 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Meta Reinforcement Learning with Provable Test-Time Safety
Jan 29, 2026Meta reinforcement learning (RL) allows agents to leverage experience across a distribution of tasks on which the agent can train at will, enabling faster learning of optimal policies on new test tasks. Despite its success in improving sample complexity on test tasks, many real-world applications, such as robotics and healthcare, impose safety constraints during testing. Constrained meta RL provides a promising framework for integrating safety into meta RL. An open question in constrained meta RL is how to ensure the safety of the policy on the real-world test task, while reducing the sample complexity and thus, enabling faster learning of optimal policies. To address this gap, we propose an algorithm that refines policies learned during training, with provable safety and sample complexity guarantees for learning a near optimal policy on the test tasks. We further derive a matching lower bound, showing that this sample complexity is tight.
A learning-based approach to stochastic optimal control under reach-avoid constraint
Dec 21, 2024We develop a model-free approach to optimally control stochastic, Markovian systems subject to a reach-avoid constraint. Specifically, the state trajectory must remain within a safe set while reaching a target set within a finite time horizon. Due to the time-dependent nature of these constraints, we show that, in general, the optimal policy for this constrained stochastic control problem is non-Markovian, which increases the computational complexity. To address this challenge, we apply the state-augmentation technique from arXiv:2402.19360, reformulating the problem as a constrained Markov decision process (CMDP) on an extended state space. This transformation allows us to search for a Markovian policy, avoiding the complexity of non-Markovian policies. To learn the optimal policy without a system model, and using only trajectory data, we develop a log-barrier policy gradient approach. We prove that under suitable assumptions, the policy parameters converge to the optimal parameters, while ensuring that the system trajectories satisfy the stochastic reach-avoid constraint with high probability.
Convergence of a model-free entropy-regularized inverse reinforcement learning algorithm
Mar 25, 2024Given a dataset of expert demonstrations, inverse reinforcement learning (IRL) aims to recover a reward for which the expert is optimal. This work proposes a model-free algorithm to solve entropy-regularized IRL problem. In particular, we employ a stochastic gradient descent update for the reward and a stochastic soft policy iteration update for the policy. Assuming access to a generative model, we prove that our algorithm is guaranteed to recover a reward for which the expert is $\varepsilon$-optimal using $\mathcal{O}(1/\varepsilon^{2})$ samples of the Markov decision process (MDP). Furthermore, with $\mathcal{O}(1/\varepsilon^{4})$ samples we prove that the optimal policy corresponding to the recovered reward is $\varepsilon$-close to the expert policy in total variation distance.
Interior Point Constrained Reinforcement Learning with Global Convergence Guarantees
Dec 01, 2023


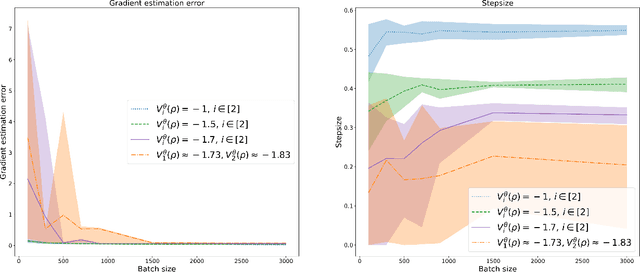
We consider discounted infinite horizon constrained Markov decision processes (CMDPs) where the goal is to find an optimal policy that maximizes the expected cumulative reward subject to expected cumulative constraints. Motivated by the application of CMDPs in online learning of safety-critical systems, we focus on developing an algorithm that ensures constraint satisfaction during learning. To this end, we develop a zeroth-order interior point approach based on the log barrier function of the CMDP. Under the commonly assumed conditions of Fisher non-degeneracy and bounded transfer error of the policy parameterization, we establish the theoretical properties of the algorithm. In particular, in contrast to existing CMDP approaches that ensure policy feasibility only upon convergence, our algorithm guarantees feasibility of the policies during the learning process and converges to the optimal policy with a sample complexity of $O(\varepsilon^{-6})$. In comparison to the state-of-the-art policy gradient-based algorithm, C-NPG-PDA, our algorithm requires an additional $O(\varepsilon^{-2})$ samples to ensure policy feasibility during learning with same Fisher-non-degenerate parameterization.