 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntuitive Programming, Adaptive Task Planning, and Dynamic Role Allocation in Human-Robot Collaboration
Nov 11, 2025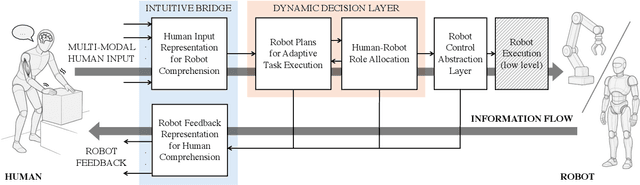
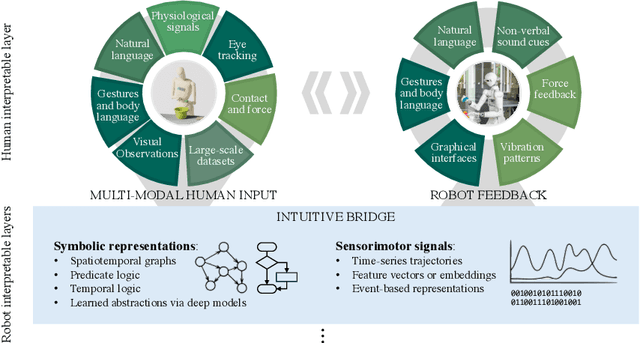
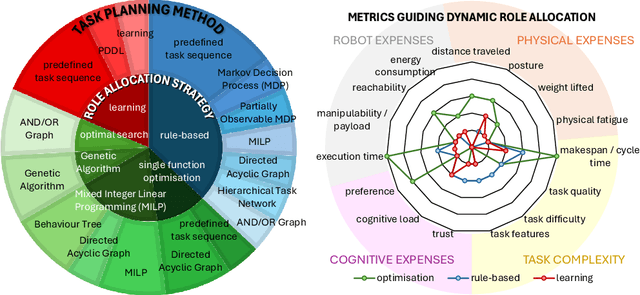
Remarkable capabilities have been achieved by robotics and AI, mastering complex tasks and environments. Yet, humans often remain passive observers, fascinated but uncertain how to engage. Robots, in turn, cannot reach their full potential in human-populated environments without effectively modeling human states and intentions and adapting their behavior. To achieve a synergistic human-robot collaboration (HRC), a continuous information flow should be established: humans must intuitively communicate instructions, share expertise, and express needs. In parallel, robots must clearly convey their internal state and forthcoming actions to keep users informed, comfortable, and in control. This review identifies and connects key components enabling intuitive information exchange and skill transfer between humans and robots. We examine the full interaction pipeline: from the human-to-robot communication bridge translating multimodal inputs into robot-understandable representations, through adaptive planning and role allocation, to the control layer and feedback mechanisms to close the loop. Finally, we highlight trends and promising directions toward more adaptive, accessible HRC.
* Published in the Annual Review of Control, Robotics, and Autonomous Systems, Volume 9; copyright 2026 the author(s), CC BY 4.0, https://www.annualreviews.org
AutoGPT+P: Affordance-based Task Planning with Large Language Models
Feb 16, 2024



Recent advances in task planning leverage Large Language Models (LLMs) to improve generalizability by combining such models with classical planning algorithms to address their inherent limitations in reasoning capabilities. However, these approaches face the challenge of dynamically capturing the initial state of the task planning problem. To alleviate this issue, we propose AutoGPT+P, a system that combines an affordance-based scene representation with a planning system. Affordances encompass the action possibilities of an agent on the environment and objects present in it. Thus, deriving the planning domain from an affordance-based scene representation allows symbolic planning with arbitrary objects. AutoGPT+P leverages this representation to derive and execute a plan for a task specified by the user in natural language. In addition to solving planning tasks under a closed-world assumption, AutoGPT+P can also handle planning with incomplete information, e. g., tasks with missing objects by exploring the scene, suggesting alternatives, or providing a partial plan. The affordance-based scene representation combines object detection with an automatically generated object-affordance-mapping using ChatGPT. The core planning tool extends existing work by automatically correcting semantic and syntactic errors. Our approach achieves a success rate of 98%, surpassing the current 81% success rate of the current state-of-the-art LLM-based planning method SayCan on the SayCan instruction set. Furthermore, we evaluated our approach on our newly created dataset with 150 scenarios covering a wide range of complex tasks with missing objects, achieving a success rate of 79% on our dataset. The dataset and the code are publicly available at https://git.h2t.iar.kit.edu/birr/autogpt-p-standalone.