 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Data Augmentation via Example Extrapolation
Feb 02, 2021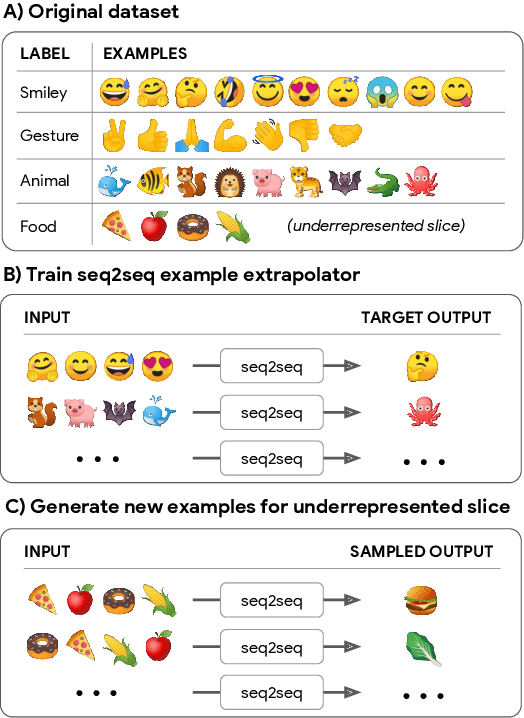


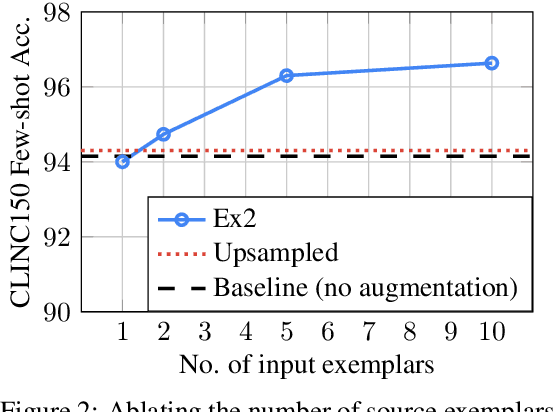
In many applications of machine learning, certain categories of examples may be underrepresented in the training data, causing systems to underperform on such "few-shot" cases at test time. A common remedy is to perform data augmentation, such as by duplicating underrepresented examples, or heuristically synthesizing new examples. But these remedies often fail to cover the full diversity and complexity of real examples. We propose a data augmentation approach that performs neural Example Extrapolation (Ex2). Given a handful of exemplars sampled from some distribution, Ex2 synthesizes new examples that also belong to the same distribution. The Ex2 model is learned by simulating the example generation procedure on data-rich slices of the data, and it is applied to underrepresented, few-shot slices. We apply Ex2 to a range of language understanding tasks and significantly improve over state-of-the-art methods on multiple few-shot learning benchmarks, including for relation extraction (FewRel) and intent classification + slot filling (SNIPS).