 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Context Aware Network Embeddings for Textual Networks
Paper and Code
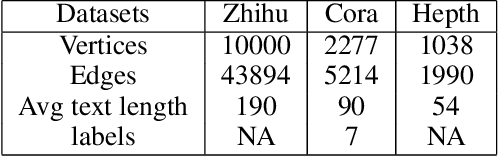
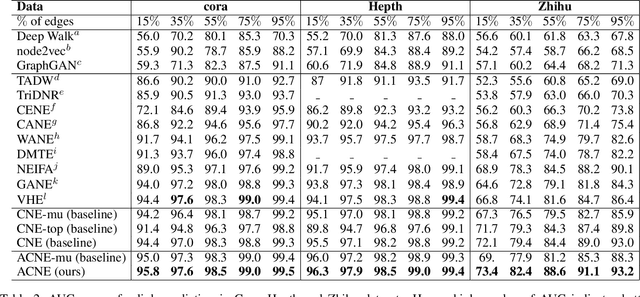

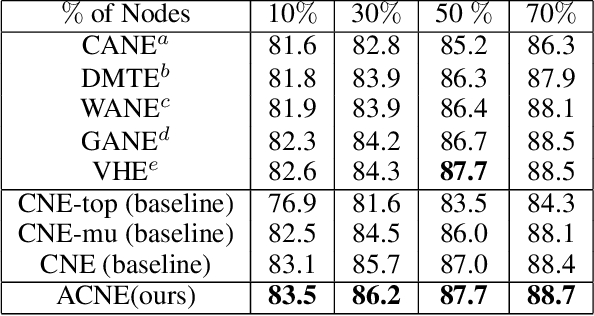
Representation learning of textual networks poses a significant challenge as it involves capturing amalgamated information from two modalities: (i) underlying network structure, and (ii) node textual attributes. For this, most existing approaches learn embeddings of text and network structure by enforcing embeddings of connected nodes to be similar. Then for achieving a modality fusion they use the similarities between text embedding of a node with the structure embedding of its connected node and vice versa. This implies that these approaches require edge information for learning embeddings and they cannot learn embeddings of unseen nodes. In this paper we propose an approach that achieves both modality fusion and the capability to learn embeddings of unseen nodes. The main feature of our model is that it uses an adversarial mechanism between text embedding based discriminator, and structure embedding based generator to learn efficient representations. Then for learning embeddings of unseen nodes, we use the supervision provided by the text embedding based discriminator. In addition this, we propose a novel architecture for learning text embedding that can combine both mutual attention and topological attention mechanism, which give more flexible text embeddings. Through extensive experiments on real-world datasets, we demonstrate that our model makes substantial gains over several state-of-the-art benchmarks. In comparison with previous state-of-the-art, it gives up to 7% improvement in performance in predicting links among nodes seen in the training and up to 12% improvement in performance in predicting links involving nodes not seen in training. Further, in the node classification task, it gives up to 2% improvement in performance.