 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Case for Evaluating Multimodal Translation Models on Text Datasets
Paper and Code
Mar 05, 2024
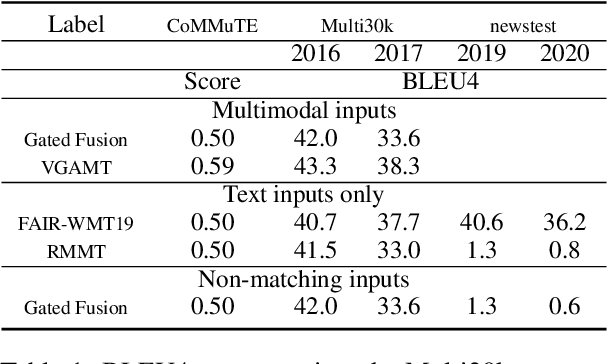
A good evaluation framework should evaluate multimodal machine translation (MMT) models by measuring 1) their use of visual information to aid in the translation task and 2) their ability to translate complex sentences such as done for text-only machine translation. However, most current work in MMT is evaluated against the Multi30k testing sets, which do not measure these properties. Namely, the use of visual information by the MMT model cannot be shown directly from the Multi30k test set results and the sentences in Multi30k are are image captions, i.e., short, descriptive sentences, as opposed to complex sentences that typical text-only machine translation models are evaluated against. Therefore, we propose that MMT models be evaluated using 1) the CoMMuTE evaluation framework, which measures the use of visual information by MMT models, 2) the text-only WMT news translation task test sets, which evaluates translation performance against complex sentences, and 3) the Multi30k test sets, for measuring MMT model performance against a real MMT dataset. Finally, we evaluate recent MMT models trained solely against the Multi30k dataset against our proposed evaluation framework and demonstrate the dramatic drop performance against text-only testing sets compared to recent text-only MT models.