 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFNetAR: Mixing Tokens with Autoregressive Fourier Transforms
Jul 22, 2021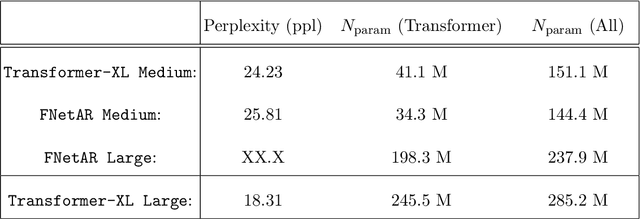
In this note we examine the autoregressive generalization of the FNet algorithm, in which self-attention layers from the standard Transformer architecture are substituted with a trivial sparse-uniformsampling procedure based on Fourier transforms. Using the Wikitext-103 benchmark, we demonstratethat FNetAR retains state-of-the-art performance (25.8 ppl) on the task of causal language modelingcompared to a Transformer-XL baseline (24.2 ppl) with only half the number self-attention layers,thus providing further evidence for the superfluity of deep neural networks with heavily compoundedattention mechanisms. The autoregressive Fourier transform could likely be used for parameterreduction on most Transformer-based time-series prediction models.