 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIS-aided Latent Space Alignment for Semantic Channel Equalization
Jul 23, 2025Semantic communication systems introduce a new paradigm in wireless communications, focusing on transmitting the intended meaning rather than ensuring strict bit-level accuracy. These systems often rely on Deep Neural Networks (DNNs) to learn and encode meaning directly from data, enabling more efficient communication. However, in multi-user settings where interacting agents are trained independently-without shared context or joint optimization-divergent latent representations across AI-native devices can lead to semantic mismatches, impeding mutual understanding even in the absence of traditional transmission errors. In this work, we address semantic mismatch in Multiple-Input Multiple-Output (MIMO) channels by proposing a joint physical and semantic channel equalization framework that leverages the presence of Reconfigurable Intelligent Surfaces (RIS). The semantic equalization is implemented as a sequence of transformations: (i) a pre-equalization stage at the transmitter; (ii) propagation through the RIS-aided channel; and (iii) a post-equalization stage at the receiver. We formulate the problem as a constrained Minimum Mean Squared Error (MMSE) optimization and propose two solutions: (i) a linear semantic equalization chain, and (ii) a non-linear DNN-based semantic equalizer. Both methods are designed to operate under semantic compression in the latent space and adhere to transmit power constraints. Through extensive evaluations, we show that the proposed joint equalization strategies consistently outperform conventional, disjoint approaches to physical and semantic channel equalization across a broad range of scenarios and wireless channel conditions.
Relative Representations of Latent Spaces enable Efficient Semantic Channel Equalization
Nov 29, 2024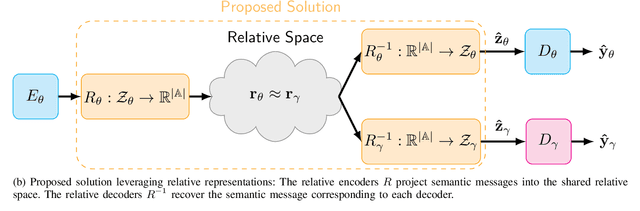
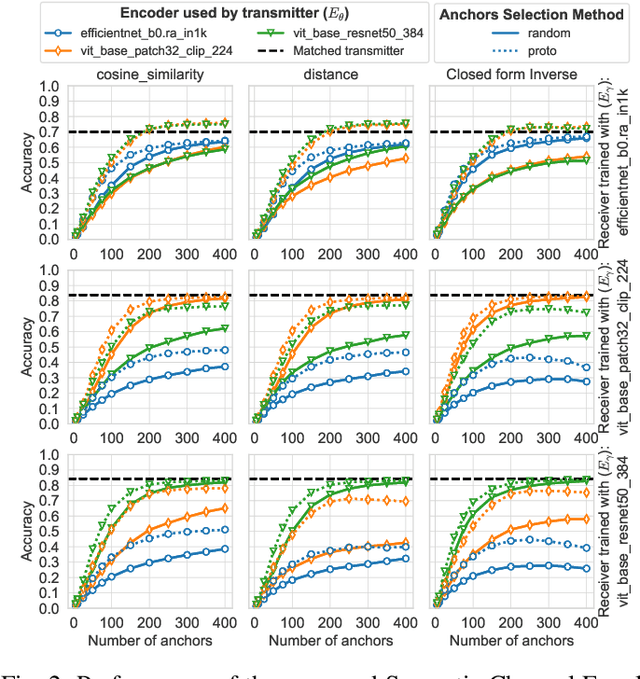
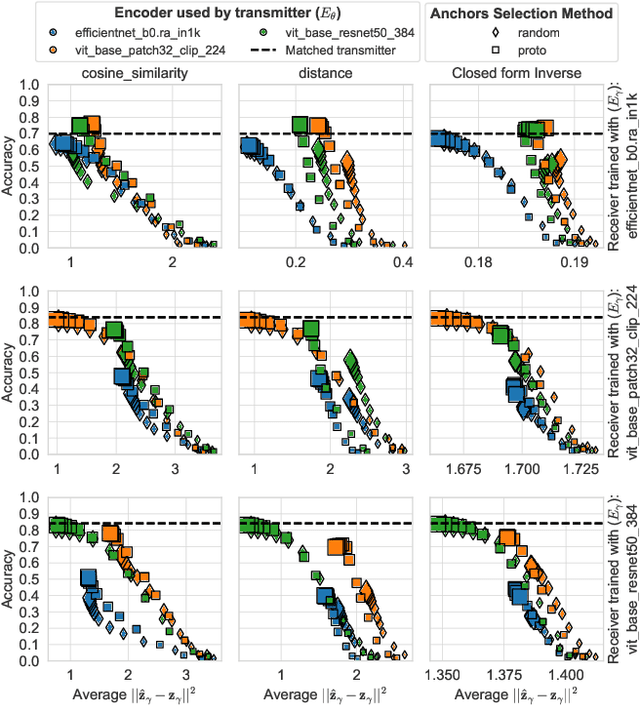
In multi-user semantic communication, language mismatche poses a significant challenge when independently trained agents interact. We present a novel semantic equalization algorithm that enables communication between agents with different languages without additional retraining. Our algorithm is based on relative representations, a framework that enables different agents employing different neural network models to have unified representation. It proceeds by projecting the latent vectors of different models into a common space defined relative to a set of data samples called \textit{anchors}, whose number equals the dimension of the resulting space. A communication between different agents translates to a communication of semantic symbols sampled from this relative space. This approach, in addition to aligning the semantic representations of different agents, allows compressing the amount of information being exchanged, by appropriately selecting the number of anchors. Eventually, we introduce a novel anchor selection strategy, which advantageously determines prototypical anchors, capturing the most relevant information for the downstream task. Our numerical results show the effectiveness of the proposed approach allowing seamless communication between agents with radically different models, including differences in terms of neural network architecture and datasets used for initial training.
Soft Partitioning of Latent Space for Semantic Channel Equalization
Jun 04, 2024



Semantic channel equalization has emerged as a solution to address language mismatch in multi-user semantic communications. This approach aims to align the latent spaces of an encoder and a decoder which were not jointly trained and it relies on a partition of the semantic (latent) space into atoms based on the the semantic meaning. In this work we explore the role of the semantic space partition in scenarios where the task structure involves a one-to-many mapping between the semantic space and the action space. In such scenarios, partitioning based on hard inference results results in loss of information which degrades the equalization performance. We propose a soft criterion to derive the atoms of the partition which leverages the soft decoder's output and offers a more comprehensive understanding of the semantic space's structure. Through empirical validation, we demonstrate that soft partitioning yields a more descriptive and regular partition of the space, consequently enhancing the performance of the equalization algorithm.