 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's Not Just Labeling" -- A Research on LLM Generated Feedback Interpretability and Image Labeling Sketch Features
May 26, 2025



The quality of training data is critical to the performance of machine learning applications in domains like transportation, healthcare, and robotics. Accurate image labeling, however, often relies on time-consuming, expert-driven methods with limited feedback. This research introduces a sketch-based annotation approach supported by large language models (LLMs) to reduce technical barriers and enhance accessibility. Using a synthetic dataset, we examine how sketch recognition features relate to LLM feedback metrics, aiming to improve the reliability and interpretability of LLM-assisted labeling. We also explore how prompting strategies and sketch variations influence feedback quality. Our main contribution is a sketch-based virtual assistant that simplifies annotation for non-experts and advances LLM-driven labeling tools in terms of scalability, accessibility, and explainability.
Hashigo: A Next Generation Sketch Interactive System for Japanese Kanji
Apr 15, 2025Language students can increase their effectiveness in learning written Japanese by mastering the visual structure and written technique of Japanese kanji. Yet, existing kanji handwriting recognition systems do not assess the written technique sufficiently enough to discourage students from developing bad learning habits. In this paper, we describe our work on Hashigo, a kanji sketch interactive system which achieves human instructor-level critique and feedback on both the visual structure and written technique of students' sketched kanji. This type of automated critique and feedback allows students to target and correct specific deficiencies in their sketches that, if left untreated, are detrimental to effective long-term kanji learning.
Myna: Masking-Based Contrastive Learning of Musical Representations
Feb 19, 2025
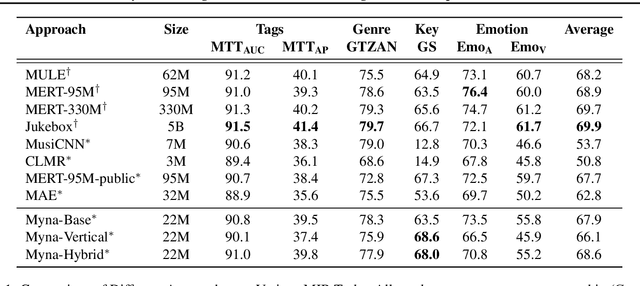


We present Myna, a simple yet effective approach for self-supervised musical representation learning. Built on a contrastive learning framework, Myna introduces two key innovations: (1) the use of a Vision Transformer (ViT) on mel-spectrograms as the backbone and (2) a novel data augmentation strategy, token masking, that masks 90 percent of spectrogram tokens. These innovations deliver both effectiveness and efficiency: (i) Token masking enables a significant increase in per-GPU batch size, from 48 or 120 in prior methods (CLMR, MULE) to 4096. (ii) By avoiding traditional augmentations, Myna retains pitch sensitivity, enhancing performance in tasks like key detection. (iii) The use of vertical patches allows the model to better capture critical features for key detection. Our hybrid model, Myna-22M-Hybrid, processes both 16x16 and 128x2 patches, achieving state-of-the-art results. Trained on a single GPU, it outperforms MULE (62M) on average and rivals MERT-95M, which was trained on 16 and 64 GPUs, respectively. Additionally, it surpasses MERT-95M-public, establishing itself as the best-performing model trained on publicly available data. We release our code and models to promote reproducibility and facilitate future research.
Mamba in Vision: A Comprehensive Survey of Techniques and Applications
Oct 04, 2024



Mamba is emerging as a novel approach to overcome the challenges faced by Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) in computer vision. While CNNs excel at extracting local features, they often struggle to capture long-range dependencies without complex architectural modifications. In contrast, ViTs effectively model global relationships but suffer from high computational costs due to the quadratic complexity of their self-attention mechanisms. Mamba addresses these limitations by leveraging Selective Structured State Space Models to effectively capture long-range dependencies with linear computational complexity. This survey analyzes the unique contributions, computational benefits, and applications of Mamba models while also identifying challenges and potential future research directions. We provide a foundational resource for advancing the understanding and growth of Mamba models in computer vision. An overview of this work is available at https://github.com/maklachur/Mamba-in-Computer-Vision.