 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral Image Data Reduction for Endmember Extraction
Dec 11, 2025



Endmember extraction from hyperspectral images aims to identify the spectral signatures of materials present in a scene. Recent studies have shown that self-dictionary methods can achieve high extraction accuracy; however, their high computational cost limits their applicability to large-scale hyperspectral images. Although several approaches have been proposed to mitigate this issue, it remains a major challenge. Motivated by this situation, this paper pursues a data reduction approach. Assuming that the hyperspectral image follows the linear mixing model with the pure-pixel assumption, we develop a data reduction technique that removes pixels that do not contain endmembers. We analyze the theoretical properties of this reduction step and show that it preserves pixels that lie close to the endmembers. Building on this result, we propose a data-reduced self-dictionary method that integrates the data reduction with a self-dictionary method based on a linear programming formulation. Numerical experiments demonstrate that the proposed method can substantially reduce the computational time of the original self-dictionary method without sacrificing endmember extraction accuracy.
Implementing Hottopixx Methods for Endmember Extraction in Hyperspectral Images
Apr 19, 2024Hyperspectral imaging technology has a wide range of applications, including forest management, mineral resource exploration, and Earth surface monitoring. Endmember extraction of hyperspectral images is a key step in leveraging this technology for applications. It aims to identifying the spectral signatures of materials, i.e., the major components in the observed scenes. Theoretically speaking, Hottopixx methods should be effective on problems involving extracting endmembers from hyperspectral images. Yet, these methods are challenging to perform in practice, due to high computational costs. They require us to solve LP problems, called Hottopixx models, whose size grows quadratically with the number of pixels in the image. It is thus still unclear as to whether they are actually effective or not. This study clarifies this situation. We propose an efficient and effective implementation of Hottopixx. Our implementation follows the framework of column generation, which is known as a classical but powerful means of solving large-scale LPs. We show in experiments that our implementation is applicable to the endmember extraction from real hyperspectral images and can provide estimations of endmember signatures with higher accuracy than the existing methods can.
Refinement of Hottopixx and its Postprocessing
Sep 07, 2021


Hottopixx, proposed by Bittorf et al. at NIPS 2012, is an algorithm for solving nonnegative matrix factorization (NMF) problems under the separability assumption. Separable NMFs have important applications, such as topic extraction from documents and unmixing of hyperspectral images. In such applications, the robustness of the algorithm to noise is the key to the success. Hottopixx has been shown to be robust to noise, and its robustness can be further enhanced through postprocessing. However, there is a drawback. Hottopixx and its postprocessing require us to estimate the noise level involved in the matrix we want to factorize before running, since they use it as part of the input data. The noise-level estimation is not an easy task. In this paper, we overcome this drawback. We present a refinement of Hottopixx and its postprocessing that runs without prior knowledge of the noise level. We show that the refinement has almost the same robustness to noise as the original algorithm.
Improved Analysis of Spectral Algorithm for Clustering
Dec 06, 2019

Spectral algorithms are graph partitioning algorithms that partition a node set of a graph into groups by using a spectral embedding map. Clustering techniques based on the algorithms are referred to as spectral clustering and are widely used in data analysis. To gain a better understanding of why spectral clustering is successful, Peng et al. (2015) and Kolev and Mehlhorn (2016) studied the behavior of a certain type of spectral algorithm for a class of graphs, called well-clustered graphs. Specifically, they put an assumption on graphs and showed the performance guarantee of the spectral algorithm under it. The algorithm they studied used the spectral embedding map developed by Shi and Malic (2000). In this paper, we improve on their results, giving a better performance guarantee under a weaker assumption. We also evaluate the performance of the spectral algorithm with the spectral embedding map developed by Ng et al. (2002).
Convex Programming Based Spectral Clustering
May 11, 2018
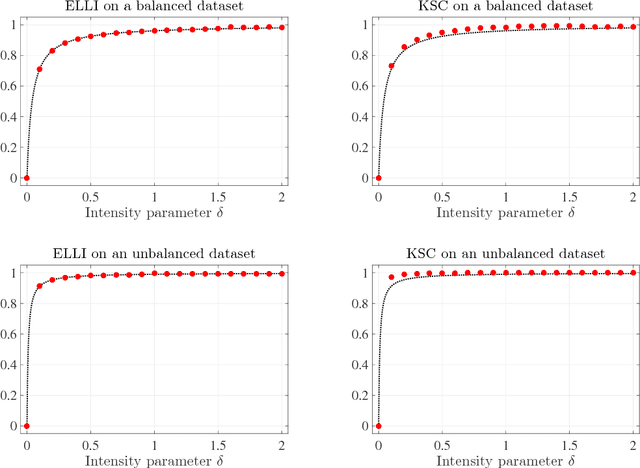

