 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuNER: Entity Recognition Encoder Pre-training via LLM-Annotated Data
Feb 23, 2024Large Language Models (LLMs) have shown impressive abilities in data annotation, opening the way for new approaches to solve classic NLP problems. In this paper, we show how to use LLMs to create NuNER, a compact language representation model specialized in the Named Entity Recognition (NER) task. NuNER can be fine-tuned to solve downstream NER problems in a data-efficient way, outperforming similar-sized foundation models in the few-shot regime and competing with much larger LLMs. We find that the size and entity-type diversity of the pre-training dataset are key to achieving good performance. We view NuNER as a member of the broader family of task-specific foundation models, recently unlocked by LLMs.
What Meaning-Form Correlation Has to Compose With
Dec 07, 2020
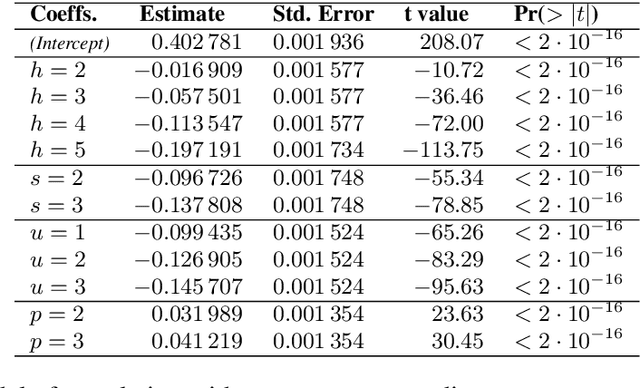

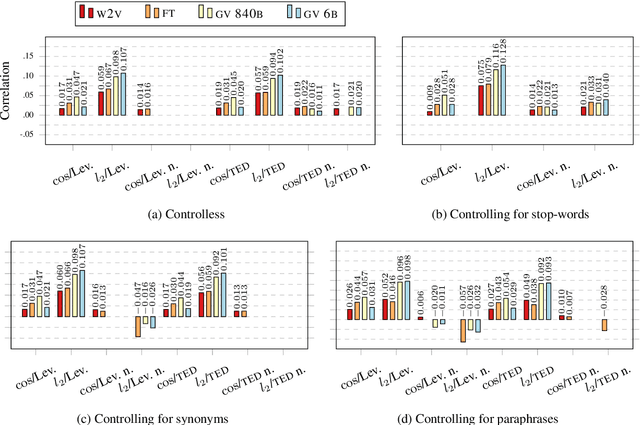
Compositionality is a widely discussed property of natural languages, although its exact definition has been elusive. We focus on the proposal that compositionality can be assessed by measuring meaning-form correlation. We analyze meaning-form correlation on three sets of languages: (i) artificial toy languages tailored to be compositional, (ii) a set of English dictionary definitions, and (iii) a set of English sentences drawn from literature. We find that linguistic phenomena such as synonymy and ungrounded stop-words weigh on MFC measurements, and that straightforward methods to mitigate their effects have widely varying results depending on the dataset they are applied to. Data and code are made publicly available.