 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Line Search Method Based on Regression and Uncertainty Quantification
May 17, 2024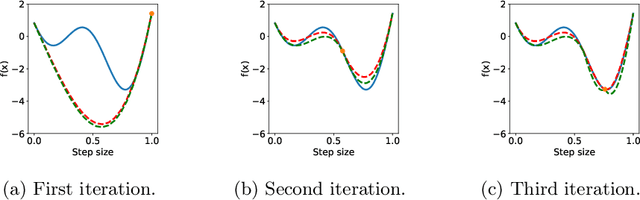

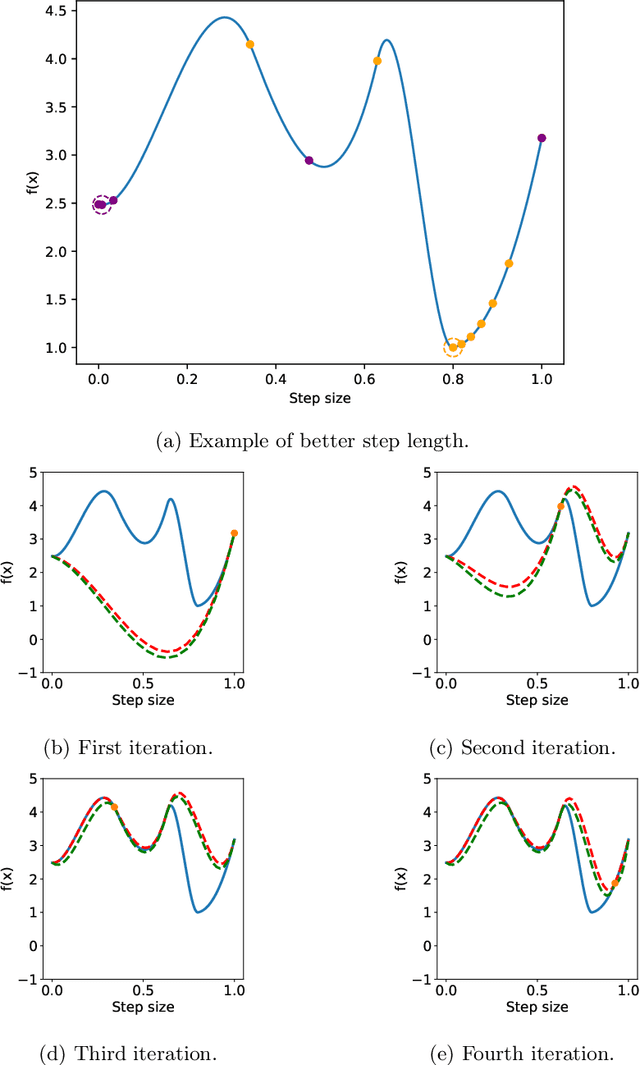
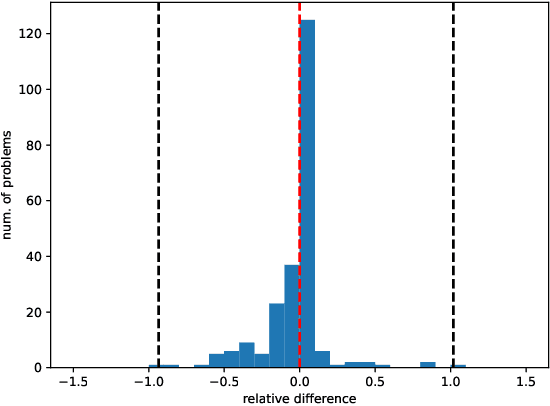
Unconstrained optimization problems are typically solved using iterative methods, which often depend on line search techniques to determine optimal step lengths in each iteration. This paper introduces a novel line search approach. Traditional line search methods, aimed at determining optimal step lengths, often discard valuable data from the search process and focus on refining step length intervals. This paper proposes a more efficient method using Bayesian optimization, which utilizes all available data points, i.e., function values and gradients, to guide the search towards a potential global minimum. This new approach more effectively explores the search space, leading to better solution quality. It is also easy to implement and integrate into existing frameworks. Tested on the challenging CUTEst test set, it demonstrates superior performance compared to existing state-of-the-art methods, solving more problems to optimality with equivalent resource usage.
Compressing Sentence Representation with maximum Coding Rate Reduction
Apr 25, 2023In most natural language inference problems, sentence representation is needed for semantic retrieval tasks. In recent years, pre-trained large language models have been quite effective for computing such representations. These models produce high-dimensional sentence embeddings. An evident performance gap between large and small models exists in practice. Hence, due to space and time hardware limitations, there is a need to attain comparable results when using the smaller model, which is usually a distilled version of the large language model. In this paper, we assess the model distillation of the sentence representation model Sentence-BERT by augmenting the pre-trained distilled model with a projection layer additionally learned on the Maximum Coding Rate Reduction (MCR2)objective, a novel approach developed for general-purpose manifold clustering. We demonstrate that the new language model with reduced complexity and sentence embedding size can achieve comparable results on semantic retrieval benchmarks.