 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral bandits
Apr 28, 2026Smooth functions on graphs have wide applications in manifold and semi-supervised learning. In this work, we study a bandit problem where the payoffs of arms are smooth on a graph. This framework is suitable for solving online learning problems that involve graphs, such as content-based recommendation. In this problem, each item we can recommend is a node of an undirected graph and its expected rating is similar to the one of its neighbors. The goal is to recommend items that have high expected ratings. We aim for the algorithms where the cumulative regret with respect to the optimal policy would not scale poorly with the number of nodes. In particular, we introduce the notion of an effective dimension, which is small in real-world graphs, and propose three algorithms for solving our problem that scale linearly and sublinearly in this dimension. Our experiments on content recommendation problem show that a good estimator of user preferences for thousands of items can be learned from just tens of node evaluations.
Online learning with Erdős-Rényi side-observation graphs
Apr 28, 2026We consider adversarial multi-armed bandit problems where the learner is allowed to observe losses of a number of arms beside the arm that it actually chose. We study the case where all non-chosen arms reveal their loss with a fixed but unknown probability $r$, independently of each other and the action of the learner. We propose two algorithms that work for different ranges of $r$. We show that after $T$ rounds in a bandit problem with $N$ arms, the expected regret of our first algorithm is $O(\sqrt{(T /r) \log N })$ whenever $r\ge(\log T)/(2N)$, while our second algorithm achieves a regret of $O(\sqrt{(T/r) \log (N+T)})$ for smaller values of $r$. We also give a quick estimation procedure that decides the range of~$r$. All our bounds are within logarithmic factors of the best achievable performance of any algorithm that is even allowed to know~$r$.
* Published at International Conference on Machine Learning (ICML) 2015. 11 pages
Spectral bandits for smooth graph functions
Apr 20, 2026Smooth functions on graphs have wide applications in manifold and semi-supervised learning. In this paper, we study a bandit problem where the payoffs of arms are smooth on a graph. This framework is suitable for solving online learning problems that involve graphs, such as content-based recommendation. In this problem, each item we can recommend is a node and its expected rating is similar to its neighbors. The goal is to recommend items that have high expected ratings. We aim for the algorithms where the cumulative regret with respect to the optimal policy would not scale poorly with the number of nodes. In particular, we introduce the notion of an effective dimension, which is small in real-world graphs, and propose two algorithms for solving our problem that scale linearly and sublinearly in this dimension. Our experiments on real-world content recommendation problem show that a good estimator of user preferences for thousands of items can be learned from just tens of nodes evaluations.
Online learning with noisy side observations
Apr 15, 2026We propose a new partial-observability model for online learning problems where the learner, besides its own loss, also observes some noisy feedback about the other actions, depending on the underlying structure of the problem. We represent this structure by a weighted directed graph, where the edge weights are related to the quality of the feedback shared by the connected nodes. Our main contribution is an efficient algorithm that guarantees a regret of $\widetilde{O}(\sqrt{α^* T})$ after $T$ rounds, where $α^*$ is a novel graph property that we call the effective independence number. Our algorithm is completely parameter-free and does not require knowledge (or even estimation) of $α^*$. For the special case of binary edge weights, our setting reduces to the partial-observability models of Mannor and Shamir (2011) and Alon et al. (2013) and our algorithm recovers the near-optimal regret bounds.
* Published at International Conference on Artificial Intelligence and Statistics (AISTATS) 2016. 13 pages, 7 figures
Online Learning with Feedback Graphs: The True Shape of Regret
Jun 05, 2023Sequential learning with feedback graphs is a natural extension of the multi-armed bandit problem where the problem is equipped with an underlying graph structure that provides additional information - playing an action reveals the losses of all the neighbors of the action. This problem was introduced by \citet{mannor2011} and received considerable attention in recent years. It is generally stated in the literature that the minimax regret rate for this problem is of order $\sqrt{\alpha T}$, where $\alpha$ is the independence number of the graph, and $T$ is the time horizon. However, this is proven only when the number of rounds $T$ is larger than $\alpha^3$, which poses a significant restriction for the usability of this result in large graphs. In this paper, we define a new quantity $R^*$, called the \emph{problem complexity}, and prove that the minimax regret is proportional to $R^*$ for any graph and time horizon $T$. Introducing an intricate exploration strategy, we define the \mainAlgorithm algorithm that achieves the minimax optimal regret bound and becomes the first provably optimal algorithm for this setting, even if $T$ is smaller than $\alpha^3$.
