 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepResearch-9K: A Challenging Benchmark Dataset of Deep-Research Agent
Mar 01, 2026Deep-research agents are capable of executing multi-step web exploration, targeted retrieval, and sophisticated question answering. Despite their powerful capabilities, deep-research agents face two critical bottlenecks: (1) the lack of large-scale, challenging datasets with real-world difficulty, and (2) the absence of accessible, open-source frameworks for data synthesis and agent training. To bridge these gaps, we first construct DeepResearch-9K, a large-scale challenging dataset specifically designed for deep-research scenarios built from open-source multi-hop question-answering (QA) datasets via a low-cost autonomous pipeline. Notably, it consists of (1) 9000 questions spanning three difficulty levels from L1 to L3 (2) high-quality search trajectories with reasoning chains from Tongyi-DeepResearch-30B-A3B, a state-of-the-art deep-research agent, and (3) verifiable answers. Furthermore, we develop an open-source training framework DeepResearch-R1 that supports (1) multi-turn web interactions, (2) different reinforcement learning (RL) approaches, and (3) different reward models such as rule-based outcome reward and LLM-as-judge feedback. Finally, empirical results demonstrate that agents trained on DeepResearch-9K under our DeepResearch-R1 achieve state-of-the-art results on challenging deep-research benchmarks. We release the DeepResearch-9K dataset on https://huggingface.co/datasets/artillerywu/DeepResearch-9K and the code of DeepResearch-R1 on https://github.com/Applied-Machine-Learning-Lab/DeepResearch-R1.
Empowering Denoising Sequential Recommendation with Large Language Model Embeddings
Oct 05, 2025Sequential recommendation aims to capture user preferences by modeling sequential patterns in user-item interactions. However, these models are often influenced by noise such as accidental interactions, leading to suboptimal performance. Therefore, to reduce the effect of noise, some works propose explicitly identifying and removing noisy items. However, we find that simply relying on collaborative information may result in an over-denoising problem, especially for cold items. To overcome these limitations, we propose a novel framework: Interest Alignment for Denoising Sequential Recommendation (IADSR) which integrates both collaborative and semantic information. Specifically, IADSR is comprised of two stages: in the first stage, we obtain the collaborative and semantic embeddings of each item from a traditional sequential recommendation model and an LLM, respectively. In the second stage, we align the collaborative and semantic embeddings and then identify noise in the interaction sequence based on long-term and short-term interests captured in the collaborative and semantic modalities. Our extensive experiments on four public datasets validate the effectiveness of the proposed framework and its compatibility with different sequential recommendation systems.
A Novel Few-Shot Relation Extraction Pipeline Based on Adaptive Prototype Fusion
Oct 15, 2022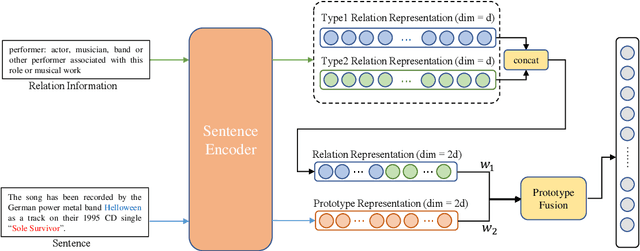
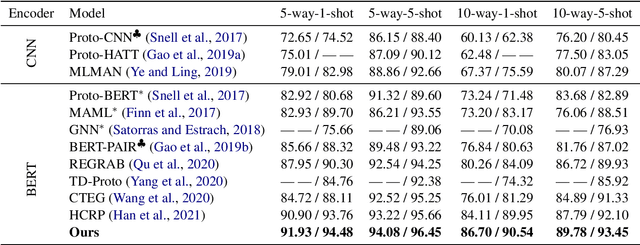
Few-shot relation extraction (FSRE) aims at recognizing unseen relations by learning with merely a handful of annotated instances. To more effectively generalize to new relations, this paper proposes a novel pipeline for the FSRE task based on adaptive prototype fusion. Specifically, for each relation class, the pipeline fully explores the relation information by concatenating two types of embedding, and then elaborately combine the relation representation with the adaptive prototype fusion mechanism. The whole framework can be effectively and efficiently optimized in an end-to-end fashion. Experiments on the benchmark dataset FewRel 1.0 show a significant improvement of our method against state-of-the-art methods.