 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Neural Network Training via Subset Pretraining
Oct 21, 2024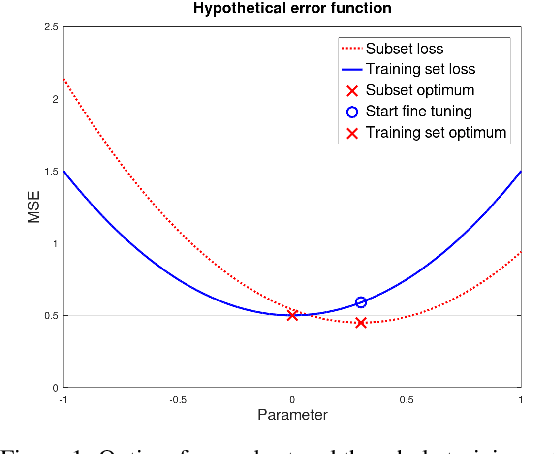
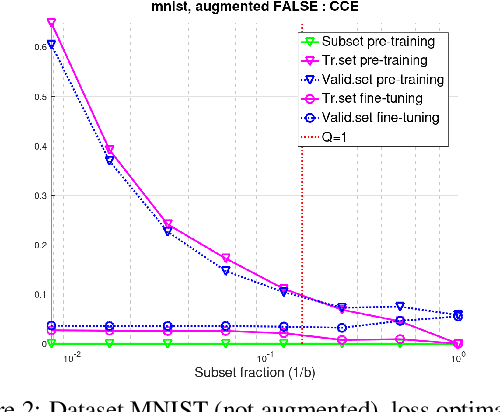
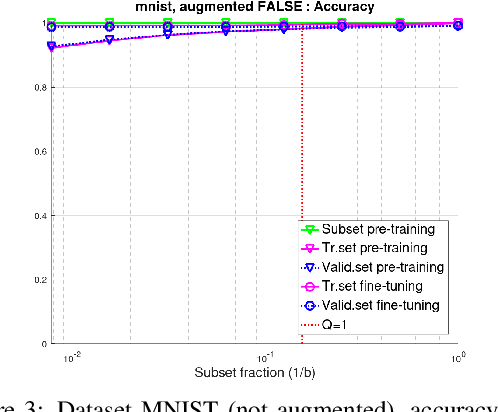

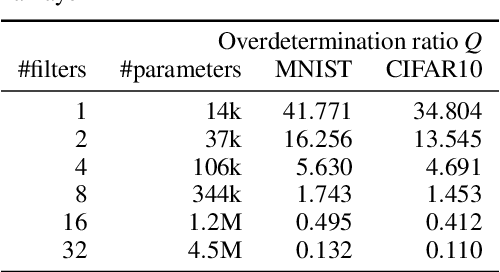
In training neural networks, it is common practice to use partial gradients computed over batches, mostly very small subsets of the training set. This approach is motivated by the argument that such a partial gradient is close to the true one, with precision growing only with the square root of the batch size. A theoretical justification is with the help of stochastic approximation theory. However, the conditions for the validity of this theory are not satisfied in the usual learning rate schedules. Batch processing is also difficult to combine with efficient second-order optimization methods. This proposal is based on another hypothesis: the loss minimum of the training set can be expected to be well-approximated by the minima of its subsets. Such subset minima can be computed in a fraction of the time necessary for optimizing over the whole training set. This hypothesis has been tested with the help of the MNIST, CIFAR-10, and CIFAR-100 image classification benchmarks, optionally extended by training data augmentation. The experiments have confirmed that results equivalent to conventional training can be reached. In summary, even small subsets are representative if the overdetermination ratio for the given model parameter set sufficiently exceeds unity. The computing expense can be reduced to a tenth or less.