On the complexity of All $\varepsilon$-Best Arms Identification
Feb 13, 2022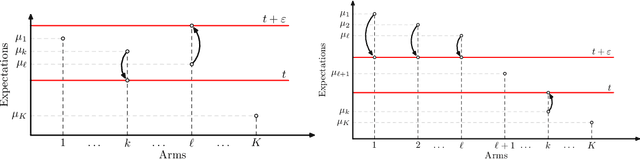
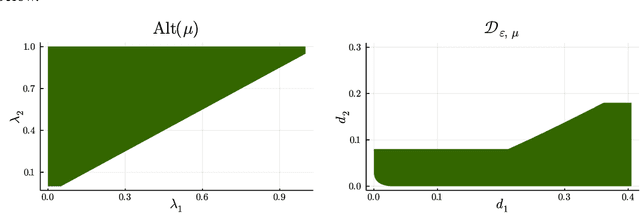
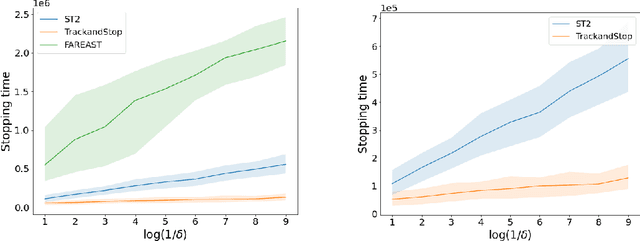
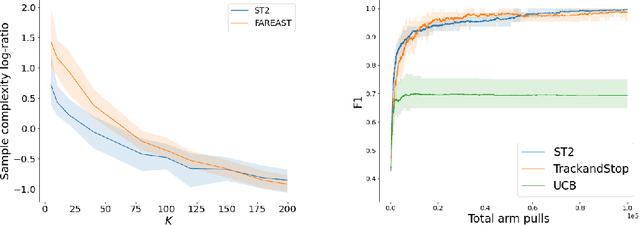
We consider the problem introduced by \cite{Mason2020} of identifying all the $\varepsilon$-optimal arms in a finite stochastic multi-armed bandit with Gaussian rewards. In the fixed confidence setting, we give a lower bound on the number of samples required by any algorithm that returns the set of $\varepsilon$-good arms with a failure probability less than some risk level $\delta$. This bound writes as $T_{\varepsilon}^*(\mu)\log(1/\delta)$, where $T_{\varepsilon}^*(\mu)$ is a characteristic time that depends on the vector of mean rewards $\mu$ and the accuracy parameter $\varepsilon$. We also provide an efficient numerical method to solve the convex max-min program that defines the characteristic time. Our method is based on a complete characterization of the alternative bandit instances that the optimal sampling strategy needs to rule out, thus making our bound tighter than the one provided by \cite{Mason2020}. Using this method, we propose a Track-and-Stop algorithm that identifies the set of $\varepsilon$-good arms w.h.p and enjoys asymptotic optimality (when $\delta$ goes to zero) in terms of the expected sample complexity. Finally, using numerical simulations, we demonstrate our algorithm's advantage over state-of-the-art methods, even for moderate values of the risk parameter.
A Non-asymptotic Approach to Best-Arm Identification for Gaussian Bandits
May 27, 2021



We propose a new strategy for best-arm identification with fixed confidence of Gaussian variables with bounded means and unit variance. This strategy called Exploration-Biased Sampling is not only asymptotically optimal: we also prove non-asymptotic bounds occurring with high probability. To the best of our knowledge, this is the first strategy with such guarantees. But the main advantage over other algorithms like Track-and-Stop is an improved behavior regarding exploration: Exploration-Biased Sampling is slightly biased in favor of exploration in a subtle but natural way that makes it more stable and interpretable. These improvements are allowed by a new analysis of the sample complexity optimization problem, which yields a faster numerical resolution scheme and several quantitative regularity results that we believe of high independent interest.
Best Arm Identification in Spectral Bandits
May 20, 2020
We study best-arm identification with fixed confidence in bandit models with graph smoothness constraint. We provide and analyze an efficient gradient ascent algorithm to compute the sample complexity of this problem as a solution of a non-smooth max-min problem (providing in passing a simplified analysis for the unconstrained case). Building on this algorithm, we propose an asymptotically optimal strategy. We furthermore illustrate by numerical experiments both the strategy's efficiency and the impact of the smoothness constraint on the sample complexity. Best Arm Identification (BAI) is an important challenge in many applications ranging from parameter tuning to clinical trials. It is now very well understood in vanilla bandit models, but real-world problems typically involve some dependency between arms that requires more involved models. Assuming a graph structure on the arms is an elegant practical way to encompass this phenomenon, but this had been done so far only for regret minimization. Addressing BAI with graph constraints involves delicate optimization problems for which the present paper offers a solution.