 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Message-Passing Policies for Multi-Agent Reinforcement Learning
Jul 31, 2025Decentralized Multi-Agent Reinforcement Learning (MARL) methods allow for learning scalable multi-agent policies, but suffer from partial observability and induced non-stationarity. These challenges can be addressed by introducing mechanisms that facilitate coordination and high-level planning. Specifically, coordination and temporal abstraction can be achieved through communication (e.g., message passing) and Hierarchical Reinforcement Learning (HRL) approaches to decision-making. However, optimization issues limit the applicability of hierarchical policies to multi-agent systems. As such, the combination of these approaches has not been fully explored. To fill this void, we propose a novel and effective methodology for learning multi-agent hierarchies of message-passing policies. We adopt the feudal HRL framework and rely on a hierarchical graph structure for planning and coordination among agents. Agents at lower levels in the hierarchy receive goals from the upper levels and exchange messages with neighboring agents at the same level. To learn hierarchical multi-agent policies, we design a novel reward-assignment method based on training the lower-level policies to maximize the advantage function associated with the upper levels. Results on relevant benchmarks show that our method performs favorably compared to the state of the art.
Feudal Graph Reinforcement Learning
Apr 11, 2023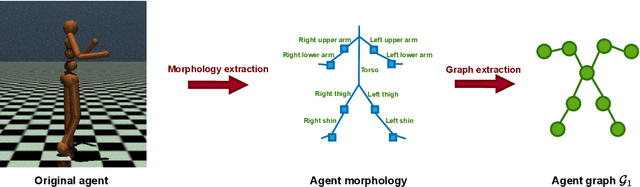
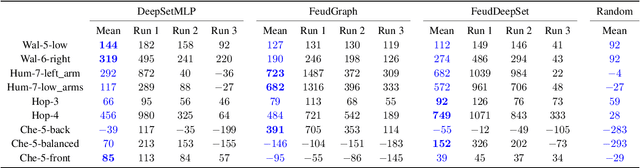
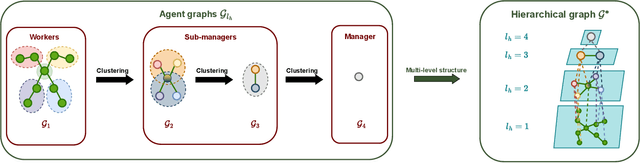

We focus on learning composable policies to control a variety of physical agents with possibly different structures. Among state-of-the-art methods, prominent approaches exploit graph-based representations and weight-sharing modular policies based on the message-passing framework. However, as shown by recent literature, message passing can create bottlenecks in information propagation and hinder global coordination. This drawback can become even more problematic in tasks where high-level planning is crucial. In fact, in similar scenarios, each modular policy - e.g., controlling a joint of a robot - would request to coordinate not only for basic locomotion but also achieve high-level goals, such as navigating a maze. A classical solution to avoid similar pitfalls is to resort to hierarchical decision-making. In this work, we adopt the Feudal Reinforcement Learning paradigm to develop agents where control actions are the outcome of a hierarchical (pyramidal) message-passing process. In the proposed Feudal Graph Reinforcement Learning (FGRL) framework, high-level decisions at the top level of the hierarchy are propagated through a layered graph representing a hierarchy of policies. Lower layers mimic the morphology of the physical system and upper layers can capture more abstract sub-modules. The purpose of this preliminary work is to formalize the framework and provide proof-of-concept experiments on benchmark environments (MuJoCo locomotion tasks). Empirical evaluation shows promising results on both standard benchmarks and zero-shot transfer learning settings.