 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWe Should at Least Be Able to Design Molecules That Dock Well
Jul 01, 2020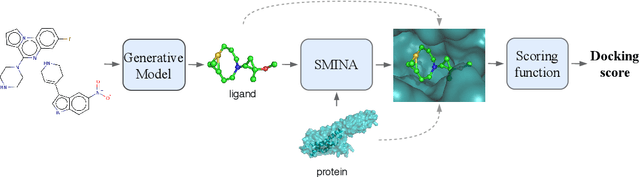
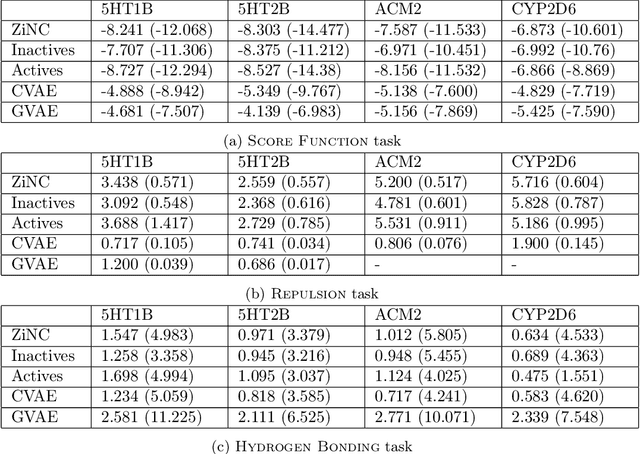

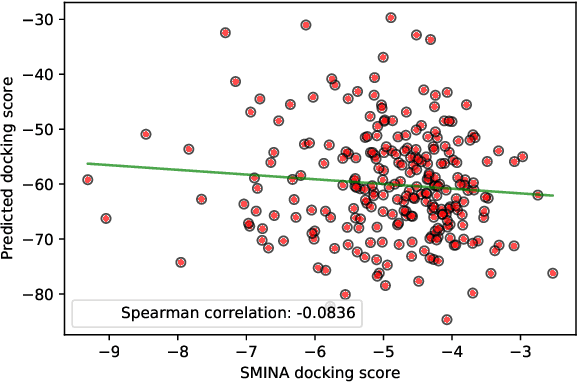
Designing compounds with desired properties is a key element of the drug discovery process. However, measuring progress in the field has been challenging due to the lack of realistic retrospective benchmarks, and the large cost of prospective validation. To close this gap, we propose a benchmark based on docking, a popular computational method for assessing molecule binding to a protein. Concretely, the goal is to generate drug-like molecules that are scored highly by SMINA, a popular docking software. We observe that popular graph-based generative models fail to generate molecules with a high docking score when trained using a realistically sized training set. This suggests a limitation of the current incarnation of models for de novo drug design. Finally, we propose a simplified version of the benchmark based on a simpler scoring function, and show that the tested models are able to partially solve it. We release the benchmark as an easy to use package available at https://github.com/cieplinski-tobiasz/smina-docking-benchmark. We hope that our benchmark will serve as a stepping stone towards the goal of automatically generating promising drug candidates.