 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted synthetic data generation for tabular data via hardness characterization
Oct 01, 2024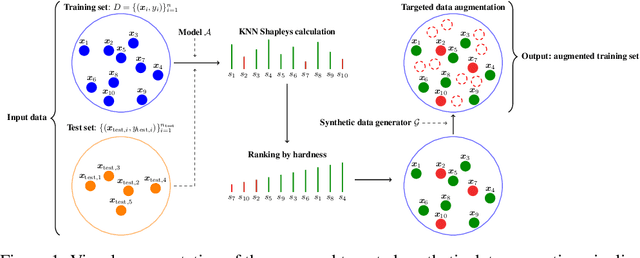
Synthetic data generation has been proven successful in improving model performance and robustness in the context of scarce or low-quality data. Using the data valuation framework to statistically identify beneficial and detrimental observations, we introduce a novel augmentation pipeline that generates only high-value training points based on hardness characterization. We first demonstrate via benchmarks on real data that Shapley-based data valuation methods perform comparably with learning-based methods in hardness characterisation tasks, while offering significant theoretical and computational advantages. Then, we show that synthetic data generators trained on the hardest points outperform non-targeted data augmentation on simulated data and on a large scale credit default prediction task. In particular, our approach improves the quality of out-of-sample predictions and it is computationally more efficient compared to non-targeted methods.