 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Trust in Dealing with LLM Hallucinations: A Qualitative Study
Dec 09, 2025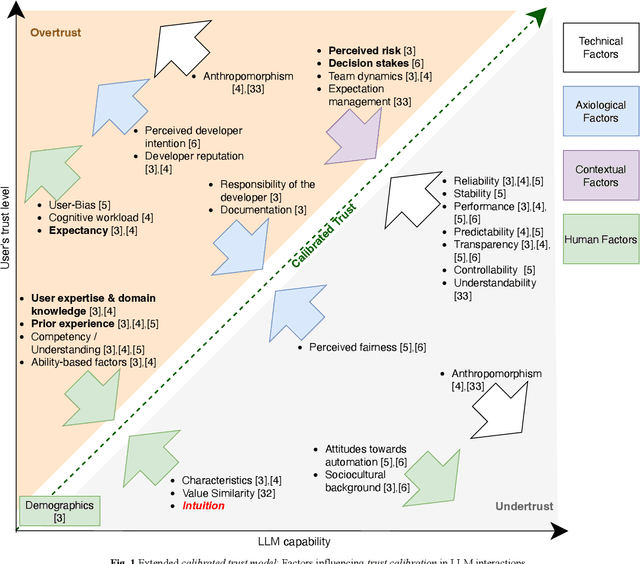
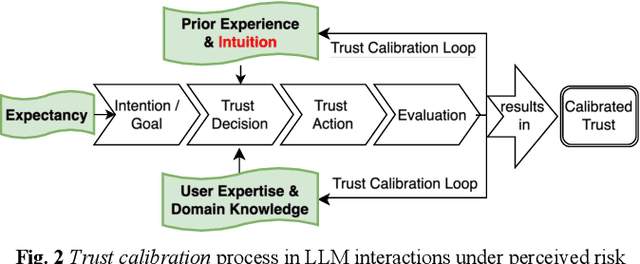
Hallucinations are outputs by Large Language Models (LLMs) that are factually incorrect yet appear plausible [1]. This paper investigates how such hallucinations influence users' trust in LLMs and users' interaction with LLMs. To explore this in everyday use, we conducted a qualitative study with 192 participants. Our findings show that hallucinations do not result in blanket mistrust but instead lead to context-sensitive trust calibration. Building on the calibrated trust model by Lee & See [2] and Afroogh et al.'s trust-related factors [3], we confirm expectancy [3], [4], prior experience [3], [4], [5], and user expertise & domain knowledge [3], [4] as userrelated (human) trust factors, and identify intuition as an additional factor relevant for hallucination detection. Additionally, we found that trust dynamics are further influenced by contextual factors, particularly perceived risk [3] and decision stakes [6]. Consequently, we validate the recursive trust calibration process proposed by Blöbaum [7] and extend it by including intuition as a user-related trust factor. Based on these insights, we propose practical recommendations for responsible and reflective LLM use.
A Comparison of Deep Learning Architectures for Spacecraft Anomaly Detection
Mar 19, 2024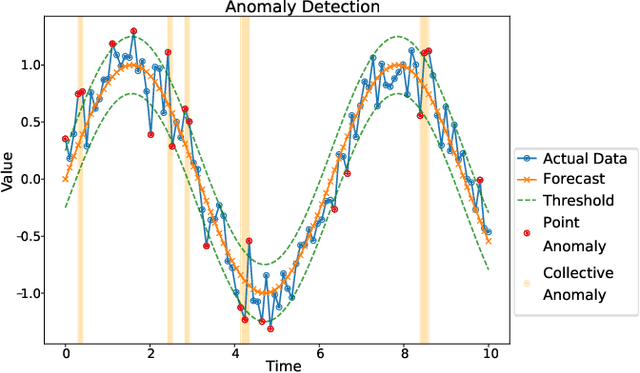

