 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Text Similarity based on Semantic Concept Embeddings
Jan 09, 2024Due to their ease of use and high accuracy, Word2Vec (W2V) word embeddings enjoy great success in the semantic representation of words, sentences, and whole documents as well as for semantic similarity estimation. However, they have the shortcoming that they are directly extracted from a surface representation, which does not adequately represent human thought processes and also performs poorly for highly ambiguous words. Therefore, we propose Semantic Concept Embeddings (CE) based on the MultiNet Semantic Network (SN) formalism, which addresses both shortcomings. The evaluation on a marketing target group distribution task showed that the accuracy of predicted target groups can be increased by combining traditional word embeddings with semantic CEs.
Complex Decomposition of the Negative Distance kernel
Jan 05, 2016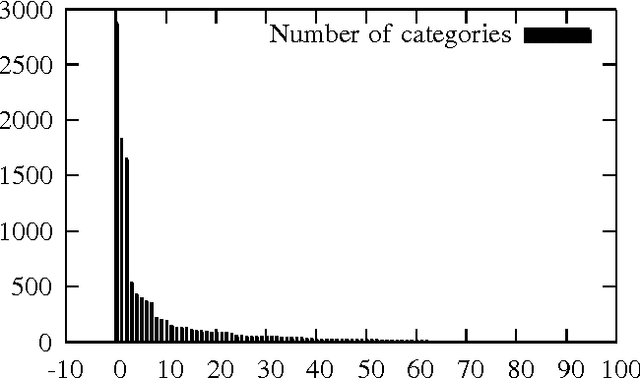
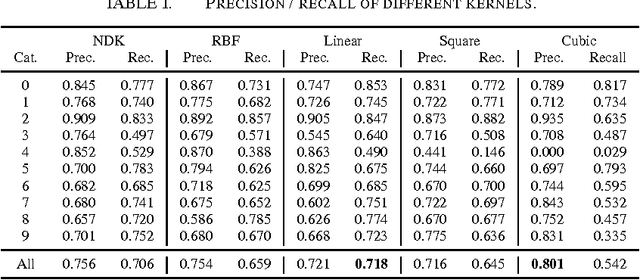
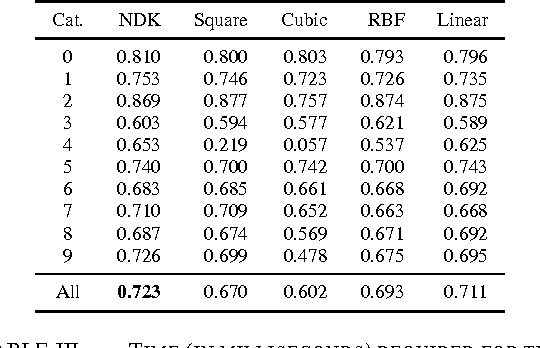

A Support Vector Machine (SVM) has become a very popular machine learning method for text classification. One reason for this relates to the range of existing kernels which allow for classifying data that is not linearly separable. The linear, polynomial and RBF (Gaussian Radial Basis Function) kernel are commonly used and serve as a basis of comparison in our study. We show how to derive the primal form of the quadratic Power Kernel (PK) -- also called the Negative Euclidean Distance Kernel (NDK) -- by means of complex numbers. We exemplify the NDK in the framework of text categorization using the Dewey Document Classification (DDC) as the target scheme. Our evaluation shows that the power kernel produces F-scores that are comparable to the reference kernels, but is -- except for the linear kernel -- faster to compute. Finally, we show how to extend the NDK-approach by including the Mahalanobis distance.