 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-visual video-to-speech synthesis with synthesized input audio
Jul 31, 2023Video-to-speech synthesis involves reconstructing the speech signal of a speaker from a silent video. The implicit assumption of this task is that the sound signal is either missing or contains a high amount of noise/corruption such that it is not useful for processing. Previous works in the literature either use video inputs only or employ both video and audio inputs during training, and discard the input audio pathway during inference. In this work we investigate the effect of using video and audio inputs for video-to-speech synthesis during both training and inference. In particular, we use pre-trained video-to-speech models to synthesize the missing speech signals and then train an audio-visual-to-speech synthesis model, using both the silent video and the synthesized speech as inputs, to predict the final reconstructed speech. Our experiments demonstrate that this approach is successful with both raw waveforms and mel spectrograms as target outputs.
Large-scale unsupervised audio pre-training for video-to-speech synthesis
Jun 27, 2023



Video-to-speech synthesis is the task of reconstructing the speech signal from a silent video of a speaker. Most established approaches to date involve a two-step process, whereby an intermediate representation from the video, such as a spectrogram, is extracted first and then passed to a vocoder to produce the raw audio. Some recent work has focused on end-to-end synthesis, whereby the generation of raw audio and any intermediate representations is performed jointly. All such approaches involve training on data from almost exclusively audio-visual datasets, i.e. every audio sample has a corresponding video sample. This precludes the use of abundant audio-only datasets which may not have a corresponding visual modality (e.g. audiobooks, radio podcasts, speech recognition datasets etc.), as well as audio-only architectures that have been developed by the audio machine learning community over the years. In this paper we propose to train encoder-decoder models on more than 3,500 hours of audio data at 24kHz, and then use the pre-trained decoders to initialize the audio decoders for the video-to-speech synthesis task. The pre-training step uses audio samples only and does not require labels or corresponding samples from other modalities (visual, text). We demonstrate that this pre-training step improves the reconstructed speech and that it is an unexplored way to improve the quality of the generator in a cross-modal task while only requiring samples from one of the modalities. We conduct experiments using both raw audio and mel spectrograms as target outputs and benchmark our models with existing work.
Speech-driven facial animation using polynomial fusion of features
Dec 12, 2019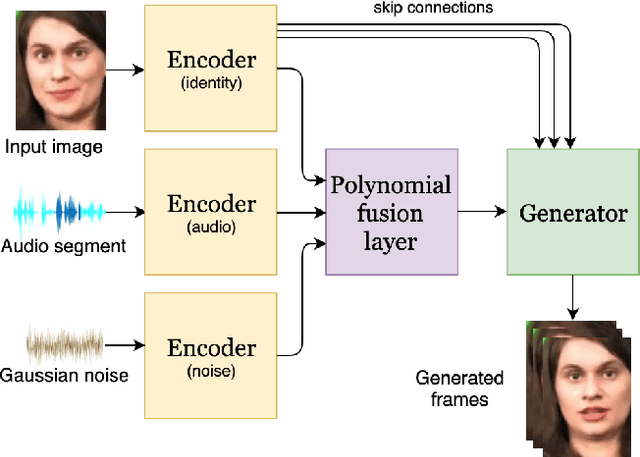
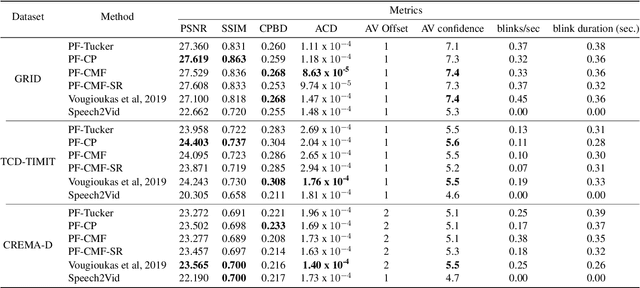
Speech-driven facial animation involves using a speech signal to generate realistic videos of talking faces. Recent deep learning approaches to facial synthesis rely on extracting low-dimensional representations and concatenating them, followed by a decoding step of the concatenated vector. This accounts for only first-order interactions of the features and ignores higher-order interactions. In this paper we propose a polynomial fusion layer that models the joint representation of the encodings by a higher-order polynomial, with the parameters modelled by a tensor decomposition. We demonstrate the the suitability of this approach through experiments on generated videos evaluated on a range of metrics on video quality, audiovisual synchronisation and generation of blinks.