Reducing the Transformer Architecture to a Minimum
Oct 17, 2024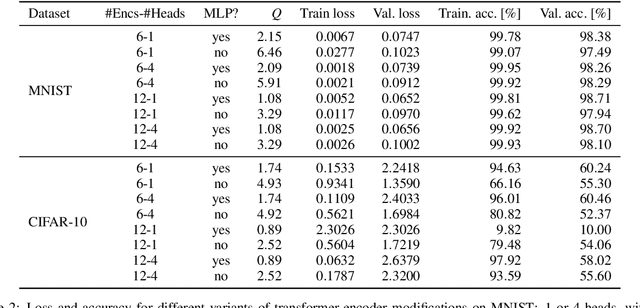
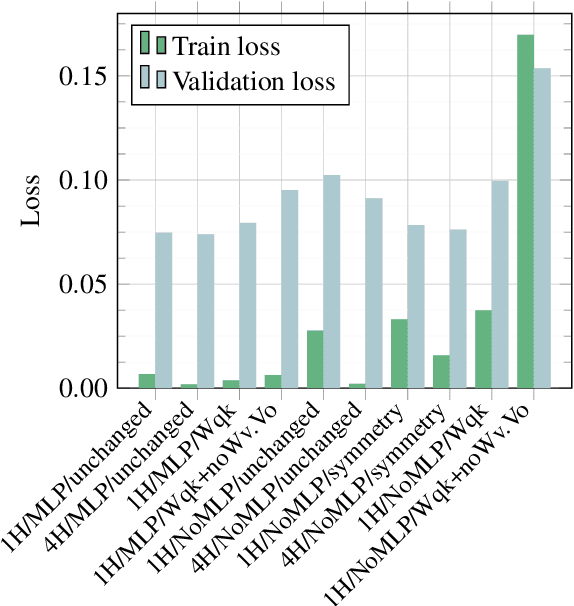
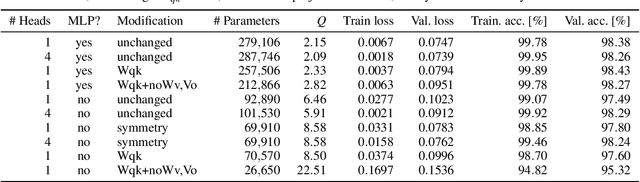
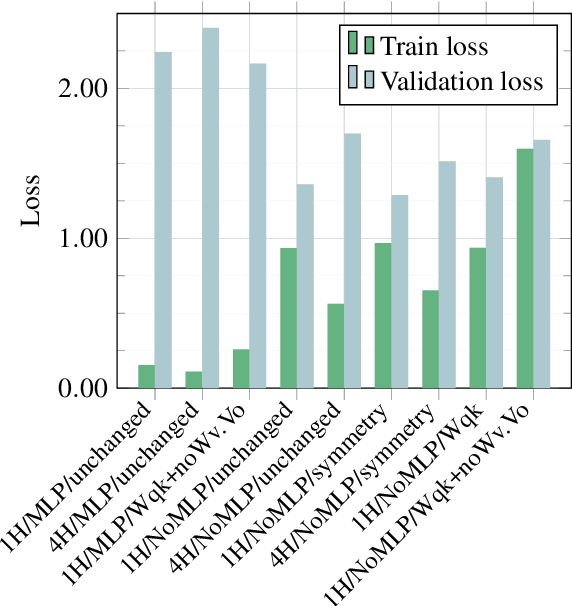
Transformers are a widespread and successful model architecture, particularly in Natural Language Processing (NLP) and Computer Vision (CV). The essential innovation of this architecture is the Attention Mechanism, which solves the problem of extracting relevant context information from long sequences in NLP and realistic scenes in CV. A classical neural network component, a Multi-Layer Perceptron (MLP), complements the attention mechanism. Its necessity is frequently justified by its capability of modeling nonlinear relationships. However, the attention mechanism itself is nonlinear through its internal use of similarity measures. A possible hypothesis is that this nonlinearity is sufficient for modeling typical application problems. As the MLPs usually contain the most trainable parameters of the whole model, their omission would substantially reduce the parameter set size. Further components can also be reorganized to reduce the number of parameters. Under some conditions, query and key matrices can be collapsed into a single matrix of the same size. The same is true about value and projection matrices, which can also be omitted without eliminating the substance of the attention mechanism. Initially, the similarity measure was defined asymmetrically, with peculiar properties such as that a token is possibly dissimilar to itself. A possible symmetric definition requires only half of the parameters. We have laid the groundwork by testing widespread CV benchmarks: MNIST and CIFAR-10. The tests have shown that simplified transformer architectures (a) without MLP, (b) with collapsed matrices, and (c) symmetric similarity matrices exhibit similar performance as the original architecture, saving up to 90% of parameters without hurting the classification performance.