Spacecraft operations are highly critical, demanding impeccable reliability and safety. Ensuring the optimal performance of a spacecraft requires the early detection and mitigation of anomalies, which could otherwise result in unit or mission failures. With the advent of deep learning, a surge of interest has been seen in leveraging these sophisticated algorithms for anomaly detection in space operations. This study aims to compare the efficacy of various deep learning architectures in detecting anomalies in spacecraft data. The deep learning models under investigation include Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and Transformer-based architectures. Each of these models was trained and validated using a comprehensive dataset sourced from multiple spacecraft missions, encompassing diverse operational scenarios and anomaly types. Initial results indicate that while CNNs excel in identifying spatial patterns and may be effective for some classes of spacecraft data, LSTMs and RNNs show a marked proficiency in capturing temporal anomalies seen in time-series spacecraft telemetry. The Transformer-based architectures, given their ability to focus on both local and global contexts, have showcased promising results, especially in scenarios where anomalies are subtle and span over longer durations. Additionally, considerations such as computational efficiency, ease of deployment, and real-time processing capabilities were evaluated. While CNNs and LSTMs demonstrated a balance between accuracy and computational demands, Transformer architectures, though highly accurate, require significant computational resources. In conclusion, the choice of deep learning architecture for spacecraft anomaly detection is highly contingent on the nature of the data, the type of anomalies, and operational constraints.
Classification of Human- and AI-Generated Texts for English, French, German, and Spanish
Dec 08, 2023



In this paper we analyze features to classify human- and AI-generated text for English, French, German and Spanish and compare them across languages. We investigate two scenarios: (1) The detection of text generated by AI from scratch, and (2) the detection of text rephrased by AI. For training and testing the classifiers in this multilingual setting, we created a new text corpus covering 10 topics for each language. For the detection of AI-generated text, the combination of all proposed features performs best, indicating that our features are portable to other related languages: The F1-scores are close with 99% for Spanish, 98% for English, 97% for German and 95% for French. For the detection of AI-rephrased text, the systems with all features outperform systems with other features in many cases, but using only document features performs best for German (72%) and Spanish (86%) and only text vector features leads to best results for English (78%).
Classification of Human- and AI-Generated Texts: Investigating Features for ChatGPT
Aug 10, 2023Recently, generative AIs like ChatGPT have become available to the wide public. These tools can for instance be used by students to generate essays or whole theses. But how does a teacher know whether a text is written by a student or an AI? In our work, we explore traditional and new features to (1) detect text generated by AI from scratch and (2) text rephrased by AI. Since we found that classification is more difficult when the AI has been instructed to create the text in a way that a human would not recognize that it was generated by an AI, we also investigate this more advanced case. For our experiments, we produced a new text corpus covering 10 school topics. Our best systems to classify basic and advanced human-generated/AI-generated texts have F1-scores of over 96%. Our best systems for classifying basic and advanced human-generated/AI-rephrased texts have F1-scores of more than 78%. The systems use a combination of perplexity, semantic, list lookup, error-based, readability, AI feedback, and text vector features. Our results show that the new features substantially help to improve the performance of many classifiers. Our best basic text rephrasing detection system even outperforms GPTZero by 183.8% relative in F1-score.
Exploring ChatGPT's Empathic Abilities
Aug 07, 2023



Empathy is often understood as the ability to share and understand another individual's state of mind or emotion. With the increasing use of chatbots in various domains, e.g., children seeking help with homework, individuals looking for medical advice, and people using the chatbot as a daily source of everyday companionship, the importance of empathy in human-computer interaction has become more apparent. Therefore, our study investigates the extent to which ChatGPT based on GPT-3.5 can exhibit empathetic responses and emotional expressions. We analyzed the following three aspects: (1) understanding and expressing emotions, (2) parallel emotional response, and (3) empathic personality. Thus, we not only evaluate ChatGPT on various empathy aspects and compare it with human behavior but also show a possible way to analyze the empathy of chatbots in general. Our results show, that in 91.7% of the cases, ChatGPT was able to correctly identify emotions and produces appropriate answers. In conversations, ChatGPT reacted with a parallel emotion in 70.7% of cases. The empathic capabilities of ChatGPT were evaluated using a set of five questionnaires covering different aspects of empathy. Even though the results indicate that the empathic abilities of ChatGPT are still below the average of healthy humans, the scores are better than those of people who have been diagnosed with Asperger syndrome / high-functioning autism.
LSH methods for data deduplication in a Wikipedia artificial dataset
Dec 10, 2021This paper illustrates locality sensitive hasing (LSH) models for the identification and removal of nearly redundant data in a text dataset. To evaluate the different models, we create an artificial dataset for data deduplication using English Wikipedia articles. Area-Under-Curve (AUC) over 0.9 were observed for most models, with the best model reaching 0.96. Deduplication enables more effective model training by preventing the model from learning a distribution that differs from the real one as a result of the repeated data.