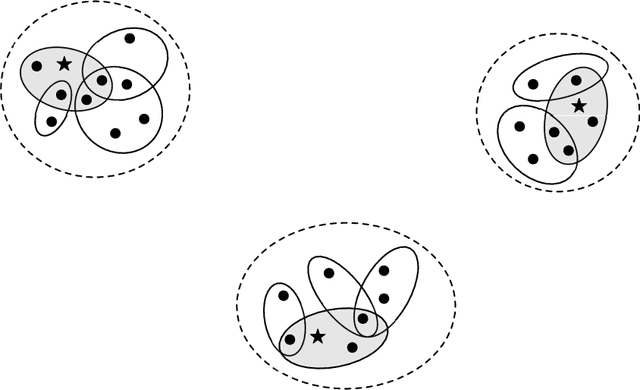
Clustering is a fundamental task in data analysis, and spectral clustering has been recognized as a promising approach to it. Given a graph describing the relationship between data, spectral clustering explores the underlying cluster structure in two stages. The first stage embeds the nodes of the graph into real space, and the second stage groups the embedded nodes into several clusters. The use of the $k$-means method in the grouping stage is currently standard practice. We present a spectral clustering algorithm that uses convex programming in the grouping stage, and study how well it works. The concept behind the algorithm design lies in the following observation. The nodes with the largest degree in each cluster may be found by computing an enclosing ellipsoid for embedded nodes in real space, and the clusters may be identified by using those nodes. We show that the observations are valid, and the algorithm returns clusters to provide the conductance of graph, if the gap assumption, introduced by Peng el al. at COLT 2015, is satisfied. We also give an experimental assessment of the algorithm's performance.
Efficient Preconditioning for Noisy Separable NMFs by Successive Projection Based Low-Rank Approximations
Oct 01, 2017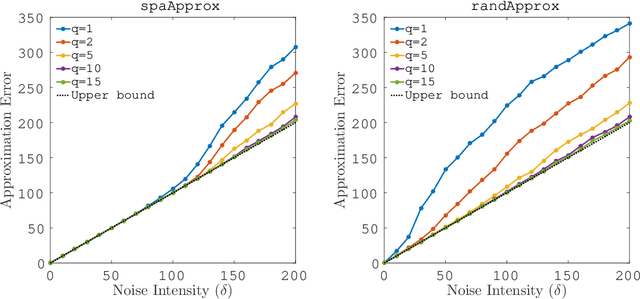



