 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE Routing Testbed: Studying Expert Specialization and Routing Behavior at Small Scale
Apr 08, 2026Sparse Mixture-of-Experts (MoE) architectures are increasingly popular for frontier large language models (LLM) but they introduce training challenges due to routing complexity. Fully leveraging parameters of an MoE model requires all experts to be well-trained and to specialize in non-redundant ways. Assessing this, however, is complicated due to lack of established metrics and, importantly, many routing techniques exhibit similar performance at smaller sizes, which is often not reflective of their behavior at large scale. To address this challenge, we propose the MoE Routing Testbed, a setup that gives clearer visibility into routing dynamics at small scale while using realistic data. The testbed pairs a data mix with clearly distinguishable domains with a reference router that prescribes ideal routing based on these domains, providing a well-defined upper bound for comparison. This enables quantifiable measurement of expert specialization. To demonstrate the value of the testbed, we compare various MoE routing approaches and show that balancing scope is the crucial factor that allows specialization while maintaining high expert utilization. We confirm that this observation generalizes to models 35x larger.
Recipes for Sequential Pre-training of Multilingual Encoder and Seq2Seq Models
Jun 14, 2023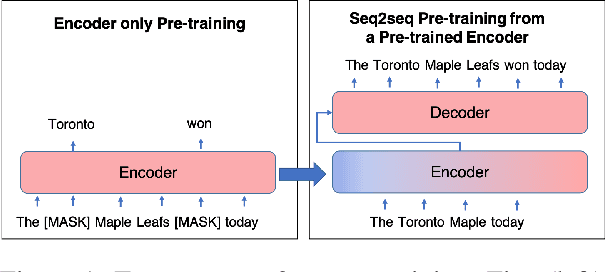
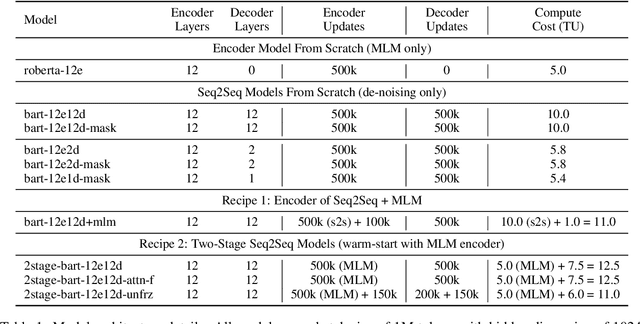
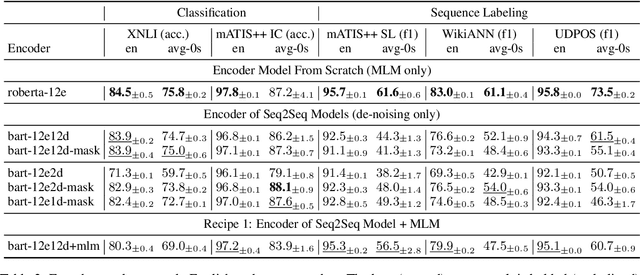
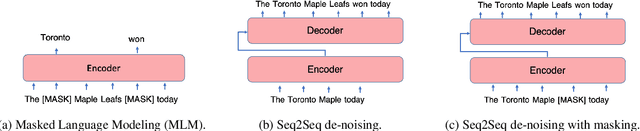
Pre-trained encoder-only and sequence-to-sequence (seq2seq) models each have advantages, however training both model types from scratch is computationally expensive. We explore recipes to improve pre-training efficiency by initializing one model from the other. (1) Extracting the encoder from a seq2seq model, we show it under-performs a Masked Language Modeling (MLM) encoder, particularly on sequence labeling tasks. Variations of masking during seq2seq training, reducing the decoder size, and continuing with a small amount of MLM training do not close the gap. (2) Conversely, using an encoder to warm-start seq2seq training, we show that by unfreezing the encoder partway through training, we can match task performance of a from-scratch seq2seq model. Overall, this two-stage approach is an efficient recipe to obtain both a multilingual encoder and a seq2seq model, matching the performance of training each model from scratch while reducing the total compute cost by 27%.