Make Deep Networks Shallow Again
Sep 15, 2023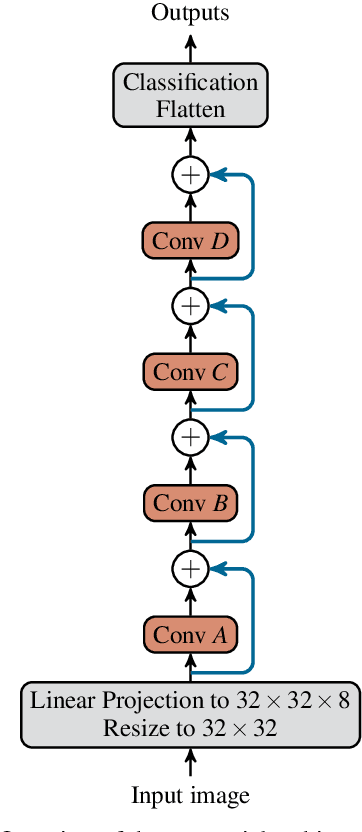
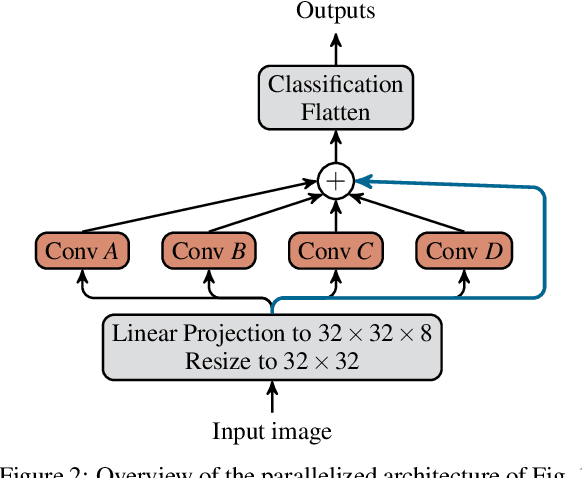
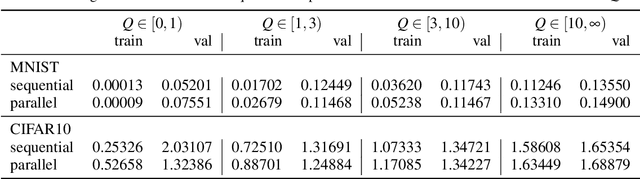
Deep neural networks have a good success record and are thus viewed as the best architecture choice for complex applications. Their main shortcoming has been, for a long time, the vanishing gradient which prevented the numerical optimization algorithms from acceptable convergence. A breakthrough has been achieved by the concept of residual connections -- an identity mapping parallel to a conventional layer. This concept is applicable to stacks of layers of the same dimension and substantially alleviates the vanishing gradient problem. A stack of residual connection layers can be expressed as an expansion of terms similar to the Taylor expansion. This expansion suggests the possibility of truncating the higher-order terms and receiving an architecture consisting of a single broad layer composed of all initially stacked layers in parallel. In other words, a sequential deep architecture is substituted by a parallel shallow one. Prompted by this theory, we investigated the performance capabilities of the parallel architecture in comparison to the sequential one. The computer vision datasets MNIST and CIFAR10 were used to train both architectures for a total of 6912 combinations of varying numbers of convolutional layers, numbers of filters, kernel sizes, and other meta parameters. Our findings demonstrate a surprising equivalence between the deep (sequential) and shallow (parallel) architectures. Both layouts produced similar results in terms of training and validation set loss. This discovery implies that a wide, shallow architecture can potentially replace a deep network without sacrificing performance. Such substitution has the potential to simplify network architectures, improve optimization efficiency, and accelerate the training process.
