 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Structured State Space Models via Grouped FIR Filtering and Attention Sink Mechanisms
Aug 01, 2024Structured State Space Models (SSMs) have emerged as compelling alternatives to Transformer architectures, offering linear-time complexity and superior performance in various sequence modeling tasks. Despite their advantages, SSMs like the original Mamba-2 face training difficulties due to the sensitivities introduced by the extended series of recurrent matrix multiplications. In this paper, we propose an advanced architecture that mitigates these challenges by decomposing A-multiplications into multiple groups and optimizing positional encoding through Grouped Finite Impulse Response (FIR) filtering. This new structure, denoted as Grouped FIR-enhanced SSM (GFSSM), employs semiseparable matrices for efficient computation. Furthermore, inspired by the "attention sink" phenomenon identified in streaming language models, we incorporate a similar mechanism to enhance the stability and performance of our model over extended sequences. Our approach further bridges the gap between SSMs and Transformer architectures, offering a viable path forward for scalable and high-performing sequence modeling.
Few-Shot Image Classification and Segmentation as Visual Question Answering Using Vision-Language Models
Mar 15, 2024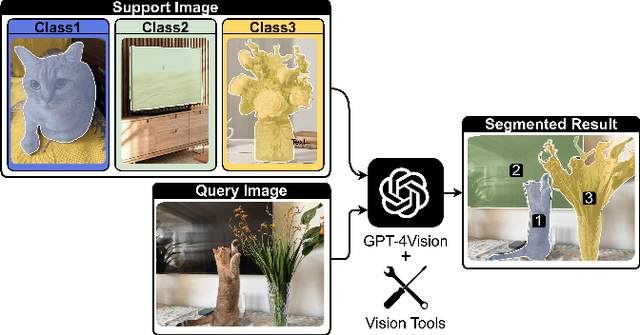
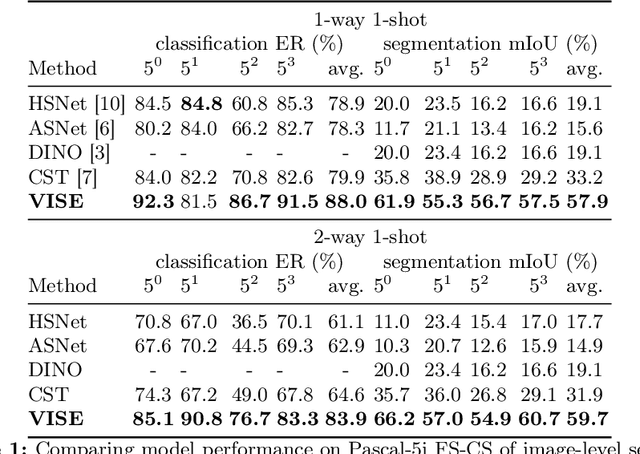
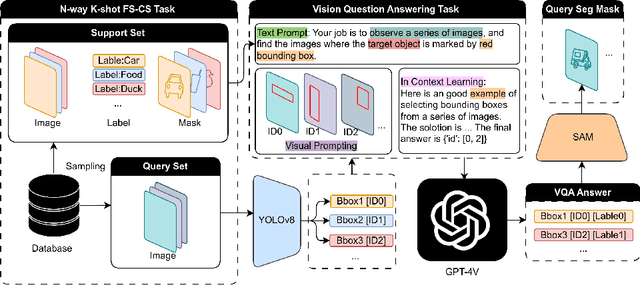
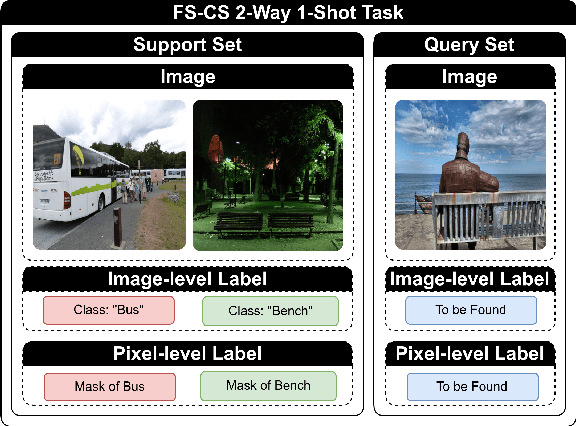
The task of few-shot image classification and segmentation (FS-CS) involves classifying and segmenting target objects in a query image, given only a few examples of the target classes. We introduce the Vision-Instructed Segmentation and Evaluation (VISE) method that transforms the FS-CS problem into the Visual Question Answering (VQA) problem, utilising Vision-Language Models (VLMs), and addresses it in a training-free manner. By enabling a VLM to interact with off-the-shelf vision models as tools, the proposed method is capable of classifying and segmenting target objects using only image-level labels. Specifically, chain-of-thought prompting and in-context learning guide the VLM to answer multiple-choice questions like a human; vision models such as YOLO and Segment Anything Model (SAM) assist the VLM in completing the task. The modular framework of the proposed method makes it easily extendable. Our approach achieves state-of-the-art performance on the Pascal-5i and COCO-20i datasets.
Few-Shot Classification & Segmentation Using Large Language Models Agent
Nov 19, 2023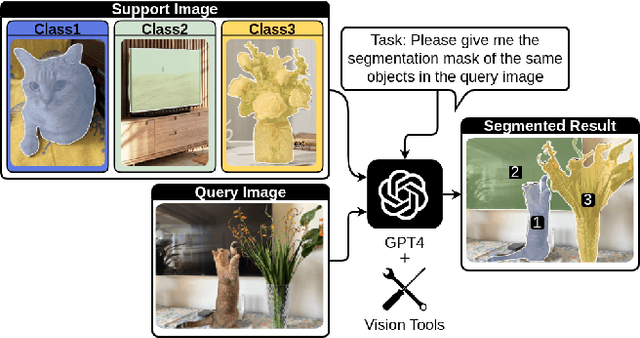
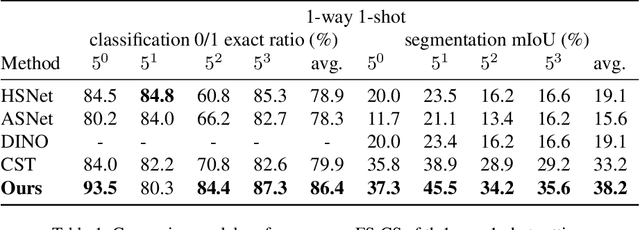
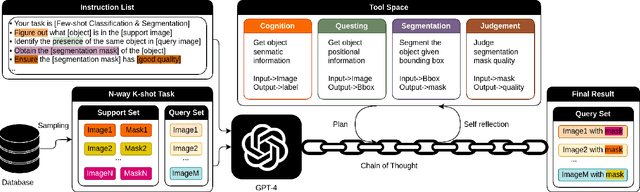

The task of few-shot image classification and segmentation (FS-CS) requires the classification and segmentation of target objects in a query image, given only a few examples of the target classes. We introduce a method that utilises large language models (LLM) as an agent to address the FS-CS problem in a training-free manner. By making the LLM the task planner and off-the-shelf vision models the tools, the proposed method is capable of classifying and segmenting target objects using only image-level labels. Specifically, chain-of-thought prompting and in-context learning guide the LLM to observe support images like human; vision models such as Segment Anything Model (SAM) and GPT-4Vision assist LLM understand spatial and semantic information at the same time. Ultimately, the LLM uses its summarizing and reasoning capabilities to classify and segment the query image. The proposed method's modular framework makes it easily extendable. Our approach achieves state-of-the-art performance on the Pascal-5i dataset.