 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Concrete Visual Tokens for Multimodal Machine Translation
Mar 05, 2024

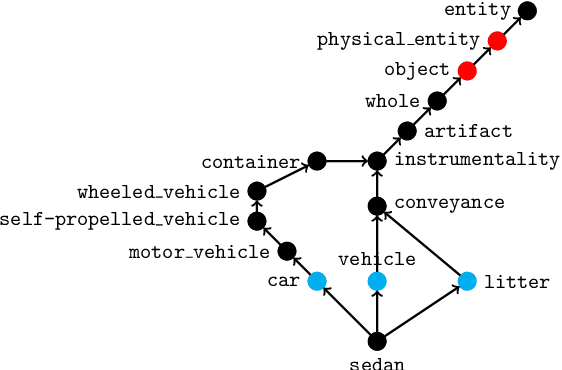

The challenge of visual grounding and masking in multimodal machine translation (MMT) systems has encouraged varying approaches to the detection and selection of visually-grounded text tokens for masking. We introduce new methods for detection of visually and contextually relevant (concrete) tokens from source sentences, including detection with natural language processing (NLP), detection with object detection, and a joint detection-verification technique. We also introduce new methods for selection of detected tokens, including shortest $n$ tokens, longest $n$ tokens, and all detected concrete tokens. We utilize the GRAM MMT architecture to train models against synthetically collated multimodal datasets of source images with masked sentences, showing performance improvements and improved usage of visual context during translation tasks over the baseline model.
The Case for Evaluating Multimodal Translation Models on Text Datasets
Mar 05, 2024
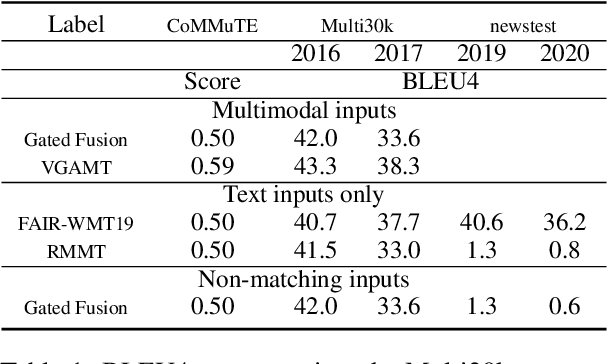
A good evaluation framework should evaluate multimodal machine translation (MMT) models by measuring 1) their use of visual information to aid in the translation task and 2) their ability to translate complex sentences such as done for text-only machine translation. However, most current work in MMT is evaluated against the Multi30k testing sets, which do not measure these properties. Namely, the use of visual information by the MMT model cannot be shown directly from the Multi30k test set results and the sentences in Multi30k are are image captions, i.e., short, descriptive sentences, as opposed to complex sentences that typical text-only machine translation models are evaluated against. Therefore, we propose that MMT models be evaluated using 1) the CoMMuTE evaluation framework, which measures the use of visual information by MMT models, 2) the text-only WMT news translation task test sets, which evaluates translation performance against complex sentences, and 3) the Multi30k test sets, for measuring MMT model performance against a real MMT dataset. Finally, we evaluate recent MMT models trained solely against the Multi30k dataset against our proposed evaluation framework and demonstrate the dramatic drop performance against text-only testing sets compared to recent text-only MT models.
Adding Multimodal Capabilities to a Text-only Translation Model
Mar 05, 2024
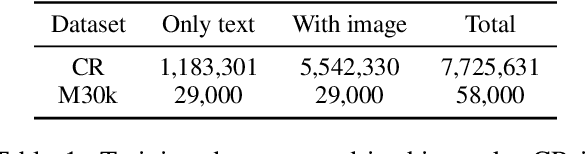


While most current work in multimodal machine translation (MMT) uses the Multi30k dataset for training and evaluation, we find that the resulting models overfit to the Multi30k dataset to an extreme degree. Consequently, these models perform very badly when evaluated against typical text-only testing sets such as the WMT newstest datasets. In order to perform well on both Multi30k and typical text-only datasets, we use a performant text-only machine translation (MT) model as the starting point of our MMT model. We add vision-text adapter layers connected via gating mechanisms to the MT model, and incrementally transform the MT model into an MMT model by 1) pre-training using vision-based masking of the source text and 2) fine-tuning on Multi30k.