 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction Event Forecasting in Multi-Relational Recursive HyperGraphs: A Temporal Point Process Approach
Apr 27, 2024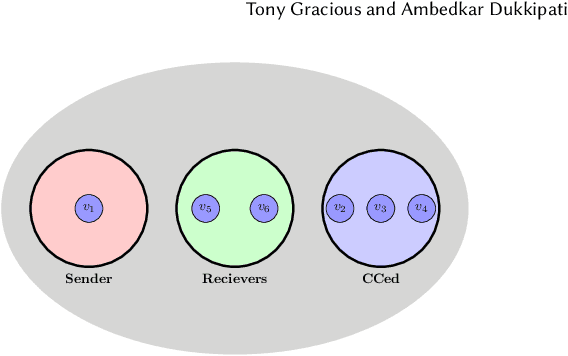
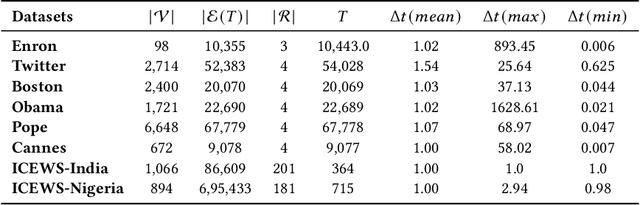
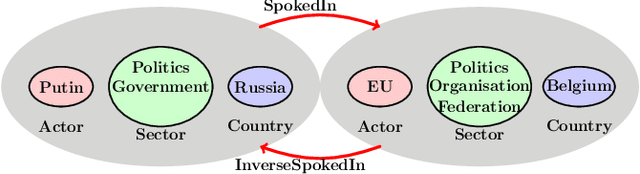
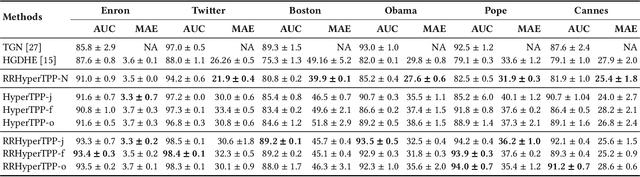
Modeling the dynamics of interacting entities using an evolving graph is an essential problem in fields such as financial networks and e-commerce. Traditional approaches focus primarily on pairwise interactions, limiting their ability to capture the complexity of real-world interactions involving multiple entities and their intricate relationship structures. This work addresses the problem of forecasting higher-order interaction events in multi-relational recursive hypergraphs. This is done using a dynamic graph representation learning framework that can capture complex relationships involving multiple entities. The proposed model, \textit{Relational Recursive Hyperedge Temporal Point Process} (RRHyperTPP) uses an encoder that learns a dynamic node representation based on the historical interaction patterns and then a hyperedge link prediction based decoder to model the event's occurrence. These learned representations are then used for downstream tasks involving forecasting the type and time of interactions. The main challenge in learning from hyperedge events is that the number of possible hyperedges grows exponentially with the number of nodes in the network. This will make the computation of negative log-likelihood of the temporal point process expensive, as the calculation of survival function requires a summation over all possible hyperedges. In our work, we use noise contrastive estimation to learn the parameters of our model, and we have experimentally shown that our models perform better than previous state-of-the-art methods for interaction forecasting.
Neural Temporal Point Process for Forecasting Higher Order and Directional Interactions
Jan 28, 2023



Real-world systems are made of interacting entities that evolve with time. Creating models that can forecast interactions by learning the dynamics of entities is an important problem in numerous fields. Earlier works used dynamic graph models to achieve this. However, real-world interactions are more complex than pairwise, as they involve more than two entities, and many of these higher-order interactions have directional components. Examples of these can be seen in communication networks such as email exchanges that involve a sender, and multiple recipients, citation networks, where authors draw upon the work of others, and so on. In this paper, we solve the problem of higher-order directed interaction forecasting by proposing a deep neural network-based model \textit{Directed HyperNode Temporal Point Process} for directed hyperedge event forecasting, as hyperedge provides native framework for modeling relationships among the variable number of nodes. Our proposed technique reduces the search space of possible candidate hyperedges by first forecasting the nodes at which events will be observed, based on which it generates candidate hyperedges. To demonstrate the efficiency of our model, we curated four datasets and conducted an extensive empirical study. We believe that this is the first work that solves the problem of forecasting higher-order directional interactions.
Representation Learning for Dynamic Hyperedges
Dec 19, 2021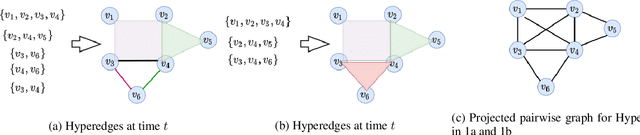
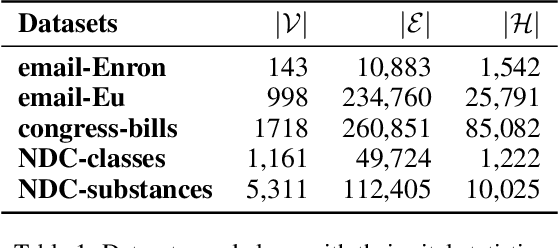
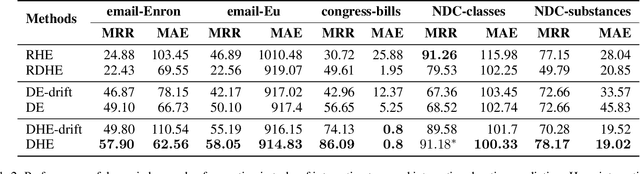
Recently there has been a massive interest in extracting information from interaction data. Traditionally this is done by modeling it as pair-wise interaction at a particular time in a dynamic network. However, real-world interactions are seldom pair-wise; they can involve more than two nodes. In literature, these types of group interactions are modeled by hyperedges/hyperlinks. The existing works for hyperedge modeling focused only on static networks, and they cannot model the temporal evolution of nodes as they interact with other nodes. Also, they cannot answer temporal queries like which type of interaction will occur next and when the interaction will occur. To address these limitations, in this paper, we develop a temporal point process model for hyperlink prediction. Our proposed model uses dynamic representation techniques for nodes to model the evolution and uses this representation in a neural point process framework to make inferences. We evaluate our models on five real-world interaction data and show that our dynamic model has significant performance gain over the static model. Further, we also demonstrate the advantages of our technique over the pair-wise interaction modeling technique.
CoviHawkes: Temporal Point Process and Deep Learning based Covid-19 forecasting for India
Sep 08, 2021
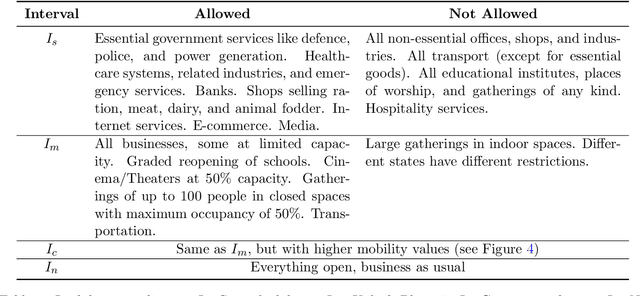


