 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMyna: Masking-Based Contrastive Learning of Musical Representations
Paper and Code

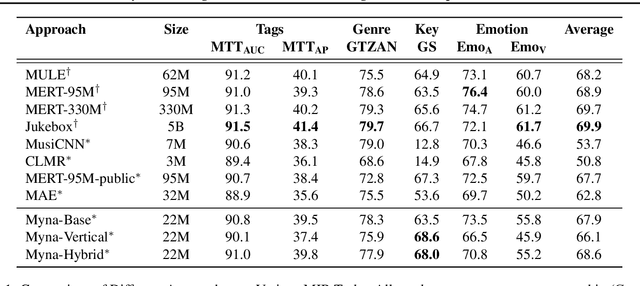


We present Myna, a simple yet effective approach for self-supervised musical representation learning. Built on a contrastive learning framework, Myna introduces two key innovations: (1) the use of a Vision Transformer (ViT) on mel-spectrograms as the backbone and (2) a novel data augmentation strategy, token masking, that masks 90 percent of spectrogram tokens. These innovations deliver both effectiveness and efficiency: (i) Token masking enables a significant increase in per-GPU batch size, from 48 or 120 in prior methods (CLMR, MULE) to 4096. (ii) By avoiding traditional augmentations, Myna retains pitch sensitivity, enhancing performance in tasks like key detection. (iii) The use of vertical patches allows the model to better capture critical features for key detection. Our hybrid model, Myna-22M-Hybrid, processes both 16x16 and 128x2 patches, achieving state-of-the-art results. Trained on a single GPU, it outperforms MULE (62M) on average and rivals MERT-95M, which was trained on 16 and 64 GPUs, respectively. Additionally, it surpasses MERT-95M-public, establishing itself as the best-performing model trained on publicly available data. We release our code and models to promote reproducibility and facilitate future research.