The successive projection algorithm (SPA) can quickly solve a nonnegative matrix factorization problem under a separability assumption. Even if noise is added to the problem, SPA is robust as long as the perturbations caused by the noise are small. In particular, robustness against noise should be high when handling the problems arising from real applications. The preconditioner proposed by Gillis and Vavasis (2015) makes it possible to enhance the noise robustness of SPA. Meanwhile, an additional computational cost is required. The construction of the preconditioner contains a step to compute the top-$k$ truncated singular value decomposition of an input matrix. It is known that the decomposition provides the best rank-$k$ approximation to the input matrix; in other words, a matrix with the smallest approximation error among all matrices of rank less than $k$. This step is an obstacle to an efficient implementation of the preconditioned SPA. To address the cost issue, we propose a modification of the algorithm for constructing the preconditioner. Although the original algorithm uses the best rank-$k$ approximation, instead of it, our modification uses an alternative. Ideally, this alternative should have high approximation accuracy and low computational cost. To ensure this, our modification employs a rank-$k$ approximation produced by an SPA based algorithm. We analyze the accuracy of the approximation and evaluate the computational cost of the algorithm. We then present an empirical study revealing the actual performance of the SPA based rank-$k$ approximation algorithm and the modified preconditioned SPA.
* 32 pages, 4 figures
Robustness Analysis of Preconditioned Successive Projection Algorithm for General Form of Separable NMF Problem
Jan 28, 2016The successive projection algorithm (SPA) has been known to work well for separable nonnegative matrix factorization (NMF) problems arising in applications, such as topic extraction from documents and endmember detection in hyperspectral images. One of the reasons is in that the algorithm is robust to noise. Gillis and Vavasis showed in [SIAM J. Optim., 25(1), pp. 677-698, 2015] that a preconditioner can further enhance its noise robustness. The proof rested on the condition that the dimension $d$ and factorization rank $r$ in the separable NMF problem coincide with each other. However, it may be unrealistic to expect that the condition holds in separable NMF problems appearing in actual applications; in such problems, $d$ is usually greater than $r$. This paper shows, without the condition $d=r$, that the preconditioned SPA is robust to noise.
* 19 pages
Spectral Clustering by Ellipsoid and Its Connection to Separable Nonnegative Matrix Factorization
Mar 05, 2015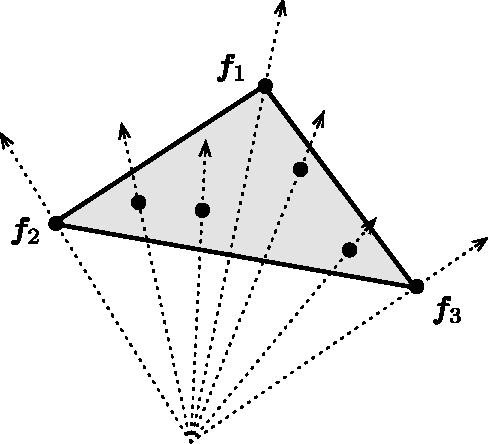


This paper proposes a variant of the normalized cut algorithm for spectral clustering. Although the normalized cut algorithm applies the K-means algorithm to the eigenvectors of a normalized graph Laplacian for finding clusters, our algorithm instead uses a minimum volume enclosing ellipsoid for them. We show that the algorithm shares similarity with the ellipsoidal rounding algorithm for separable nonnegative matrix factorization. Our theoretical insight implies that the algorithm can serve as a bridge between spectral clustering and separable NMF. The K-means algorithm has the issues in that the choice of initial points affects the construction of clusters and certain choices result in poor clustering performance. The normalized cut algorithm inherits these issues since K-means is incorporated in it, whereas the algorithm proposed here does not. An empirical study is presented to examine the performance of the algorithm.
Ellipsoidal Rounding for Nonnegative Matrix Factorization Under Noisy Separability
Feb 12, 2014

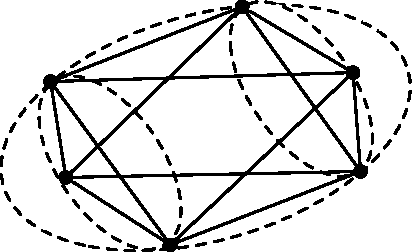

We present a numerical algorithm for nonnegative matrix factorization (NMF) problems under noisy separability. An NMF problem under separability can be stated as one of finding all vertices of the convex hull of data points. The research interest of this paper is to find the vectors as close to the vertices as possible in a situation in which noise is added to the data points. Our algorithm is designed to capture the shape of the convex hull of data points by using its enclosing ellipsoid. We show that the algorithm has correctness and robustness properties from theoretical and practical perspectives; correctness here means that if the data points do not contain any noise, the algorithm can find the vertices of their convex hull; robustness means that if the data points contain noise, the algorithm can find the near-vertices. Finally, we apply the algorithm to document clustering, and report the experimental results.
* 29 pages, 6 figures. Minor revisions; Revised Figure 2; Added Table 1