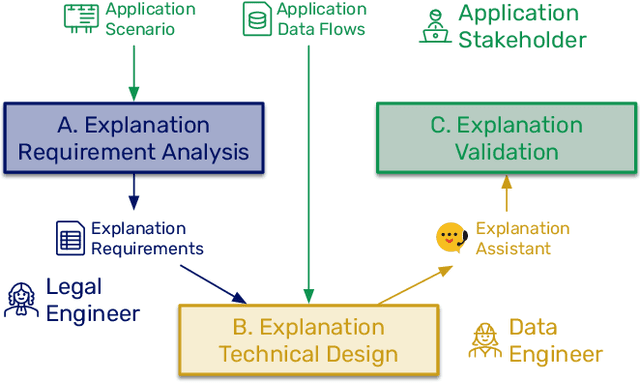



Algorithms play a key role nowadays in many technological systems that control or affect various aspects of our lives. As a result, providing explanations to address the needs of users and organisations is increasingly expected by the laws and regulations, codes of conduct, and the public. However, as laws and regulations do not prescribe how to meet such expectations, organisations are often left to devise their own approaches to explainability, inevitably increasing the cost of compliance and good governance. Hence, we put forth "Explainability by Design", a holistic methodology characterised by proactive measures to include explanation capability in the design of decision-making systems. This paper describes the technical steps of the Explainability-by-Design methodology in a software engineering workflow to implement explanation capability from requirements elicited by domain experts for a specific application context. Outputs of the Explainability-by-Design methodology are a set of configurations, allowing a reusable service, called the Explanation Assistant, to exploit logs provided by applications and create provenance traces that can be queried to extract relevant data points, which in turn can be used in explanation plans to construct explanations personalised to their consumers. Following those steps, organisations will be able to design their decision-making systems to produce explanations that meet the specified requirements, be it from laws, regulations, or business needs. We apply the methodology to two applications, resulting in a deployment of the Explanation Assistant demonstrating explanations capabilities. Finally, the associated development costs are measured, showing that the approach to construct explanations is tractable in terms of development time, which can be as low as two hours per explanation sentence.
A taxonomy of explanations to support Explainability-by-Design
Jun 09, 2022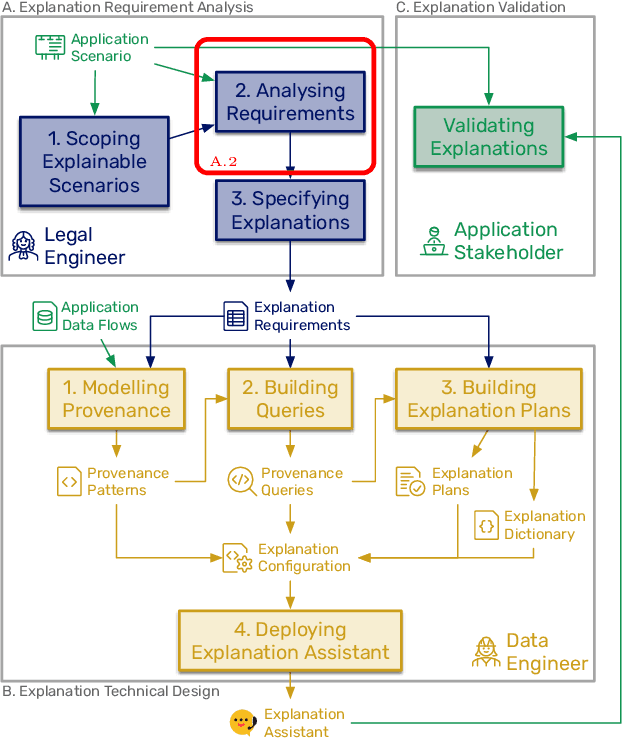