Lockdowns are one of the most effective measures for containing the spread of a pandemic. Unfortunately, they involve a heavy financial and emotional toll on the population that often outlasts the lockdown itself. This article argues in favor of ``local'' lockdowns, which are lockdowns focused on regions currently experiencing an outbreak. We propose a machine learning tool called CoviHawkes based on temporal point processes, called CoviHawkes that predicts the daily case counts for Covid-19 in India at the national, state, and district levels. Our short-term predictions ($<30$ days) may be helpful for policymakers in identifying regions where a local lockdown must be proactively imposed to arrest the spread of the virus. Our long-term predictions (up to a few months) simulate the progression of the pandemic under various lockdown conditions, thereby providing a noisy indicator for a potential third wave of cases in India. Extensive experimental results validate the performance of our tool at all levels.
Adversarial Context Aware Network Embeddings for Textual Networks
Nov 05, 2020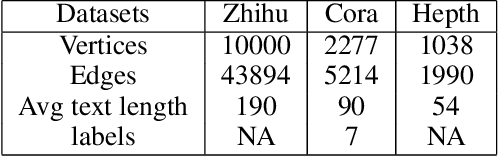
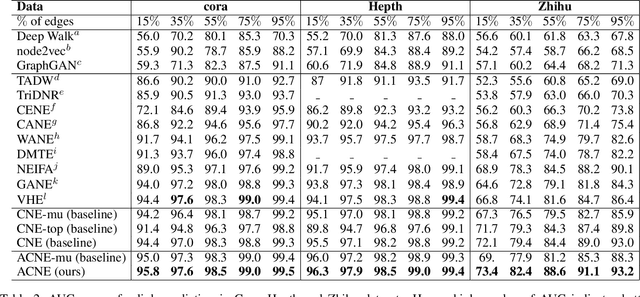

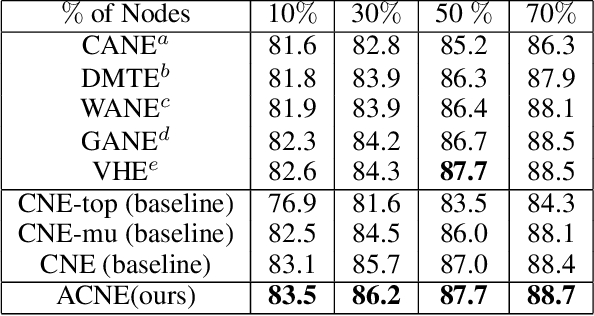
Representation learning of textual networks poses a significant challenge as it involves capturing amalgamated information from two modalities: (i) underlying network structure, and (ii) node textual attributes. For this, most existing approaches learn embeddings of text and network structure by enforcing embeddings of connected nodes to be similar. Then for achieving a modality fusion they use the similarities between text embedding of a node with the structure embedding of its connected node and vice versa. This implies that these approaches require edge information for learning embeddings and they cannot learn embeddings of unseen nodes. In this paper we propose an approach that achieves both modality fusion and the capability to learn embeddings of unseen nodes. The main feature of our model is that it uses an adversarial mechanism between text embedding based discriminator, and structure embedding based generator to learn efficient representations. Then for learning embeddings of unseen nodes, we use the supervision provided by the text embedding based discriminator. In addition this, we propose a novel architecture for learning text embedding that can combine both mutual attention and topological attention mechanism, which give more flexible text embeddings. Through extensive experiments on real-world datasets, we demonstrate that our model makes substantial gains over several state-of-the-art benchmarks. In comparison with previous state-of-the-art, it gives up to 7% improvement in performance in predicting links among nodes seen in the training and up to 12% improvement in performance in predicting links involving nodes not seen in training. Further, in the node classification task, it gives up to 2% improvement in performance.