 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Neural Networks in Single vs Double Precision
Paper and Code
Sep 15, 2022
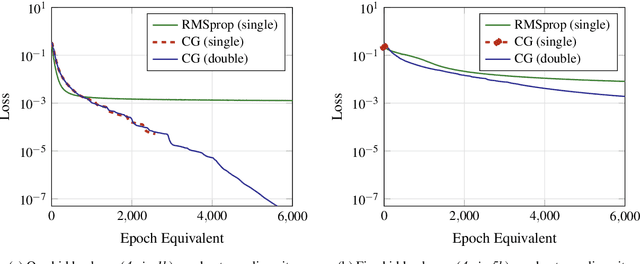
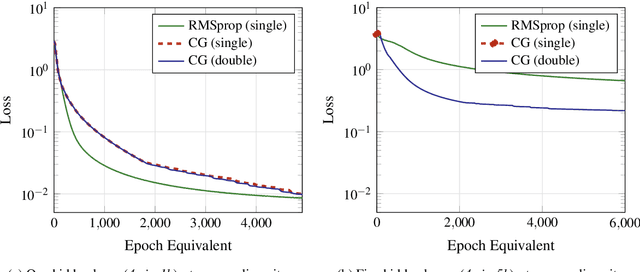
The commitment to single-precision floating-point arithmetic is widespread in the deep learning community. To evaluate whether this commitment is justified, the influence of computing precision (single and double precision) on the optimization performance of the Conjugate Gradient (CG) method (a second-order optimization algorithm) and RMSprop (a first-order algorithm) has been investigated. Tests of neural networks with one to five fully connected hidden layers and moderate or strong nonlinearity with up to 4 million network parameters have been optimized for Mean Square Error (MSE). The training tasks have been set up so that their MSE minimum was known to be zero. Computing experiments have disclosed that single-precision can keep up (with superlinear convergence) with double-precision as long as line search finds an improvement. First-order methods such as RMSprop do not benefit from double precision. However, for moderately nonlinear tasks, CG is clearly superior. For strongly nonlinear tasks, both algorithm classes find only solutions fairly poor in terms of mean square error as related to the output variance. CG with double floating-point precision is superior whenever the solutions have the potential to be useful for the application goal.