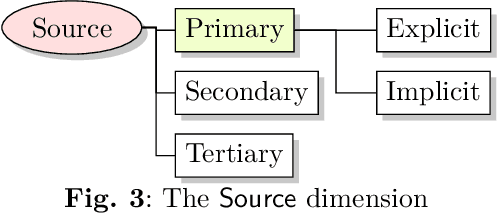
As automated decision-making solutions are increasingly applied to all aspects of everyday life, capabilities to generate meaningful explanations for a variety of stakeholders (i.e., decision-makers, recipients of decisions, auditors, regulators...) become crucial. In this paper, we present a taxonomy of explanations that was developed as part of a holistic 'Explainability-by-Design' approach for the purposes of the project PLEAD. The taxonomy was built with a view to produce explanations for a wide range of requirements stemming from a variety of regulatory frameworks or policies set at the organizational level either to translate high-level compliance requirements or to meet business needs. The taxonomy comprises nine dimensions. It is used as a stand-alone classifier of explanations conceived as detective controls, in order to aid supportive automated compliance strategies. A machinereadable format of the taxonomy is provided in the form of a light ontology and the benefits of starting the Explainability-by-Design journey with such a taxonomy are demonstrated through a series of examples.
Provenance Graph Kernel
Oct 20, 2020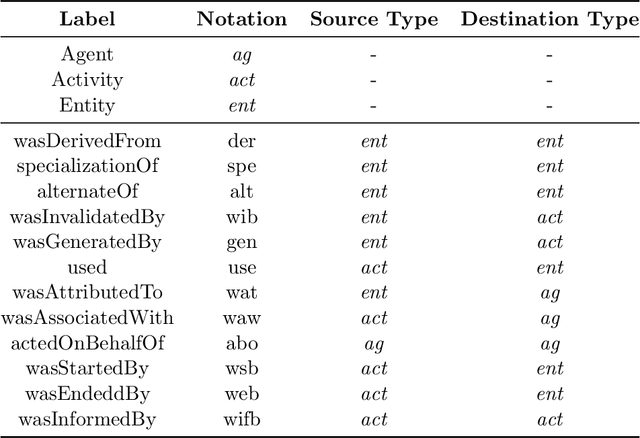
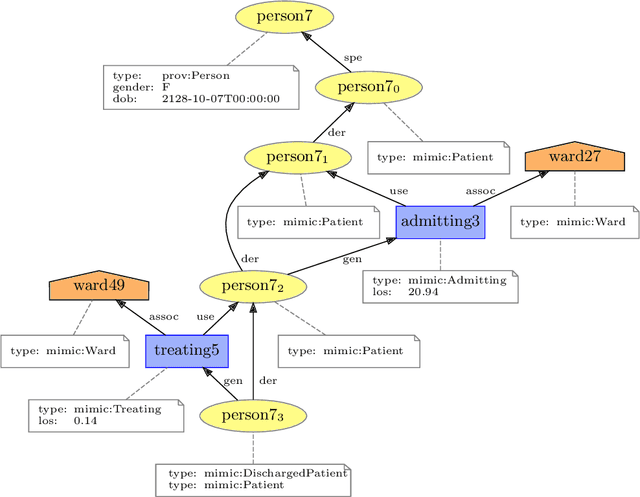

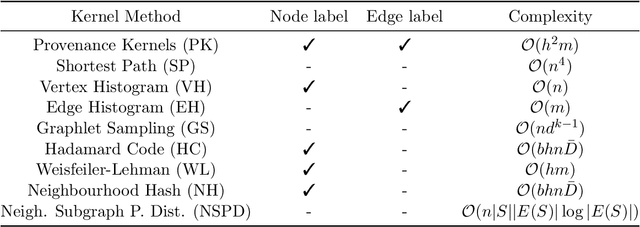
Provenance is a record that describes how entities, activities, and agents have influenced a piece of data. Such provenance information is commonly represented in graphs with relevant labels on both their nodes and edges. With the growing adoption of provenance in a wide range of application domains, increasingly, users are confronted with an abundance of graph data, which may prove challenging to analyse. Graph kernels, on the other hand, have been consistently and successfully used to efficiently classify graphs. In this paper, we introduce a novel graph kernel called \emph{provenance kernel}, which is inspired by and tailored for provenance data. It decomposes a provenance graph into tree-patterns rooted at a given node and considers the labels of edges and nodes up to a certain distance from the root. We employ provenance kernels to classify provenance graphs from three application domains. Our evaluation shows that they perform well in terms of classification accuracy and yield competitive results when compared against standard graph kernel methods and the provenance network analytics method while taking significantly less time.Moreover, we illustrate how the provenance types used in provenance kernels help improve the explainability of predictive models.