Number of Attention Heads vs Number of Transformer-Encoders in Computer Vision
Sep 15, 2022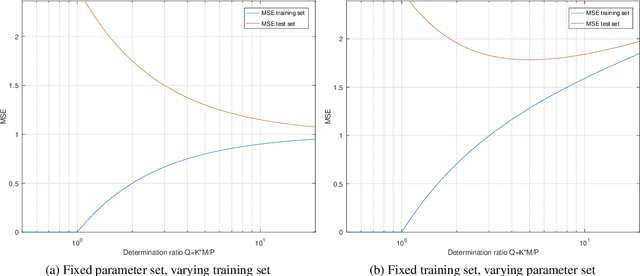
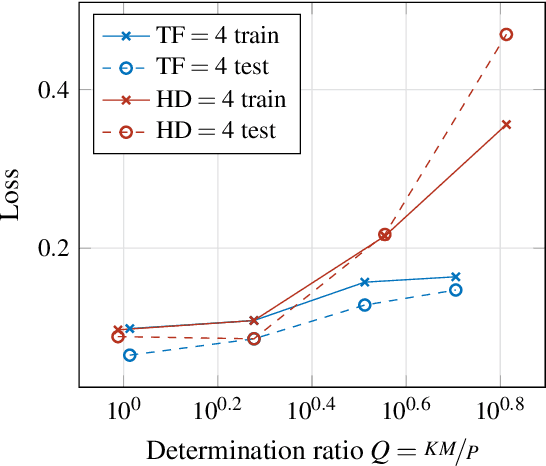
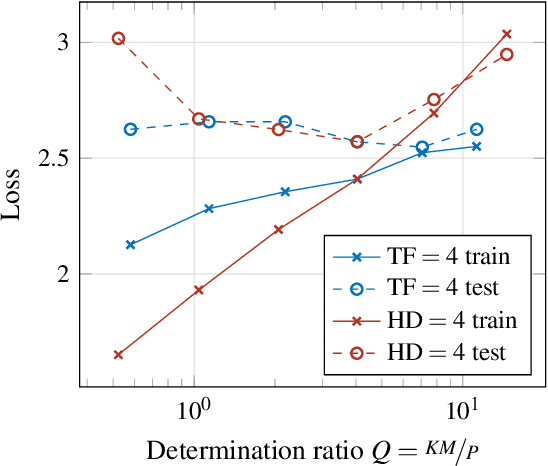
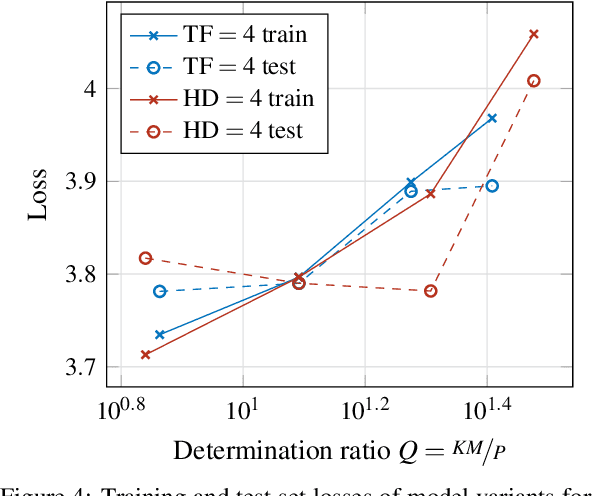
Determining an appropriate number of attention heads on one hand and the number of transformer-encoders, on the other hand, is an important choice for Computer Vision (CV) tasks using the Transformer architecture. Computing experiments confirmed the expectation that the total number of parameters has to satisfy the condition of overdetermination (i.e., number of constraints significantly exceeding the number of parameters). Then, good generalization performance can be expected. This sets the boundaries within which the number of heads and the number of transformers can be chosen. If the role of context in images to be classified can be assumed to be small, it is favorable to use multiple transformers with a low number of heads (such as one or two). In classifying objects whose class may heavily depend on the context within the image (i.e., the meaning of a patch being dependent on other patches), the number of heads is equally important as that of transformers.
