 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumber of Attention Heads vs Number of Transformer-Encoders in Computer Vision
Paper and Code
Sep 15, 2022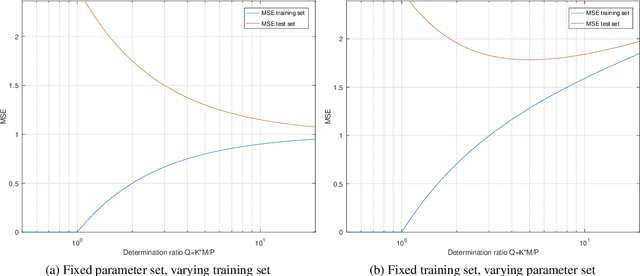
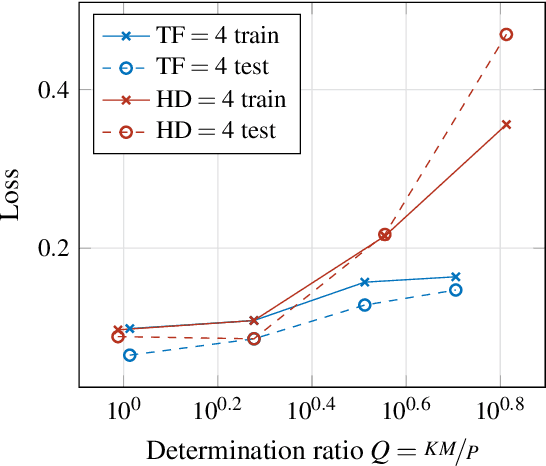
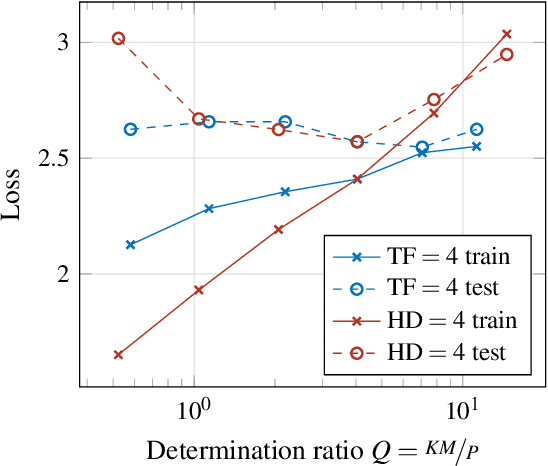
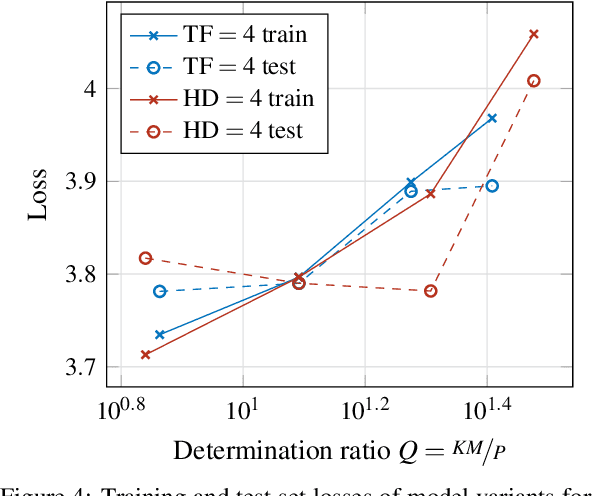
Determining an appropriate number of attention heads on one hand and the number of transformer-encoders, on the other hand, is an important choice for Computer Vision (CV) tasks using the Transformer architecture. Computing experiments confirmed the expectation that the total number of parameters has to satisfy the condition of overdetermination (i.e., number of constraints significantly exceeding the number of parameters). Then, good generalization performance can be expected. This sets the boundaries within which the number of heads and the number of transformers can be chosen. If the role of context in images to be classified can be assumed to be small, it is favorable to use multiple transformers with a low number of heads (such as one or two). In classifying objects whose class may heavily depend on the context within the image (i.e., the meaning of a patch being dependent on other patches), the number of heads is equally important as that of transformers.