Training Neural Networks in Single vs Double Precision
Sep 15, 2022
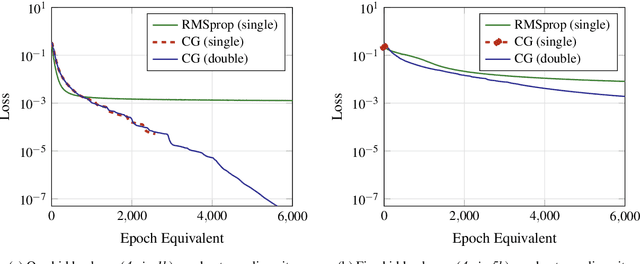
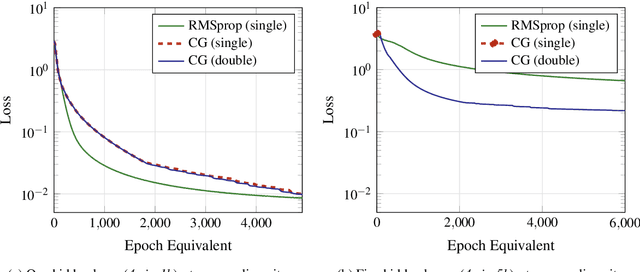
The commitment to single-precision floating-point arithmetic is widespread in the deep learning community. To evaluate whether this commitment is justified, the influence of computing precision (single and double precision) on the optimization performance of the Conjugate Gradient (CG) method (a second-order optimization algorithm) and RMSprop (a first-order algorithm) has been investigated. Tests of neural networks with one to five fully connected hidden layers and moderate or strong nonlinearity with up to 4 million network parameters have been optimized for Mean Square Error (MSE). The training tasks have been set up so that their MSE minimum was known to be zero. Computing experiments have disclosed that single-precision can keep up (with superlinear convergence) with double-precision as long as line search finds an improvement. First-order methods such as RMSprop do not benefit from double precision. However, for moderately nonlinear tasks, CG is clearly superior. For strongly nonlinear tasks, both algorithm classes find only solutions fairly poor in terms of mean square error as related to the output variance. CG with double floating-point precision is superior whenever the solutions have the potential to be useful for the application goal.
Representational Capacity of Deep Neural Networks -- A Computing Study
Jul 19, 2019
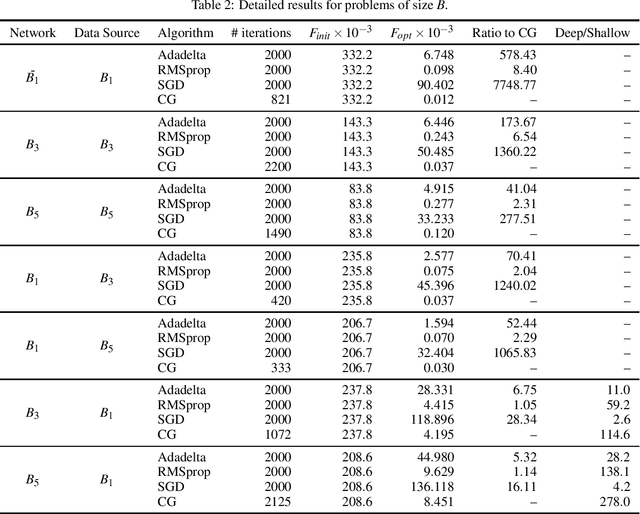
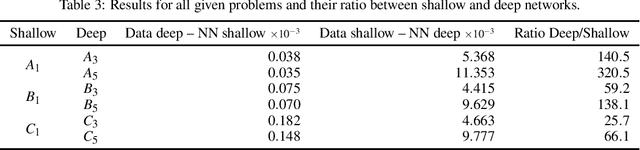
There is some theoretical evidence that deep neural networks with multiple hidden layers have a potential for more efficient representation of multidimensional mappings than shallow networks with a single hidden layer. The question is whether it is possible to exploit this theoretical advantage for finding such representations with help of numerical training methods. Tests using prototypical problems with a known mean square minimum did not confirm this hypothesis. Minima found with the help of deep networks have always been worse than those found using shallow networks. This does not directly contradict the theoretical findings---it is possible that the superior representational capacity of deep networks is genuine while finding the mean square minimum of such deep networks is a substantially harder problem than with shallow ones.
Singular Value Decomposition and Neural Networks
Jun 27, 2019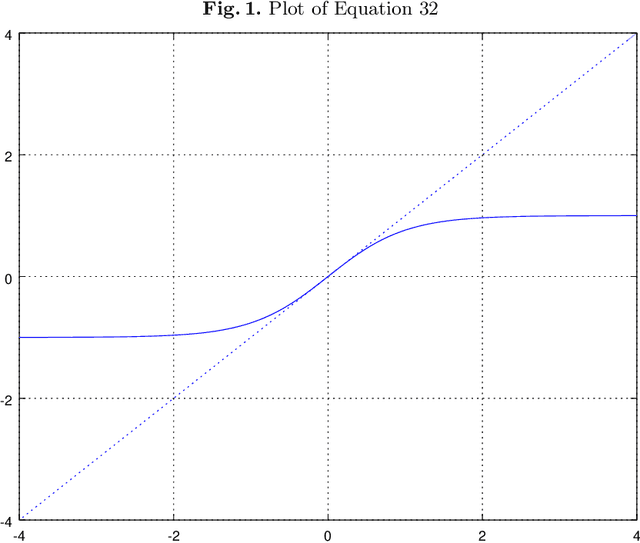

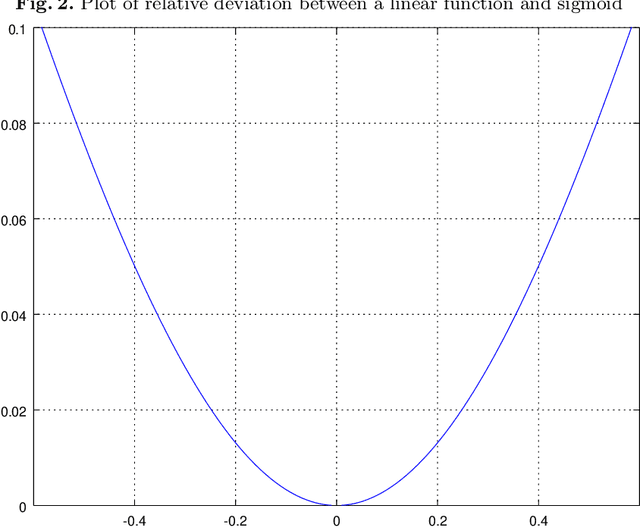
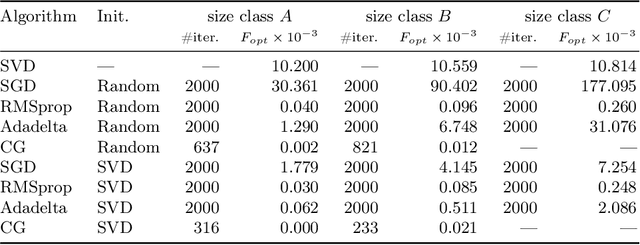
Singular Value Decomposition (SVD) constitutes a bridge between the linear algebra concepts and multi-layer neural networks---it is their linear analogy. Besides of this insight, it can be used as a good initial guess for the network parameters, leading to substantially better optimization results.